
架构评审现场:那个被“记忆”卡住的 Agent
上周三下午,公司会议室的空气比提测前的服务器还要焦灼。

大佬一点头,大家都松了口气
面试官老王合上那份写满“精通 RAG、熟练使用 Pinecone”的简历,没问候选人向量数据库的 HNSW 索引原理,而是抛出了一个极其刁钻的真实场景:
图解用途:展示语义搜索的局限性,增强视觉冲击力

这话一出,问号先打满屏
“用户在对话中反复修改了三次需求,从‘要一个红色的按钮’变成‘蓝色的圆角矩形’,最后又改回‘红色的,但要带阴影’。

这一改,边界就开始漂了
你的 Agent 怎么在不重新扫描全量文档、不浪费 Token 的前提下,精准定位到他最后一次的有效决策,并且不被前两次的废弃指令干扰?”
候选人愣住了,下意识地回答:“我们可以把对话历史全部 Embedding 进向量库,然后做相似度检索……”
老王叹了口气,在评估表上划了个叉。如果你还在想怎么靠调 Embedding 接口解决所有问题,那说明你对 AI 后端的理解还停留在“搬砖”阶段。

先不聊了,我去搬砖
现在的顶尖 AI 岗位,考的不再是你会不会调包,而是你对“脑容量管理”的工程化能力。

Agent 突然失忆,像极了周一早上的我
这件事为什么和每个后端工程师有关?因为 AI 浪潮已经过了“尝鲜期”。
老板不再满足于一个会写诗的聊天机器人,他要的是能处理复杂业务逻辑、能记住用户偏好、能像熟练员工一样处理长流程任务的 Agent。
而这一切的核心,就在于一套能落地、抗得住高并发、且成本可控的“记忆架构”。
为什么简单的 RAG 正在失效?
很多刚入行的同学觉得,RAG(检索增强生成)就是万能药。只要把文档切片、向量化、存进数据库,Agent 就有了“知识”。
但在真实的工程现场,这种做法就像是给一个只有三秒钟记忆的人发了一本几万页的字典。他能查到单词,但他不知道刚才谁跟他说了话。
语义搜索存在天然的“模糊性”陷阱。当你搜索“那个红色的东西”时,向量库可能会给你召回一堆红色的汽车、红色的苹果,甚至是一个红色的报错日志,但它很难告诉你,用户在两分钟前明确否定了“红色”。
更致命的是成本红线。为了让 Agent 保持清醒,你不得不把大量的历史对话塞进 Context Window。
随着对话轮次的增加,Token 账单会像脱缰的野马一样狂奔,直到财务主管拍着桌子问你,为什么这个月的 API 费用比服务器租金还高。
三层架构:给大模型装上“冷热存储”
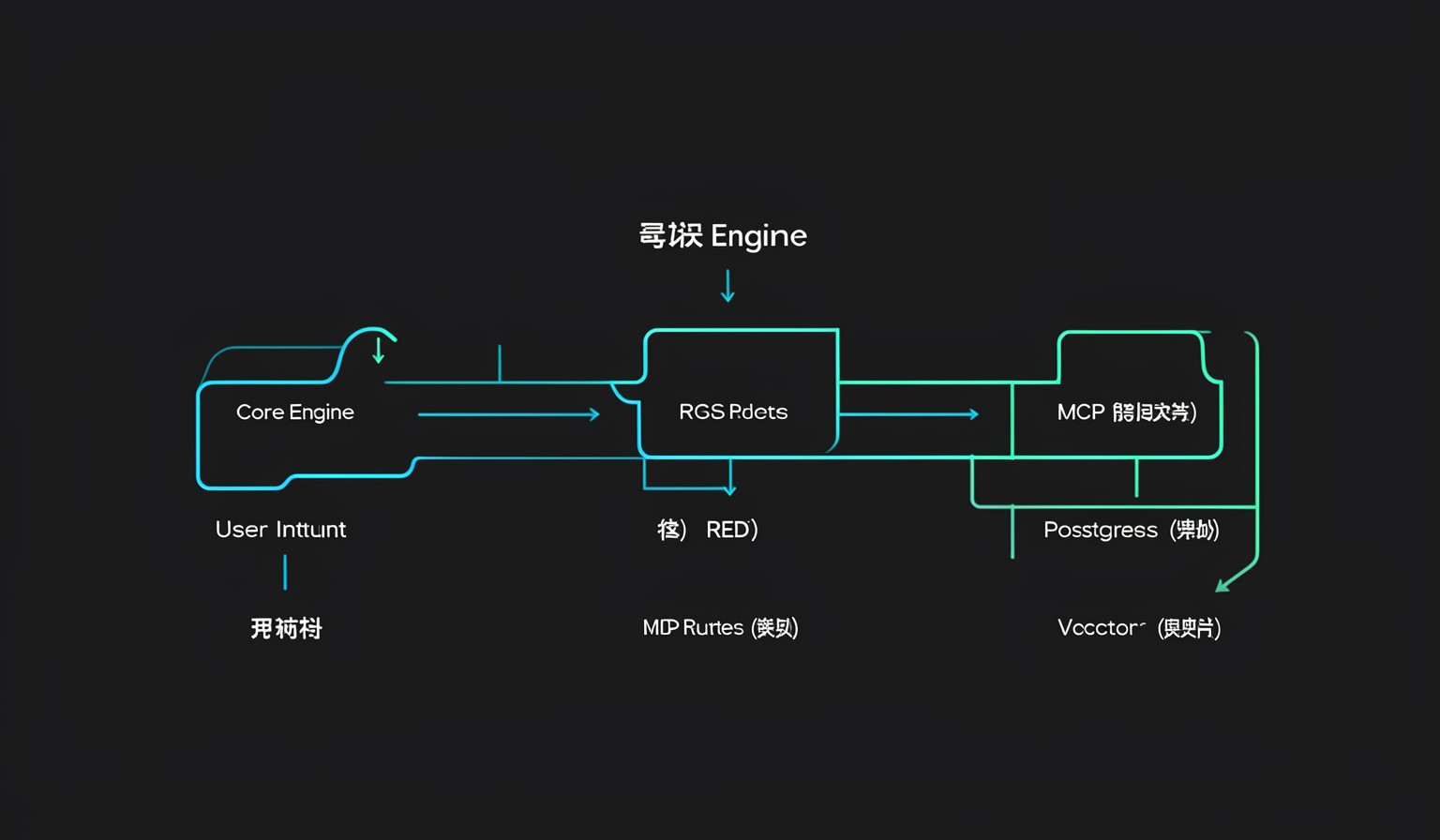
图解用途:引用 OpenClaw 核心交互图解,展示 MCP 路由逻辑
真正能落地的 Agent 架构,不会把所有筹码都压在向量库上。在 Reddit 的 MCP 社区里,大牛们已经达成了一个共识:你需要一套类似人类大脑的“三层存储架构”。
这不仅仅是技术选型,更是一种对数据生命周期的深度治理。
第一层:Redis 承载的“瞬时反应”
这一层对应人类的“工作记忆”。它存储的是 Session 级别的状态同步、当前的对话上下文以及 Agent 正在执行的任务栈。为什么必须是 Redis?
因为在流式输出(Streaming)的场景下,任何超过 50ms 的延迟都会让用户觉得这个 AI 变成了“树懒”。
Redis 不仅仅做缓存,它在这里充当了 Agent 的“草稿纸”。Agent 每一个中间思考步骤(Thought Process)都应该在这里快速读写。
如果没有这一层,你的 Agent 在处理并发请求时,极容易出现“张冠李戴”的逻辑混乱。

这架构图画出来,面试官眼神都变了
第二层:Postgres 里的“逻辑秩序”
这是很多纯 AI 开发者最容易忽略的一层:结构化元数据。向量数据库擅长处理“模糊”,但业务系统需要的是“精确”。
用户的 ID、订阅状态、最后一次操作的时间戳、已经确认的订单号——这些东西存进向量库简直是灾难。
在三层架构中,Postgres 负责存储“温数据”。通过 SQL 的强约束,我们可以轻松实现类似“查找用户过去 24 小时内所有已确认的修改指令”这样的操作。
这比在向量空间里捞针要可靠得多。记住,在 AI 时代,SQL 不仅没过时,反而因为其确定性,成为了 Agent 逻辑闭环的“压舱石”。
第三层:向量库里的“模糊联想”
最后才是向量数据库(Vector DB),它负责“冷数据”和“长效知识”。它的角色不再是决策者,而是“图书管理员”。
只有当第一层和第二层都找不到答案时,Agent 才会发起一次语义召回,去海量的历史语料中寻找可能的灵感或背景知识。
这种“召回而非决策”的思路转变,是区分初级和高级 AI 后端的关键。我们要的是语义补全,而不是让向量检索的结果直接左右业务逻辑。

重构记忆层,比重构前任的关系还难
MCP 协议:AI 时代的“驱动程序”统一战

图解用途:解释 MCP 作为“驱动程序”的角色
当存储变得复杂,连接就成了噩梦。你得写 Redis 的连接池,写 Postgres 的 CRUD,还得处理向量数据库的 API 适配。
这时候,Anthropic 祭出的 MCP(Model Context Protocol)协议就显现出了它的威力。
MCP 本质上是在给 Agent 统一“外挂接口”。以前,Agent 访问数据库像是在用不同的方言交流;现在,MCP 提供了一套标准化的“驱动程序”。
// 伪代码示例:一个典型的 MCP Memory Server 路由逻辑
async function handleMemoryRequest(query: string) {
// 1. 优先从 Redis 检索当前 Session 的热点状态
const hotState = await redis.get(currentSessionId);
if (isRelevant(hotState, query)) return hotState;
// 2. 穿透到 Postgres 查询结构化事实
const facts = await pg.query("SELECT * FROM user_facts WHERE user_id = $1", [userId]);
if (facts.rowCount > 0) return facts.rows;
// 3. 最后保底使用 Vector Search 做语义关联
const longTermMemory = await vectorStore.similaritySearch(query, 3);
return longTermMemory;
}
通过 MCP Server,你可以把这三层存储封装成一个标准的服务。
无论你换了什么模型(从 Claude 3.5 到 GPT-4o),只要它们支持 MCP,就能无缝继承这套“记忆体系”。
这对于后端工程师来说,意味着你从“写死逻辑的苦力”变成了“定义协议的架构师”。
写在最后:别在 AI 浪潮里做只会调包的“搬砖工”
现在的职场环境很残酷,但也很公平。只会写 CRUD 的传统后端在焦虑,只会调 OpenAI 接口的“AI 开发者”也在焦虑。真正的机会,留在那些能把复杂系统工程化的人手里。
我的判断很简单:未来的后端工程师,如果不懂如何构建 Stateful Agent(有状态的 Agent),那和只会写 HTML 静态页面的前端没有本质区别。
薪资的分水岭,不在于你背了多少大模型参数,而在于你能不能把 Redis 的快、Postgres 的准和向量库的广,有机地揉进一套 MCP 架构里。

懂了,这就去给 Agent 扩容脑容量
最后留个问题给大家:在你的实际项目中,有没有遇到过 Agent “一本正经胡说八道”,其实是因为它记错了某个关键事实?你是怎么修的?欢迎在评论区分享你的踩坑经验,我们一起复盘。
参考文献
Reddit Source: A Three-Layer Memory Architecture for LLMs (Redis + Postgres + Vector) MCP - 核心架构灵感来源
Anthropic Documentation: Model Context Protocol (MCP) Specification - 协议标准参考
OpenClaw Assets:
openclaw-core-interaction-flow.png- 交互回路图解引用
如果你想继续追更,欢迎在公众号 计算机魔术师 找到我。后续的新稿、精选合集和阶段性复盘,会优先在那里做串联。


