
一、先说我的判断:Agent 正在靠近自己的云计算时刻
1.1 单点 Agent 还没有到终局,但已经能看到瓶颈轮廓
这两天我一直在想一个问题:如果最强的单兵 Agent 已经越来越接近顶尖形态,下一轮真正的变化会发生在哪里?
先说事实:单点 Agent 的能力确实还在爬坡。OpenAI Codex 已经能端到端完成软件任务,读写代码、执行终端命令、理解项目结构[7]。Anthropic 的 Claude 在复杂推理上持续突破。但如果我们仔细观察,会发现一个有趣的反讽:越强大的单兵 Agent,越早碰到自己的天花板——上下文窗口。
不是模型能力不够,而是单点 Agent 不可能同时吃满 CTO/CPU/GPU 所有上下文。代码库在膨胀,对话历史在累积,工具调用在叠加,跨 session 的记忆需求在涌现。单点 Agent 的上下文饥饿问题,不是靠更大的 context window 能彻底解决的。这是一个结构性限制,而不是能力上限的问题。
1.2 从终端、桌面、手机到 IM,工具边界扩展的是入口,不只是能力
再看另一个趋势:工具边界在快速扩展。从 Codex CLI 的终端编程[8],到 IDE 里 Copilot 的实时补全,再到 IM 里集成的 AI 助手,AI 正在渗透进各种入口。这种扩展,我认为核心意义不是单点能力变强了,而是入口在分散。
过去用户要专门打开一个 AI 工具,现在是 AI 能力被嵌入到他本来就在用的场景里。这个变化像什么?我把它叫做 Agent 的云计算时刻。

这一段,面试官开始看你工程感了
回顾云计算的逻辑:最初计算能力也在单机上,后来通过虚拟化和 API 把能力抽离出来,变成按需调用的资源。Agent 现在的工具边界扩展,同样是在把 AI 能力从单一工具里抽离,分散到各种入口。但这只是上半场——云计算的核心不只是资源分散,而是资源可以协作。AWS 不会只给你一台虚拟机的能力,而是提供 S3、RDS、Lambda 这些可以组合的云服务。
Agent 的云计算时刻,最终也会走向协作层。多点协作、跨端持续记忆、任务看板、Agent-to-Agent 协议——这些会变成下一代基础设施的核心组件。现在才刚刚开始。
二、为什么多 Agent 之前没有真正火起来
但这里有个微妙的地方:多 Agent 协作听起来很美好,工程现实却在很长一段时间里给出了相反的答案。这不是技术方向错了,而是时机未到,复杂性先于收益。
当单兵 Agent 的能力还停在 50 分、60 分的阶段,把它复制成两个、三个,并不会产生 150 分的效果。更可能的情况是:每个 Agent 都在处理半吊子的问题,它们之间的协调成本反而成为新的瓶颈。
我见过不少团队在 2023 年左右尝试用多个 Agent 联合完成一个任务:规划 Agent、执行 Agent、验证 Agent、反思 Agent 分工明确,看起来很优雅。但跑起来之后发现,每个 Agent 的判断质量都不够高,导致大量的重复劳动和错误传递。最后团队选择退回单 Agent 方案,因为维护四个烂 Agent 的成本远高于打磨一个还算可以的 Agent。
这背后的核心矛盾是:当单兵能力不足时,多 Agent 只会放大系统性风险。多 Agent 的价值建立在每个 Agent 都有足够的能力完成自己那一摊事的基础上。如果单兵本身就是短板,协作只是在传播短板。
另一个被低估的问题是上下文腐化。
当一个 Agent 同时需要处理两个高密度上下文——比如一边做代码审查,一边做需求分析——这两个任务的上下文会相互挤占资源。模型在切换注意力时产生的推理偏移,最终导致两个任务的质量都下降。这就是为什么很多团队发现,让一个 Agent “多线程”处理不同任务,往往不如让它专注于单一任务来得稳定。
所以多 Agent 在过去几年始终停留在“理论上很美”的阶段。不是协议不够多,不是框架不够成熟,而是底座还不够扎实——单兵 Agent 的能力没有跨过那条让协作收益大于协调成本的线。
那条线在哪里?我认为就是单点能力接近 80% 的顶尖形态。
三、真正的多 Agent 协作需要哪些基础设施
3.1 A2A、ACP、MCP:协议层不是概念,而是连接方式
光有单点能力不够,多 Agent 之间需要“说同一种语言”,这才是协作的真正起点。
事实层面:Google 在 2025 年初发布了 A2A(Agent-to-Agent)协议 Specification,目标是让不同厂商、不同 runtime 的 Agent 能够互相发现、传递任务状态、共享上下文片段

A2A 协议让跨厂商 Agent 互操作成为可能
。Anthropic 在更早时间主导了 MCP(Model Context Protocol),标准化了 LLM 与工具、数据源之间的接口契约。这两套协议代表了两个方向:A2A 管 Agent 之间的横向通信,MCP 管 Agent 与外部资源的纵向集成。
趋势层面:MCP 已经被 Cursor、Claude Desktop 等产品直接集成,生态效应正在形成。而 A2A 还处于早期,主流 Agent 产品大多还停留在“通过 Prompt engineering 模拟协作”阶段。我个人判断,A2A 的落地速度会慢于 MCP,因为协议制定容易,落地需要厂商之间达成信任和利益共识。
推演:如果 A2A 能进入稳定期,未来的 Agent 系统会像微服务一样:一个 Agent 负责代码执行,一个负责信息检索,一个负责用户界面编排,它们通过协议而非共享上下文通信。这比把所有能力塞进一个模型上下文窗口更合理,因为单兵 Agent 不可能同时吃满 CTO/CPU 等所有上下文。
从 MCP 到 A2A,协议层正在从工具集成走向 Agent 互操作
3.2 任务看板、跨 session memory、workspace 文件,是协作的现实载体
协议定义了连接方式,但真正让多 Agent 可用的,是协作过程中的状态管理和持久化机制。
事实层面:OpenAI Codex 的 system card 描述了云端执行任务的完整生命周期:接收指令、拆解任务、执行子步骤、返回结果。NousResearch 的 Hermes Agent 则在 ACP 模式下暴露了 session 生命周期和 JSON-RPC 接口,支持跨客户端的 agent 访问。这些都是“任务即状态”的具体实现。
趋势层面:现在的单点 Agent 大多是 session 隔离的——你关掉对话窗口,历史上下文就丢了。但协作场景要求 Agent 能够跨 session 保留记忆,能够指向同一个 workspace 里的文件,能够理解“上一轮谁做了什么、现在轮到谁”。任务看板的价值就在这里:它把多 Agent 协作从“一次对话”变成“持续项目管理”。
推演:我倾向于认为,跨 session memory 会先在同类工具(比如同生态的编码 Agent)内部实现,然后逐步延伸到跨生态场景。workspace 文件模式会成为事实上的共享载体,因为它足够简单、足够通用。
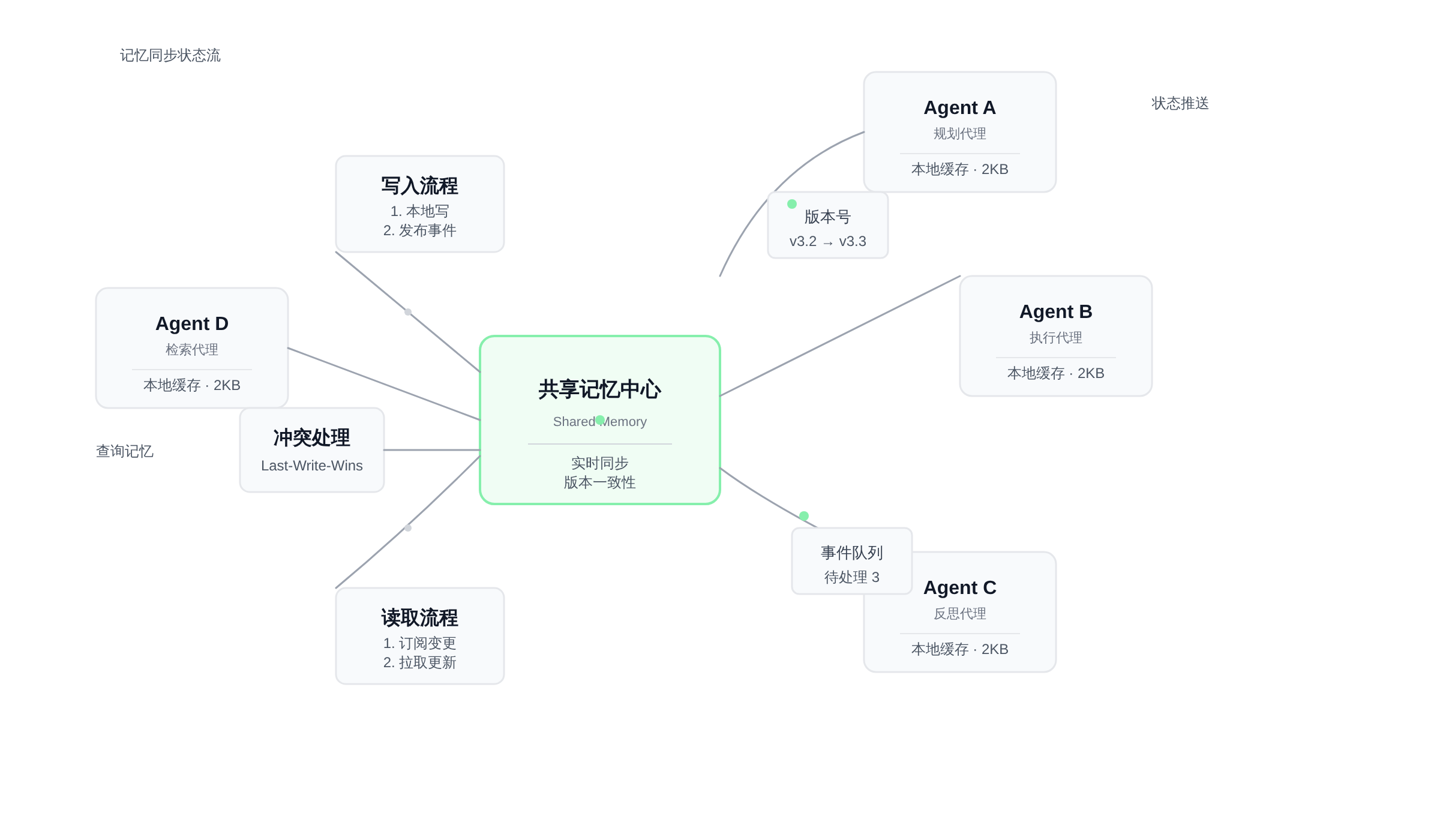
多 Agent 协作中的记忆同步机制
3.3 权限、日志、可观测和终止条件,决定它能不能长期运行
协作系统最大的风险不是“跑不起来”,而是“跑起来之后失控”。
事实层面:MCP 的设计模式论文识别了生产环境中的典型失败模式:契约漂移(接口变更导致 agent 调用失败)、用户上下文丢失(session 断开后状态不恢复)、超时和错误处理不统一、observability 缺失。这四个问题在任何多 Agent 系统里都会出现,因为协作链路越长,故障点就越多。
趋势层面:现在大多数单点 Agent 对错误处理是“简单重试”或“返回失败”,但多 Agent 场景需要更细粒度的策略:某个子任务超时应该回滚还是继续?权限不足应该降级还是中断?日志应该保留多少个版本?终止条件是什么?这些在单点场景下几乎不需要回答,在多 Agent 场景下却是系统能否长期运行的关键。
推演:我认为,未来会有一类新型中间件,专门负责多 Agent 系统的 orchestrator 能力:权限校验、调用链路日志、异常状态回滚、可配置的终止策略。这类中间件可能是开源的(比如类似 Temporal 的工作流引擎),也可能是云厂商提供的托管服务。
四、为什么我认为本地化和私有化会变重要
到这里,我已经说了单点 Agent 的瓶颈、多 Agent 协作为什么之前没火、以及协作需要哪些基础设施。接下来我想聊聊另一个我认为是必然的方向:本地化和私有化。
4.1 生活、工作和长期记忆都天然包含隐私
很多人谈 AI 落地,第一反应是“上云”,好像只有云端才能承载足够强的模型能力。但如果我们认真想想普通用户的生活场景,这个判断就会动摇。
你每天的聊天记录是不是隐私?家庭账本、健康检查结果、孩子的成长记录、工作的邮件和文档,这些东西天然包含敏感信息。用户本能上不愿意把它们上传给第三方模型服务商——这不只是技术问题,是信任问题。
隐私边界决定了哪些数据该留在本地
现在单点 Agent 在桌面端、移动端的入口扩展,本质上也在回应这个问题。用户的上下文不完全属于云端 API 的调用配额,它属于用户自己。跨 session 的记忆如果要在多端之间保持一致,本地化的存储和同步是绕不开的一环。
我判断,未来会出现以本地为核心的 Agent 架构:模型推理可以在云端,但你的记忆、你的工具、你的权限控制,都发生在你自己控制的设备和账户体系里。这不是倒退,这是隐私保护意识的成熟。
4.2 Agent 不一定适合三高系统,本地私有团队反而有可行性
再往上看企业场景。这里有一个反直觉的事实:通用 Agent 不一定适合高可用、高并发、高一致性要求的系统。金融交易引擎、医疗诊断流水线、实时控制系统,这些场景对延迟、稳定性和合规有严格要求。云端 Agent 在这些领域天然有局限性——不是能力不够,是架构不适合。
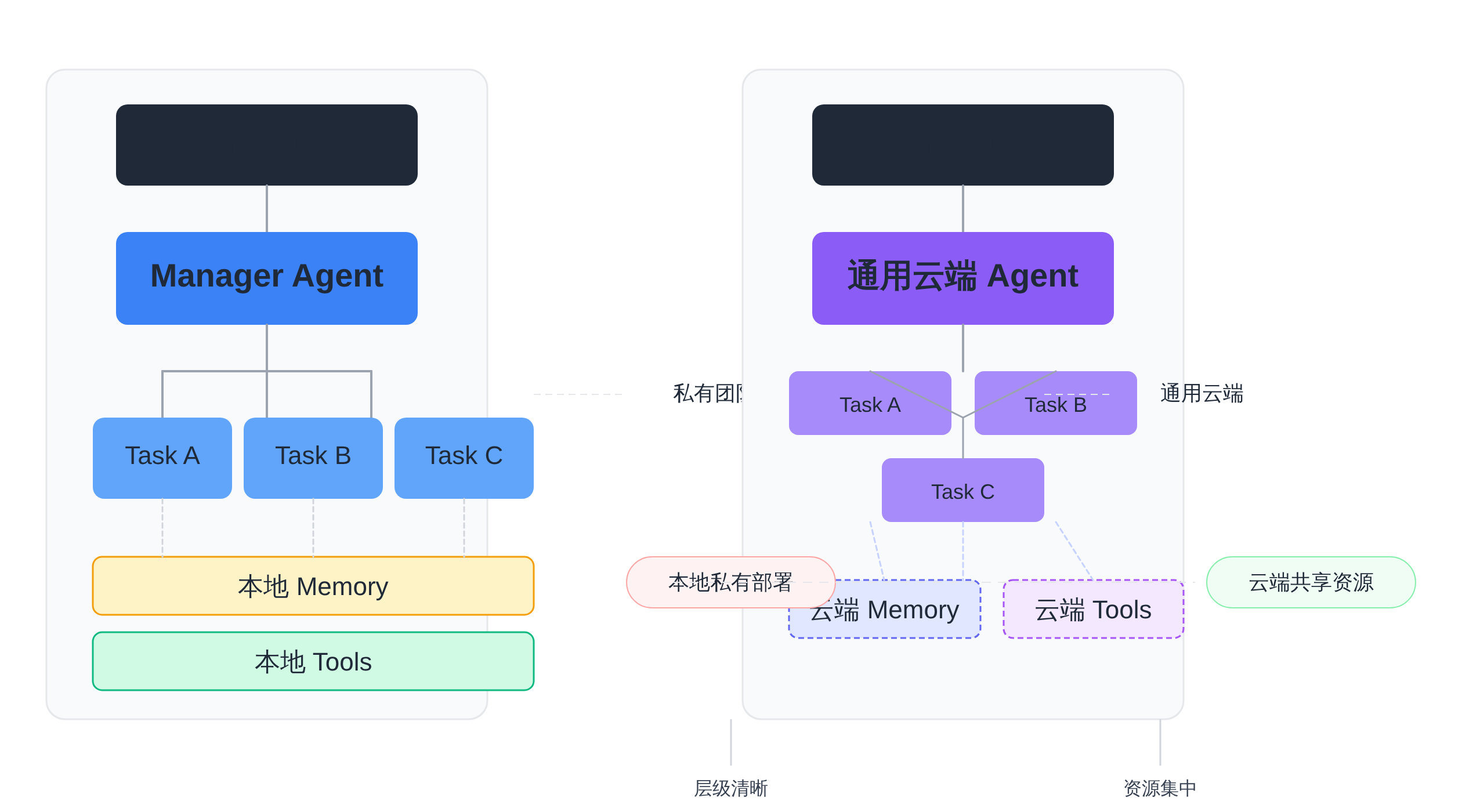
私有 Agent 团队的层级结构与通用云端 Agent 的对比
这时候,本地私有 Agent 团队反而有可行性。企业可以部署自己的 Agent 集群,跑在私有网络里,数据不离开防火墙,日志可控,权限可审计。对于强监管行业,这是合规的前提;对于高价值数据,这是商业竞争的基础。
当然,私有化也意味着更高的运维成本和更慢的模型迭代速度。这不是非此即彼的选择,而是场景驱动的权衡。我倾向于认为,未来会是混合态:通用能力跑在云端,隐私数据和核心流程跑在本地。它们之间通过 A2A 或 ACP 协议连接,形成一个整体的 Agent 生态。
我自己判断,这个变化会发生在「协作层」而不是「单兵层」。当 Codex 能把一个完整的 PR 从设计到代码全部跑完,当 Claude Code 能在本地终端完成端到端开发,当单兵 Agent 已经把工具链填满到 80% 以上的顶尖形态,竞争的下一个焦点就不再是「这个 Agent 能做什么」,而是「多个 Agent 怎么协作」。
这个判断有几个支撑点。第一个是上下文窗口的物理约束。一个 Agent 不管多强,它的上下文窗口是有限的,不可能同时吃掉 CTO/CPU、架构决策、业务逻辑、代码审查、日志分析这些所有任务。当任务复杂度超过阈值,最优解不是训练更长的上下文,而是把任务拆给不同的 Agent。第二个是入口分散化。用户使用 Agent 的场景已经不只是浏览器里那个对话窗口了——终端 CLI、本地桌面 App、手机 IM 插件、浏览器扩展,每一种入口都在争夺注意力。这种分散化会倒逼 Agent 层必须具备跨端持续状态的能力,否则用户体验会割裂。
从单点到协作,Agent 的云计算时刻正在发生
所以我自己想做的方向,是构建一个「跨端、跨上下文持续协作」的 Agent 层。注意这里的核心词是「层」而不是「产品」。我认为未来不会有单一 Agent 产品统治所有入口,而是每一类入口背后有一个 Agent 实例,它们共享记忆层、任务状态和协作协议。这个层需要解决几个具体问题:
第一个是长期记忆的持久化。跨 session 的上下文不能只依赖模型本身的 context window,需要有结构化的 workspace 文件和 memory 模块。这一点 MCP 协议已经在尝试标准化,但实际落地还需要解决版本控制、冲突合并和隐私隔离这些问题。
第二个是协议层的互操作性。A2A、ACP、MCP 这些协议各有侧重点——A2A 处理 agent 间通信,ACP 定义会话生命周期,MCP 标准化工具上下文。它们不是竞争关系,而是互补的。我的判断是未来会出现一个协议栈,各层各司其职,开发者按需组合。
第三个是本地私有化部署的可控性。很多 Agent 场景天然包含隐私——医疗记录、财务数据、内部决策过程。把这些数据交给云端 Agent 有合规风险,但完全本地化又会失去跨端协作能力。我的判断是未来会有一类「私有 Agent 团队」方案:数据留在本地,Agent 实例之间通过加密协议协作,结果输出到本地,只有必要摘要同步到协作层。
最后我想说一句可能偏个人一点的话:我认为这个方向不会在短期内出现一个确定的赢者。市场还需要时间理解协作层的价值,协议层还需要更多的生产环境验证,本地化方案还需要解决性能和隐私的平衡。但从技术趋势看,单点能力已经趋向饱和,协作层的可能性才刚刚打开。这是我愿意持续投入的方向。
参考文献
[1] Agent2Agent (A2A) Protocol Specification. https://google-a2a.github.io/A2A/specification/ [2] Agent2Agent latest documentation. https://google-a2a.github.io/A2A/latest/ [3] Hermes Agent programmatic integration. https://github.com/nousresearch/hermes-agent/blob/main/website/docs/developer-guide/programmatic-integration.md [4] Hermes ACP feature documentation. https://github.com/NousResearch/hermes-agent/blob/main/website/docs/user-guide/features/acp.md [5] Model Context Protocol introduction. https://modelcontextprotocol.io/introduction [6] Anthropic: Introducing the Model Context Protocol. https://www.anthropic.com/news/model-context-protocol [7] OpenAI Codex product page. https://openai.com/codex/ [8] OpenAI Codex CLI getting started. https://help.openai.com/en/articles/11096431-openai-codex-cli-getting-started

如果浏览器无法直接唤起微信,可在微信内打开公众号主页:计算机魔术师


