2026年3月,一个港中深的研究生在牛客网发了篇阿里云AI Infra二面复盘帖。
1帖子开头写着:「整体感受是,这轮不是那种偏八股或者偏刷题的面试,更像是围绕项目经历一路深挖,看你到底有没有真的做过优化,也看你对自己后面想做的方向是不是足够清楚。
」几百条回复里点赞最高的评论只有两个字:真实。
这句话点出了一个正在发生但很多人还没完全接受的事实:AI工程师面试的考核逻辑已经变了。
不是变得更难,而是变得更立体。以前靠背住激活函数的公式、记清楚Transformer的架构图就能过的关,现在只是第一道门槛。
真正的筛选发生在:你能不能讲清楚为什么GeLU替代了ReLU,能不能在RAG系统设计里把分块策略和向量检索的权衡说清楚,能不能在被追问到「你项目的真实边界在哪」的时候不慌。
这不是一篇新的面试题汇总。
本文是基于GitHub上AI Engineering Field Guide2——一个汇集了Reddit、X、博客、YouTube等100+来源的AI工程师面试系统性资源的开源项目——进行的深度拆解。
我的目标不是帮你收集更多题目,而是帮你看清这些题目背后,面试官到底在验证什么。

面试官:所以你真的理解了你做的东西?
一、理论考核:不是背公式,是考你对模型为什么这么设计的理解
面试里最常见的误区是把理论题当名词解释题来准备——见到ReLU就背公式,见到BERT就画架构图,见到注意力机制就写公式。这种方法在2019年之前可能够用,但现在不行了。
现在的理论题有两层考法。第一层还是验证基础概念的掌握,但第二层才是拉开差距的地方:追问「为什么这样设计」「有什么替代方案」「你在项目里什么时候选了这个而不是那个」。
GeLU激活函数:超越定义,理解替代ReLU的工程动机
GeLU在2026年已经是大模型标配的激活函数,GPT系列、LLaMA、Claude都在用。但面试里问GeLU,不是要你默写它的公式:
$$\text{GeLU}(x) = x \cdot \Phi(x)$$
其中 $\Phi(x)$ 是标准正态分布的累积分布函数。
真正的问题是:为什么大模型选择GeLU而不是继续用ReLU?
这里有三条工程线索可以串联起来回答。第一,ReLU在负数区间存在硬零梯度——小于0的部分直接变成零,梯度断掉,参数无法更新。
这在训练深层网络时会产生「dying ReLU」问题,影响收敛。第二,GeLU引入了概率性的平滑机制:输入不是简单被保留或截断,而是根据其统计量被概率性地保留,梯度流动更平滑。
第三,GeLU和残差连接、LayerNorm配合更好——大模型普遍采用Pre-LN结构,GeLU的平滑梯度在多层堆叠时更稳定。
如果你在项目里用过GeLU,面试官很可能会追问:你在哪个任务上用的GeLU,换成ReLU效果有什么区别?
这个追问的方向很明确——他不只是要你描述现象,而是要你能解释因果:GeLU的计算量比ReLU高大约30%,但换来的是收敛更稳定和梯度流更顺畅,在大模型场景下这个trade-off是值得的。
BERT模型构建:从Embedding到MLM/NSP的全链路追问
BERT的理论题几乎是所有AI NLP面试的标配。但「BERT的结构是什么」这个问题,现在已经是入门级。真正的追问集中在三个方向:
Tokenization层的设计取舍。 WordPiece vs Byte-Pair Encoding vs Unigram Language Model的区别是什么?
BERT用的是WordPiece,GPT用的是BPE。你需要能说清楚:WordPiece的子词粒度更细,对OOV词汇更友好,但在不同语言上需要单独训练分词器;
BPE训练更简单但词汇表通常更大。为什么BERT选择WordPiece而不是其他方案?因为BERT的目标是预训练阶段学习丰富的语义表示,子词粒度有利于捕捉形态学信息。
**MLM和NSP的任务设计逻辑。
** MLM(Masked Language Model)随机遮盖15%的token,其中80%用[MASK]替换,10%用随机词替换,10%保持不变——这个3:1:6的比例不是随意定的,是BERT团队在MLM任务有效性和[NSP]任务之间的平衡。
为什么不能100%用[MASK]?因为预训练时[MASK]符号不存在于微调阶段,造成预训练-微调不一致(pretrain-finetune mismatch)。
NSP任务的争议与后续改进。 NSP(Next Sentence Prediction)在RoBERTa等后续工作里被证明效果有限,很多任务上对模型性能几乎没有提升。
BERT之后的模型怎么处理的?有的直接删掉了NSP,有的用SOP(Sentence Order Prediction)替代。这条演进路径本身就回答了「BERT有什么局限」这个问题。
注意力机制变种:MHA、MQA、GQA的权衡逻辑
Multi-Head Attention(MHA)是最基础的架构,但2024年之后,大模型普遍转向了MQA(Multi-Query Attention)和GQA(Grouped-Query Attention)。
面试里的常见问题是:为什么要有MQA/GQA?
核心逻辑是推理效率。MHA在 декодин 阶段需要为每个注意力头加载独立的键值对(KV),KV缓存(KV Cache)的内存占用随序列长度和头数线性增长。
对于长上下文场景,这个开销成为推理的主要瓶颈。MQA通过让所有注意力头共享同一组KV,把KV缓存压缩到接近原来的1/h(h是头数),大幅降低显存占用。
GQA则是折中方案:把注意力头分成g个组,每组共享一组KV,在保持部分多查询特性的同时控制效果损失。
Llama 2用的就是GQA。具体怎么分组的、组数和头数的关系是什么,这就是「你项目里用过什么模型」这个问题的延伸追问方向。

面试官:所以GQA到底比MHA省了多少显存?
二、AI Coding轮:代码题没有消失,但它换了考察重心
AI Coding轮是AI工程师面试里变化最剧烈的环节之一。这里有个好消息和一个坏消息。好消息是纯算法题的比例在下降,系统设计类、ML实现类题目的比重在上升。
坏消息是:如果你以为「不考LeetCode Hard就算简单」,那就低估了这个环节。
传统LeetCode题 vs ML实现题:两种考察逻辑的差异
传统LeetCode题考核的是数据结构和算法思维——你能不能在限定时间内写出正确的代码,重点在正确性和复杂度分析。ML实现题考核的是:你能不能用代码实现一个机器学习概念,同时体现出对这个概念的理解。
举例来说,同样是「实现一个注意力机制」,一道LeetCode风的题可能要求你手写矩阵乘法、masked softmax、并行优化;
一道ML实现风的题可能要求你从零实现一个简单的transformer encoder层,包括词嵌入、位置编码、多头注意力和前馈网络,然后面试官追问「如果输入序列特别长怎么优化」「位置编码为什么不直接用sinusoidal而是 Learned PE」——这些追问本身就是对你ML理解的验证。
GitHub上AI Engineering Field Guide里整理的面经数据显示2:OpenAI和Anthropic的coding轮通常混合了传统算法题和ML特定实现题,比例大约各占一半。
Google DeepMind和Meta AI的岗位则更偏向ML实现题,尤其是涉及概率模型、梯度计算或特定模型架构的实现。
AICoding能力评估:OpenAI/Anthropic岗位的真实代码要求
OpenAI当前在招的Applied AI Engineer(Codex Core Agent方向)给出的薪资范围是$230K–$385K加上股权3。
这类岗位的coding轮通常不是让你实现一个排序算法,而是:给你一个真实的AI产品场景,让你设计数据管道、写模型推理代码、或者实现一个Agent的执行循环。
Anthropic的设计工程师岗位(Education Labs方向)则更注重对AI系统的理解深度——coding轮可能会让你实现一个简化版的RLHF pipeline片段,或者解释为什么PPO算法里的clip操作能防止策略更新过大。
这类题目没有标准答案,但你的回答方式本身就是面试官判断你「是否有真实的工程直觉」的直接依据。
如何在代码题中展现工程判断力,而不只是正确性
这里有个很多人没意识到的关键:AI工程师面试的coding轮,正确性只是及格线。
面试官真正在观察的是:当你在写代码的时候,你有没有在做权衡判断。
比如,你选择用list还是numpy数组实现矩阵乘法,不只是「哪个更好跑通」,而是涉及内存布局、cache友好性、向量化操作边界这些真实工程判断。
你在写一个attention实现时,先做scaled是出于数值稳定性考虑,这个细节说出来和不说出来,给面试官的信号完全不同。
一个实用的策略是:coding轮开始前,先用30秒和面试官确认输入输出的形状和数据类型。这个动作有两层价值——第一,确保你不会在方向上跑偏;
第二,向面试官展示你有「先想清楚边界再动手」的工程习惯。这在AI Coding轮里比在传统算法轮里更重要,因为AI代码的输入边界往往更模糊。

面试官:你的边界条件处理呢?
三、AI System Design:这是拉开差距的主战场
如果只能选一个模块来区分候选人的真实水平,那一定是System Design。
在AI Engineering Field Guide的100+来源分析里,这是被提到频率最高、但也是候选人准备缺口最大的模块。
System Design的题目通常从一个产品场景出发:「如果你要设计一个RAG系统来支持客服机器人」「如果你要设计一个多Agent系统来处理订单」「如果你要为长文档问答设计一套架构」。
这些题没有标准答案,但面试官有一套相对固定的评估维度。
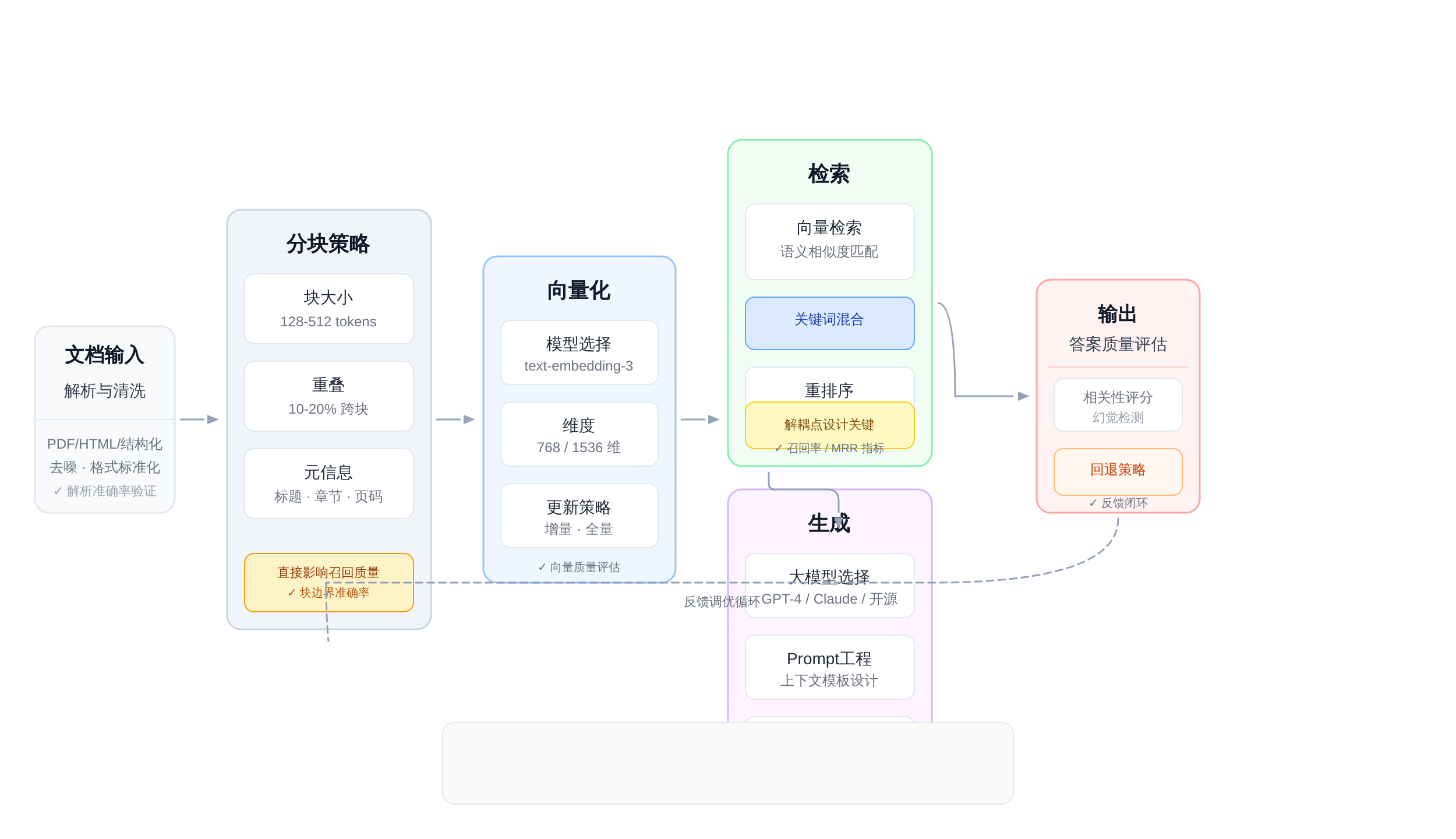
RAG全链路设计:从文档分块到向量检索到答案生成的完整评估维度
RAG(Retrieval-Augmented Generation)是2024-2026年AI应用面试里出现频率最高的系统设计主题。完整的RAG链路可以拆成六个评估维度:
正文图解 1
文档分块(Chunking) 是RAG里最容易被低估的第一个坑。
固定块大小(512 tokens或1024 tokens)是最简单的方案,但最优方案需要考虑语义边界——一段完整的论述被截断会造成语义信息丢失,检索时召回的片段可能缺少关键上下文。
重叠分块(overlapping chunks)是常见的改进,但重叠比例设多少合适?通常是15%-25%,太低覆盖不足,太高冗余太多。
Embedding模型选择 也是一个权衡维度。OpenAI的text-embedding-ada-002使用方便但成本高;
开源的sentence-transformers可以在本地部署但效果因模型而异;
针对特定领域(法律、医疗、技术文档)fine-tuned的embedding模型效果好但需要数据和训练成本。
面试时如果被问到「你的客服机器人文档检索用什么embedding」,正确的回答不是「用text-embedding-3-small」,而是「根据文档类型、查询复杂度和延迟要求,我们评估了三个候选方案:A在精确术语检索上好但对口语化查询召回低,B在语义相似度上好但需要GPU推理,C是二者的混合方案——最后选了C,理由是……」。
检索与生成之间的质量保障 是2025年之后RAG面试的新热点。面试官会问:「如果检索到的文档和用户问题不相关怎么办?
」「用户问题表述模糊导致召回了多篇部分相关的文档,答案怎么组织?」这些问题指向的是RAG系统里的重排序(Reranking)机制和上下文组装策略。
ColBERT这类late-interaction模型在多文档Reranking上有优势,但引入了额外的推理延迟,这个trade-off需要结合业务场景来权衡。
多Agent架构设计:任务分解、通信协议与状态一致性
多Agent系统设计是2025-2026年AI面试的新晋高频考点。GitHub上的AI Engineering Field Guide专门整理了这个模块2,核心问题模式包括:
如何设计Agent之间的任务分配策略
Agent间通信协议怎么选:共享内存 vs 消息队列 vs API调用
多Agent协作时的一致性问题:如何避免状态冲突
如果某个Agent超时或失败,系统怎么回退或降级
多Agent设计的核心不是「用几个Agent」,而是「如何定义Agent的边界和协作协议」。
一个常见的设计误区是把Agent划分得太细——每个小功能都单独做成一个Agent,导致通信开销远大于处理逻辑本身的成本。
好的设计是:先定义清楚每个Agent的职责域,然后用最小化的通信协议把这些Agent串起来。
比如设计一个代码审查Agent系统:Planner Agent负责理解需求和拆解子任务;Coder Agent负责生成代码;Reviewer Agent负责静态分析和提出修改建议。
如果Reviewer发现严重问题,是直接让Coder重写,还是回给Planner重新规划?这个决策流程本身就是多Agent架构设计的一部分。
分布式推理的延迟与吞吐量权衡:硬件约束下的系统判断
系统设计题里有一个越来越常见的维度:硬件约束下的工程决策。
Arm在2026年3月发布了专门针对Agentic AI任务的AGI CPU,Meta是首个获得样片的客户,OpenAI、SAP、Cerebras、Cloudflare也签订了采购协议4。
Arm CEO Rene Haas在发布会上说:「我们相信Agentic AI CPU市场到2030年将从今年的$250亿增长到$1000亿规模。」
这个硬件背景对面试的影响是:面试官越来越期待候选人对推理效率有真实理解。
比如,问你「长序列(128K tokens)的transformer推理有什么瓶颈」,一个只看过论文没跑过实物的候选人会说「O(N²)复杂度的注意力计算」,但真正有工程经验的候选人会进一步说:「128K序列的KV Cache在A100 80GB上大约占用160GB显存,单卡根本放不下,需要用PagedAttention或张量并行;
同时序列太长导致first token latency很高,可以用推测解码(Speculative Decoding)来优化。」
这个差距不是知识储备的差距,而是有没有真实处理过这个问题并做过取舍判断的差距。

面试官:你说优化过延迟,那你优化的极限在哪?
四、Behavioral面试:技术之外,面试官在验证你是否能被信任
Behavioral面试是AI工程师面试里最容易被低估的环节。很多工程师把它当成「聊人生环节」来准备,随便翻了几个STAR法则的例子就觉得够了。
但Behavioral的真实目的是验证你技术叙述的真实性,以及你是否具备在真实工程环境里正常运转的软技能。
STAR法则在AI工程师场景的具体应用
STAR(Situation-Task-Action-Result)是Behavioral面试的标准框架,但「知道STAR」和「能用STAR讲好一个技术故事」之间隔着一道真实的工程经验积累。
S-T部分需要你快速建立场景:一个棘手的系统问题,一次跨团队的架构决策,一次失败的技术选型。场景太普通显得你没经历过真实的复杂环境,场景太夸张又会让人觉得不真实。
AI Infra相关的Behavioral里,最有说服力的场景通常是:推理延迟超标、显存OOM、训练loss不收敛、模型量化后精度损失超出预期——这些都是工程师真实经历过的工程危机。
A部分需要你讲清楚你的行动。常见的问题是候选人把「我们团队决定……」当成「我做了……」。面试官想听的是「你个人在其中的判断和行动」,不是团队摘要。
如果你只是参与了会议、写了代码,要如实说;如果你主导了某个决策,要能把决策逻辑讲清楚。
R部分是最容易被注水的。数据要真实可查:延迟从多少降到多少?显存占用减少了多少百分比?召回率从多少提升到多少?「效果有明显提升」这种模糊表述在Behavioral面试里是减分项。
从项目经历到决策叙事:如何讲出有弧线的技术故事
阿里云AI Infra二面的一个追问方向值得单独拆解。面试官问了一个典型的Deep Dive:「你提到修过一个推理/训练过程中显存异常和长稳问题,这个问题原来为什么会发生,你具体做了什么?」5
候选人的回答有一条清晰的弧线:先是定位链路——「一条图优化之后的链路里,本来应该走host侧的shape tensor,在int32场景下被错误地当成了device tensor去传」——这是问题诊断。
再是处理方案——「把这条链路里相关的shape信息显式约束回host memory路径,避免host/device封装混乱」——这是工程决策。
最后是结果验证——训练过程稳定,维度异常消失。
这个回答好在哪里?
在于它不是「我修复了一个bug」这句话的膨胀版,而是展示了:你能诊断复杂链路上的问题(不只是读懂错误日志),你能设计一个不引入新问题的解决方案,你能验证修复的有效性。
这三个能力就是面试官在Behavioral里真正想验证的东西。
诚实认知的工程边界:阿里云二面追问背后的Behavioral逻辑
Behavioral面试还有一个隐性维度:候选人对自身局限的诚实认知。
阿里云AI Infra二面里,候选人自己总结:「相对一般的部分,是更底层的微架构细节和更深入的多卡通信经验,这两块后面还得继续补。」1
这个诚实不是谦虚表演——面试官能分辨出来。真实工程环境里,知道自己不知道什么比假装全懂更有价值。
当你被追问到一个不熟悉的领域,正确的应对不是硬撑,而是:「这个方向我了解有限,但我知道它和X方向相关,我的理解是……如果深入讲可能需要再确认一下。
」这种回答展示了:边界清晰、有推断能力、不会乱讲。
五、Home Assignments与Project Deep Dive:你说你做过,你怎么证明
Home Assignment(take-home task)是AI工程师面试里让很多人最紧张但也最值得认真准备的环节。
它之所以重要,是因为这是唯一一个你能提前系统准备、且有完整时间思考的考核环节——同时也是唯一一个面试官可以直接看到你代码质量和工程判断的环境。
Take-home Assignment的真实评估维度
Home Assignment的评估不只是「你能不能完成功能」。GitHub上的AI Engineering Field Guide整理了100+真实案例2,评估维度通常包括:
代码质量:模块化程度、命名规范、是否有适当的错误处理。
功能完整性当然要,但面试官更关心的是你「在有时间压力下怎么取舍」——如果你在8小时限制里做不完,你是选择放弃部分功能还是降低某个功能的实现质量?这个决策本身也是评估材料。
扩展性:你的设计能不能在数据集扩大10倍、或者增加一个新模型时保持可用?如果你做的RAG demo只能跑100条文档,换成10000条就崩了,这个限制面试官会通过追问发现。
文档和可复现性:README里有没有说清楚怎么运行、依赖是什么、结果怎么验证?面试官拿到一个跑不通的assignment,基本等于功能缺失。
Project Deep Dive的追问套路:追问到哪个层次才算过关
Project Deep Dive是阿里云AI Infra二面的核心环节,也是OpenAI和Anthropic等公司AI面试里的标配。
追问的深度有一个简单判断标准:如果面试官追问到第三层你还回答得很流畅,说明这个项目你是真的做过。
第一层追问通常是功能描述:「你在这个项目里做了什么?」——这是基本信息。
第二层追问是实现细节:「你是怎么实现的?为什么用这个方案而不是另一个?」——这要求你对技术选型有清醒的判断。
第三层追问是边界和局限:「这个方案在什么情况下会失败?你怎么验证的?」——这才是真正检验深度的地方。
比如你做过AWQ量化(W4A16),第二层追问可能是:「Linear层怎么改的?数据结构怎么设计?」——如果你的回答只是「把权重从FP16量化到Int4」,这是背诵级答案。
真实的Deep Dive答案需要具体到:「我们修改了Linear的反向传播梯度缩放逻辑,在weight矩阵的每一Channel上维护一个缩放因子,量化时保证 INT4 反量化后的值域尽量对齐原始FP16的分布……」5
AWQ量化项目示范:如何把功能描述升级为设计叙事
一个能从「功能描述」升级为「设计叙事」的AWQ量化项目,需要在三个维度上讲清楚:
**量化策略的选择逻辑。
** AWQ(Activation-Aware Weight Quantization)的核心假设是「权重不是同等重要的——大约1%的显著权重对模型精度影响最大」。
所以AWQ在量化时保护这1%的显著权重,只对剩余99%进行低比特量化。为什么这个假设成立?
因为大模型的权重分布是重尾分布,极少数参数承担了绝大部分的信息传递功能,量化时优先保护这些参数能最小化精度损失。
工程实现里的取舍。 向量化加载是AWQ实现里的常见优化——把更小粒度的数据打包读取,减少内存访问次数。但这个优化的前提是内存布局要对齐,否则打包读取反而引入额外的对齐开销。
在实现里,你需要处理的问题包括:不同硬件平台的向量化宽度限制、不同shape的模型权重如何在不打零的情况下高效打包。这些细节说出来,就和「用AWQ做了量化」这句话拉开了本质差距。
端到端验证的方法。 量化后的正确性验证不是简单「跑一下loss没爆炸」就完了。
标准做法是把量化后的输出和原始FP16的输出做逐token对比,计算精度差异的统计量(KL散度、余弦相似度等),确认精度下降在可接受范围内(通常Perplexity增幅不超过5%)。

面试官:所以你的AWQ实现,在不同batch size下表现稳定吗?
六、复习路径:从题库到面试现场的转化策略
看完前面的五个模块,一个自然的疑问是:这么多内容,复习优先级怎么排?
本科生/研究生/转行者的差异化优先级
本科生(低年级,有2-3年准备时间) 的优先策略是先把理论根基打扎实。
GeLU、BERT、注意力机制这些基础理论是所有后续面试的底层支撑,现在理解透彻了,秋招时复习效率会高很多。
同时尽早做一个有深度的项目——哪怕是课程项目,也要有记录、有反思、有能回答「你项目的真实边界在哪」这个问题的素材。
研究生(临近毕业,6个月以内的准备窗口) 的优先策略是把自己的论文或实习项目打磨成Project Deep Dive的素材。
面试官对研究生项目的期待是:你能把这个项目的技术细节讲得比任何教科书都清楚,因为这是你最有可能被追问的方向。
同时,系统设计里的RAG和多Agent部分是你补齐短板最快的模块——这些内容的核心是工程判断,可以通过大量读案例和模拟设计来快速积累。
转行者(从传统后端/数据工程转向AI) 的优先策略是先补AI Coding轮的基础。大多数转行者有扎实的工程能力,但ML实现的直觉需要单独训练。
建议从PyTorch实现经典模型开始:自己动手实现一个transformer encoder、训练一个简单的分类模型、处理过拟合问题——这些经历会成为coding轮和project deep dive的真实素材。
不同模块知识如何在面试中串联成连贯工程叙事
面试里最加分的状态,不是你分别回答了五个独立的问题,而是你用一条工程逻辑线把它们串了起来。
一个好的工程叙事示例:「我在做长文档问答项目时,首先遇到了RAG召回质量不稳定的问题——固定块大小的分块策略导致语义截断,准确率只有67%。
我尝试了三种分块方案,最后用语义分块+重叠策略把召回提到了83%。
在这个过程中我发现瓶颈不只是检索,生成阶段的长上下文处理也有问题,于是我又调研了GQA的KV Cache优化方案,测试了本地部署的小模型和API调用的GPT-4的延迟差异,最终选择了一个混合架构……」(后续展开具体数据和技术判断)。
这条叙事里串了RAG分块设计、GQA和推理优化、项目决策权衡三个模块,而且每个模块都有具体的数字和判断,不是空洞的「我学了很多东西」。
面试后环节:offer handling、rejections与salary negotiation
这一节在AI Engineering Field Guide里是独立章节2,但往往被候选人忽略。
面试通过只是第一步——拿到offer之后怎么谈薪资、拿到多个offer怎么选择、面试失败后怎么有效复盘,这些都是真实求职路径里不可跳过的环节。
一个实用的原则是:把每一次面试都当成数据收集的机会。即使这轮没过,你能从面试官的追问方向里读出「这个岗位的真实需求是什么」——这些信息对下次面试的准备方向有极高价值。
阿里云AI Infra二面的候选人自己在复盘里写了:「更底层的微架构细节和更深入的多卡通信经验,这两块后面还得继续补。」1 能做到这种程度的自我分析,下次面试的命中率会明显提升。

面试季很长,但每次复盘都是下一场的弹药