
2026 年 4 月,GTC 大会刚结束不到一个月,Jensen Huang 在财报电话会上抛出的两个数字,让很多还在算计显卡预算的工程师心里一沉。
一边是 Blackwell 和 Rubin 平台合计 1 万亿美元的订单积压,另一边却是 H20 芯片 45 亿美元的库存减记。
这组矛盾的数据,比任何架构参数都更直接地揭示了当下的行业现实:AI 基础设施建设的逻辑正在发生根本性断裂。
对于技术决策者而言,这不再仅仅是显卡性能的迭代问题,而是整个算力经济模型正在被重新计算。
这不仅仅是财务报表上的数字游戏。如果你所在的团队正在规划未来三年的算力储备,或者正在评估是否要押注某个特定的推理架构,这种“冰火两重天”的信号其实已经直接关联到了你的技术选型风险。
订单积压意味着需求依然狂热,但减记和地缘政治摩擦则意味着,过去那种“只要买得到就能赚钱”的粗放增长模式正在迅速失效。
从 Blackwell 到 Rubin:算力军备竞赛的下半场
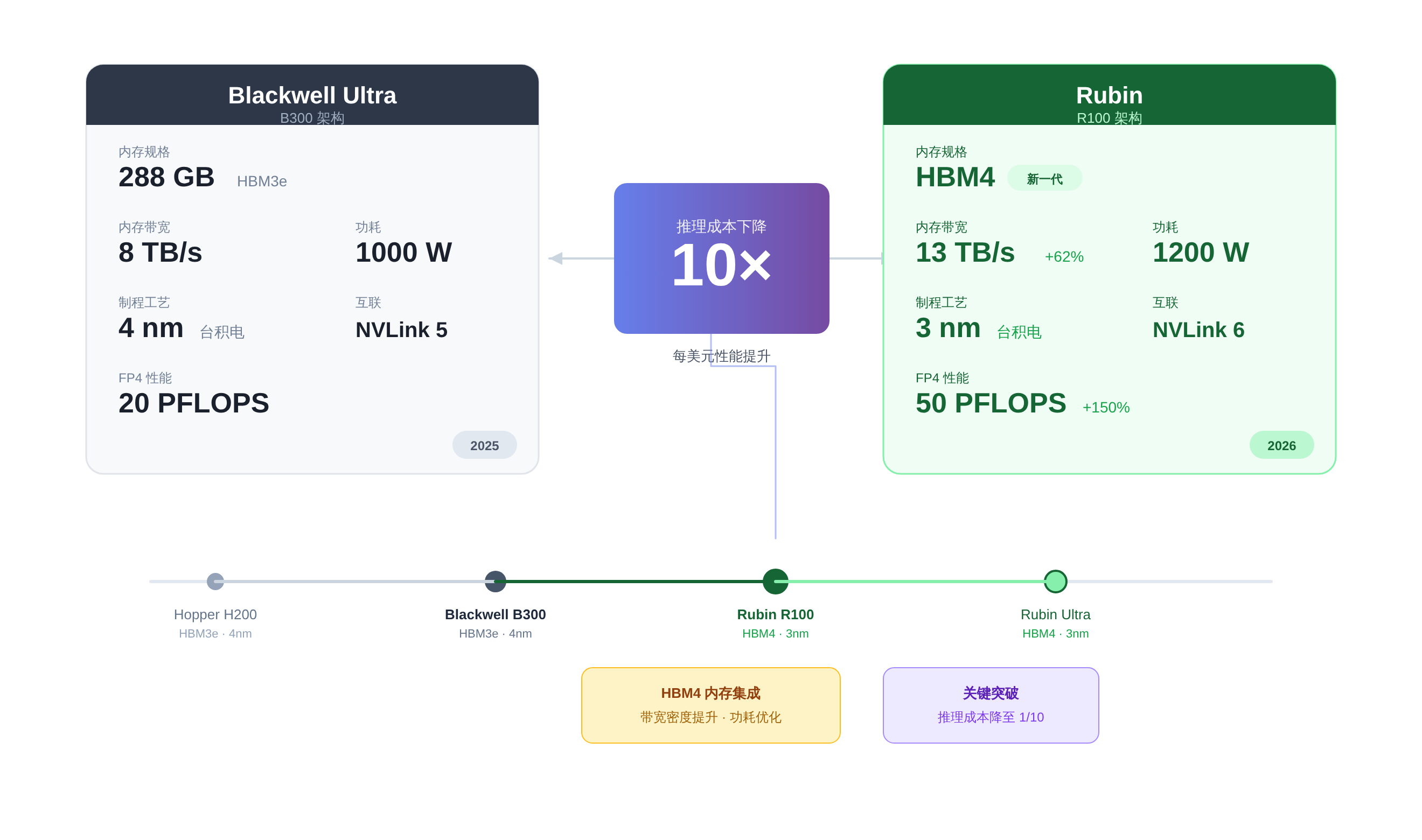
NVIDIA 的最新公告里,最硬的技术信号其实藏在 Rubin R100 的规格表里。这不仅仅是硬件升级,更是对算力经济学的一次重新定义。
Rubin R100 架构采用 TSMC 3nm 工艺,并首次集成 HBM4 内存,算力达到 50 PFLOPS。但比这些参数更重要的是其核心目标:将推理成本降低 10 倍 1。
这标志着行业重心从“训练大模型”向“大规模部署推理”的结构性转移。过去两年,大家都在卷训练算力,谁卡多谁有理;
现在,随着模型能力趋于稳定,如何把昂贵的模型变成廉价的公共服务,成了新的战场。
Blackwell Ultra (B300) 已经开始量产,配备 288GB HBM3e 内存,主要针对大规模推理工作负载 2。
这看起来是常规升级,但结合 NVIDIA 现在执行的“一年一架构”激进产品周期来看,压力就很大了。
这种节奏迫使企业客户必须加速硬件折旧,否则还没等集群跑热,下一代产品就已经让现有设备变成了“电子古董”。
对于技术决策者而言,这意味着采购策略必须从“买断”转向“订阅”或“租赁”思维。你买下的不再是长期资产,而是一张会快速贬值的算力入场券。

刚买的 H100 还没捂热,Rubin 就来了?
1 万亿美元订单背后的 ROI 审判
Wolfe Research 的分析师 Chris Caso 指出,Blackwell 与 Rubin 平台的 1 万亿美元订单仅是“下限”,而非上限,需求依然旺盛 3。
这听起来是个极度乐观的信号,仿佛 AI 的黄金时代才刚刚开始。
然而,FY2026 营收达 2159 亿美元、同比增长 65% 的背后,市场开始质疑 Hyperscaler 的 Capex 能否持续转化为利润 4。这种质疑并非空穴来风。
行业调查显示,2026 年初仅不到 1% 的企业高管表示 AI 投资带来了显著回报。ROI 缺口正在成为悬在所有技术项目负责人头顶的达摩克利斯之剑。
这种“订单爆满但回报存疑”的矛盾状态,正在改变工程师的工作环境。过去,搭建 GPU 集群本身就是一种成就;现在,你必须证明每一张卡的利用率都能转化为实际的业务价值。
Hyperscaler 们为了应对这种压力,开始疯狂自研芯片。
Google TPU v7 与 Amazon Trainium 3 在特定内部负载中已达到与 Blackwell 相当的性能,自研 ASIC 正在分流 NVIDIA 的高毛利业务 1。
这不仅是商业博弈,更是技术架构的分化。未来的云上架构将呈现“通用 GPU + 专用 ASIC”的混合形态。
如果你只懂 CUDA 优化,可能很快就会发现,最赚钱的那些工作负载已经跑在你看不见的定制芯片上了。

老板问 AI 投入产出比,我只能说还在调参
地缘政治与技术封锁的真实代价
NVIDIA 因美国出口管制收紧,对专供中国的 H20 系列芯片计提了 45 亿美元库存减记 [^1]。这不仅是财务报表上的一次性损失,更是市场份额的永久性让渡。
NVIDIA 在中国数据中心市场份额已从 95% 下滑至 55%,华为等本土厂商正在迅速填补空白 5。对于跨国项目团队而言,这是一个极其明确的信号:架构设计必须预留“合规冗余”。
过去那种依赖单一供应商、统一技术栈的方案,在地缘政治风险面前变得极其脆弱。你需要考虑的不仅仅是性能,还有供应链的连续性。
在企业客户之外,NVIDIA 正在积极推动“Sovereign AI”(主权 AI)战略,即国家主导的 AI 基础设施建设 5。
日本、法国、阿联酋等国正在投入数十亿美元建设本土 AI 云,这为 NVIDIA 开辟了独立于美国 Hyperscaler 的新增长极。
这对工程师意味着,未来的项目可能不再只是服务某个互联网大厂,而是要对接各种国家级数据主权要求。数据驻留、合规审计、本地化部署将成为新的技术硬约束。

架构不支持国产化适配?这锅你背
竞争格局:ASIC 与第二供应商的崛起
AMD MI400 系列预计占据约 12% 的加速器市场,ROCm 生态逐渐成熟,成为可行的第二供应商 [^1]。
对于追求供应链安全的团队,引入 AMD 作为备选方案已不再是性能妥协,而是风险对冲的必要手段。这意味着工程师需要开始熟悉 ROCm 生态,就像当年熟悉 CUDA 一样。
虽然迁移成本依然存在,但在“NVIDIA 税”越来越高的背景下,这种多生态适配能力将成为团队的核心竞争力之一。
与此同时,美国 DOJ 加大对 NVIDIA 反垄断调查力度,关注其软硬件捆绑销售行为 5。如果 CUDA 生态被迫开放,将显著降低迁移成本,为 AMD 和其他竞争者打开大门。
虽然诉讼过程漫长,但监管压力本身就是一种变量。对于正在做长期技术规划的人来说,押注单一封闭生态的风险正在上升。
与其被动等待监管结果,不如主动在技术栈中引入抽象层,为未来的迁移预留接口。

监管大刀砍向 CUDA,这画面太美不敢看
写在最后:工程师视角的信号解读
NVIDIA 的最新公告传递了三个明确信号:硬件迭代周期缩短、推理成本成为核心指标、地缘风险已计入产品成本。对于工程师而言,这意味着单纯依赖硬件性能堆叠的时代正在结束。
未来的竞争力将取决于如何在 ROI 压力下构建更高效的推理架构,并在多元化供应链中保持技术选型的灵活性。
这不再是那个只要拿到卡就能躺赢的时代了。你需要更精细地计算每一 TFLOPS 的成本效益,更敏锐地感知供应链的每一次波动,更务实地评估每一种技术路线的真实收益。
在这个充满不确定性的下半场,技术判断力本身,就是最好的护城河。
你的团队现在的算力储备策略,是继续押注 NVIDIA 的最新架构,还是已经开始布局多供应商方案?欢迎在评论区分享你的判断。
风险提示与免责声明:本文仅基于公开资料讨论公司公告、技术投入与行业信号,用于研究和信息分享,不构成投资建议,也不作为投资依据。
参考文献
Wolfe Research: Nvidia's $1T Orders Guidance Is a Floor, Not a Ceiling
FinancialContent - Beyond the Blackwell Peak: Nvidia Faces the "ROI Reckoning" of 2026
Nvidia: Ahead Of GTC 2026, Architectural Supremacy Beyond Hyperscaler CapEx FOMO
如果你想继续追更,欢迎在公众号 计算机魔术师 找到我。后续的新稿、精选合集和阶段性复盘,会优先在那里做串联。


