2026年4月,DeepSeek V4的跳票已经成了国内AI社区的日常笑话。每隔几天就有群友问「V4今天发了吗」,然后群里整齐划一地回一个「没有」。
这事说起来有点荒诞:一个模型还没发,围观群众已经把跳票倒计时玩成了梗。可如果你把时间线往回倒一年,会发现这家公司上一个模型(R1)发布的时候,可是把美股吓得集体抖了三抖的。
DeepSeek V4到底在憋什么大招?换芯华为这件事有多难?万亿参数+35倍推理加速+百万上下文这三个数字是不是真的能打?
黄仁勋那句「对美国是灾难」到底有没有根据?这篇文章把所有公开信息扒干净,给你一份可以自己核对的情报分析。

V4你到底什么时候发啊
DeepSeek V4为什么拖了这么久?一条时间线说清楚
2025年1月:R1是怎么把美股吓崩的
先说清楚R1的含金量,才好理解大家对V4的期待为什么这么高。
2025年1月,DeepSeek发布了R1模型。技术圈震惊的点倒不是「它有多强」,而是「它用多便宜的方法做到接近GPT-4水平的」。
R1展示了一条关键结论:在足够好的算法设计下,用相对有限的算力也能训练出SOTA水平的模型。
这直接挑战了当时华尔街最信仰的一条叙事——Scaling Law需要天量GPU投入,而天量投入=英伟达业绩的长期保障。
市场反应堪称惨烈。纳斯达克综合指数单日下跌约3%,英伟达(NVIDIA)单日跌幅超过17%,市值单日蒸发约6000亿美元1。这不是普通的回调,是市场第一次认真在问:AI竞争里,算力是不是被高估了?
英伟达CEO黄仁勋后来在多个场合回应R1的影响。
他没有直接说「DeepSeek不行」,而是用了一个更外交的措辞:DeepSeek的技术突破让美国AI行业需要更认真地对待竞争,同时也暗示了算力投入的长期逻辑没有改变。
但社区里一直流传着他私下更尖锐的评论——具体措辞各路媒体报道版本不一,但核心意思是:如果中国团队用非美国芯片做出同等水平的模型,对美国AI生态是结构性威胁。
这不是阴谋论,而是可以理解的商业逻辑。英伟达今天接近40%的数据中心收入来自中国市场(2024财年数据口径),一旦这个市场开始用昇腾训练大模型,美国芯片禁令就变成了给英伟达「自己挖的坑」。

6000亿美元蒸发,黄老板当场血压飙升
从春节到2026年4月:V4的「跳票编年史」
好了,背景铺垫完了,回到V4。
2025年第四季度,国内AI社区开始小范围流传V4的核心参数:万亿参数MoE架构、35倍推理加速、100万token上下文窗口。
几个数字一出来,技术圈直接炸了——这不是V3的渐进式升级,而是往天花板方向开炮。
然后就进入了漫长的等待。
2026年1月,多位接近DeepSeek的人士在不同场合透露:V4将在春节前发布。农历新年过去了,没有。
2026年2月,版本分化:有人说算力不够(GPU集群排队),有人说在调整架构,有人说在等一个「重要合作」。
到了3月,「换芯」的说法开始出现,虽然细节模糊,但不同信源指向了同一个方向:DeepSeek可能在把训练基础设施从英伟达芯片迁移到华为昇腾。
2026年4月最新的信源指向最清晰:华为昇腾适配是当前最核心的延期因素。这意味着V4可能从立项开始就是基于昇腾设计的,也可能是做到一半临时切换——两种情况的工程代价天差地别,但结果是一样的:跳票。
跳票的真正原因:芯片路线之争
DeepSeek之前的训练基础设施大量依赖英伟达H系列芯片:V100、H100、H800。
H800是英伟达专门为中国市场设计的合规版,算力约为H100的60%左右,在美国2022年10月和2023年10月的两轮出口管制后成为对华可销售的最强训练芯片。
如果DeepSeek要彻底转向华为昇腾,意味着什么?
CUDA——英伟达的并行计算平台和编程模型——是过去十年全球AI开发者的默认选择。几乎所有主流AI框架、工具链、算子库都深度绑定CUDA。
迁移到昇腾,不只是换一张显卡那么简单,而是需要把整个训练工程链路从底层重写:指令集适配、内存层次优化、集合通信库(英伟达用NCCL,昇腾用HCCL)切换、混合并行策略重新调参。
这大概就是内部人士口中「大规模重构」的真正含义。
DeepSeek V4到底升级了什么?三个数字讲清楚
万亿参数MoE:参数量不等于智商,但代表上限
先说清楚MoE(混合专家)架构的原理。
传统大模型(比如BERT时代的那种),每次推理都要把所有参数激活一次。你有一个700亿参数模型,跑一次推理就等于把700亿个参数全部用一遍,成本极高。
MoE的核心思路是:把模型拆成多个「专家」(Expert),每次推理只激活其中少数几个专家网络。
举个例子:万亿参数MoE模型可能有128个专家,但每次推理只激活8个。那实际参与计算的参数量大约是80亿,但模型的「知识储备」覆盖了万亿级别。
这意味着你在推理成本上接近80亿参数模型,但在知识容量上接近万亿参数模型。
所以「参数量不等于智商」这句话要这么理解:一个万亿参数MoE模型的智商上限(知识容量、泛化潜力)可能接近万亿密集模型,但实际每次推理的「智商表现」取决于激活参数量够不够支撑当前任务。
两个数字要分开看。
V4的万亿参数,具体是总参数量还是激活参数量,目前各路信源表述不一致。如果是总参数+稀疏激活,那V4的真实推理成本可能远低于数字本身的震撼感。
35倍推理加速:数字是怎么测出来的
35倍这个数字很抓眼球,但测试基准(benchmark)非常重要。
DeepSeek之前放出的技术文档显示,推理加速主要来自三个工程优化:FP8低精度量化(用更少的bit表示权重,减少计算量)、KV Cache优化(减少重复计算已经处理过的token)、Tensor Parallelism增强(多卡并行推理,降低单卡负载)。
这里有一个关键区分:Throughput(吞吐量)和Latency(延迟)。
35倍如果是Throughput提升,意味着每秒能处理的请求数提升了35倍,适合to B场景(企业API调用量大)。
如果是Latency提升,意味着单次推理的响应时间缩短了35倍,适合to C交互体验。如果是两者兼有,那这个数字的含金量就相当高了。
目前公开信源没有明确区分这两个指标,建议等官方评测报告出来再下结论。但在工程层面,这个量级的优化不是小修小补能做到的,需要对模型结构、推理框架和硬件调度做联合优化。
35倍加速,测试集是哪张卡跑的?
100万上下文:解决「对话写到一半模型失忆」的老毛病
这是三个数字里普通用户感知最强的。
当前主流大模型的上下文窗口通常在32K到128K token之间,换算成中文大约是1.5万到6万字。
这个长度写短文够用,但处理长文档、做代码库级分析、或者进行多轮复杂推理时,模型就会「失忆」——写到一半忘了前面说了什么,这是因为Attention计算的复杂度是O(n²),序列越长计算成本爆炸式增长。
100万上下文,换算成中文大约是50万字,等于一本《战争与和平》加《安娜·卡列尼娜》再加大部头技术文档塞进一个对话窗口。这个量级的上下文窗口需要解决几个工程难题:
稀疏注意力机制,把全量Attention拆成局部窗口+稀疏全局模式的组合;分层召回,在不同粒度上维护信息索引而不是死记硬背全量序列;
滑动窗口+向量检索,在保留最新信息的同时允许模型检索被「遗忘」的历史段落。
DeepSeek在R1里已经展示了处理长推理链的能力,V4的100万上下文可能是把这种能力产品化、工程化之后的成果。
mHC架构+华为芯片:DeepSeek V4的「真技术底牌」
mHC是什么:让万亿参数训练不爆炸的秘密
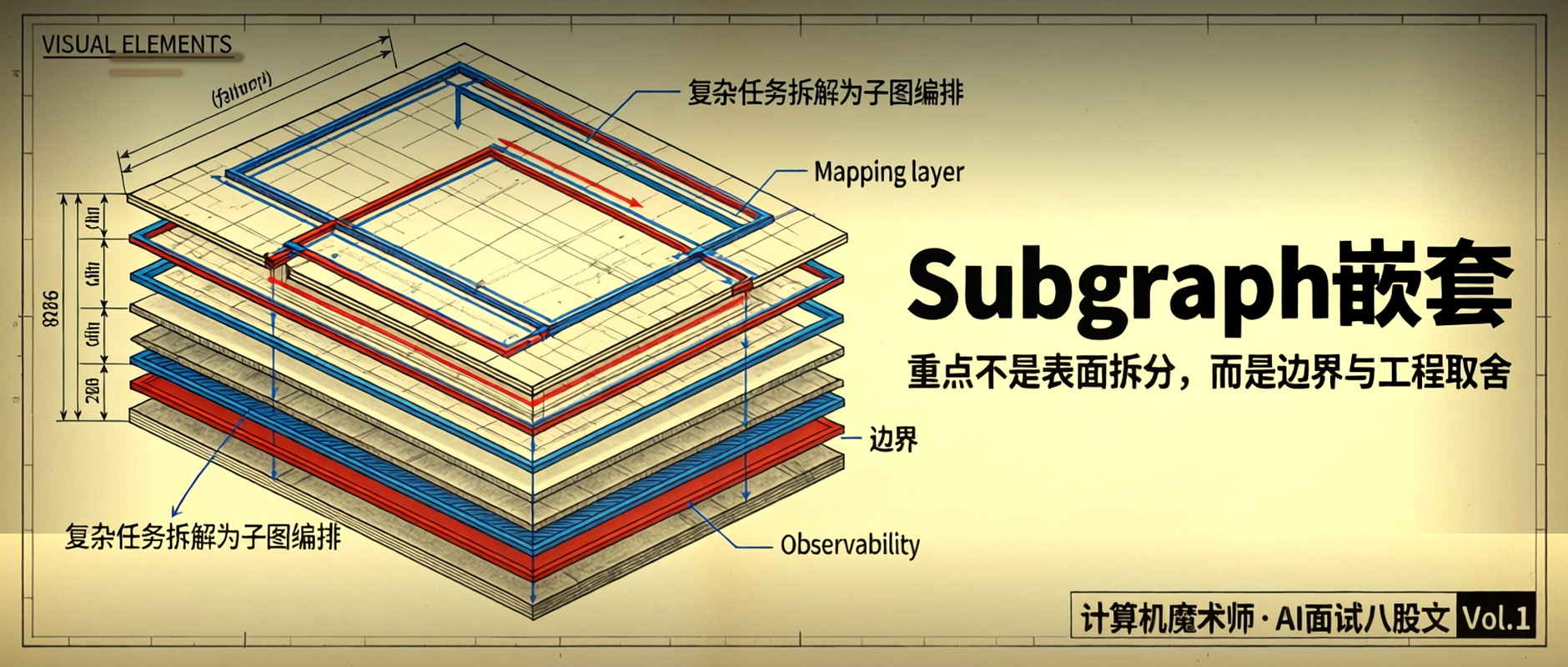
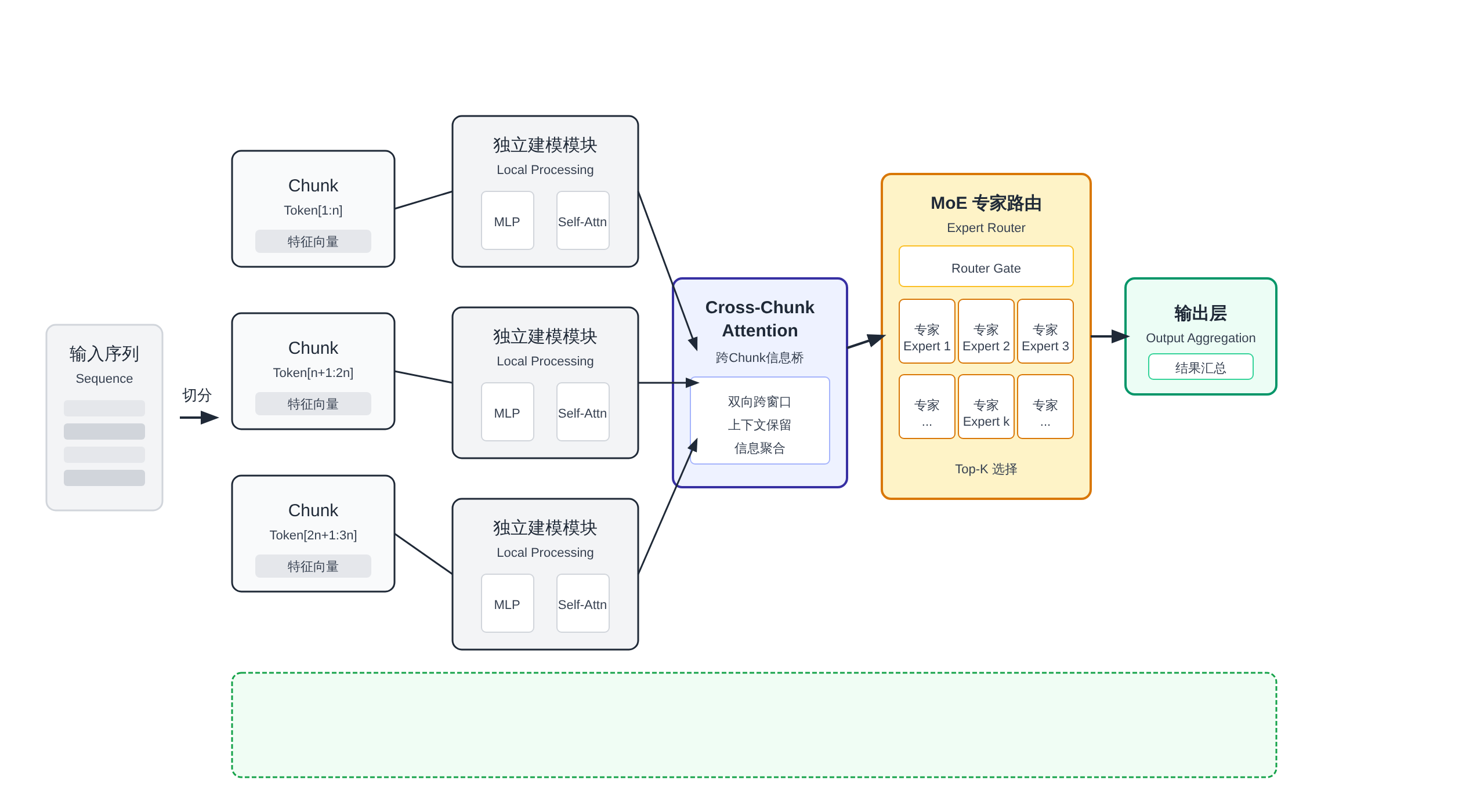
mHC(Multi-head Chunked architecture,多头分块架构)是V4技术文档里最让工程师兴奋的一个词,但也是解释起来最容易变成玄学的一个词。
大白话版本是这样:训练一个万亿参数的模型,最难的不是参数量本身,而是「长序列」的处理——比如100万token的序列直接塞进去做Attention,内存会原地爆炸。
mHC的核心思路是把超长序列切成固定大小的chunk(比如4K或8K token一个chunk),每个chunk独立建模,然后在chunk之间通过cross-chunk attention或者state compression传递跨chunk信息。
你可以把它理解成:不是一口气读完一整本书,而是分段读,读完一章做一页笔记,然后根据笔记理解下一章,而不是把之前所有内容都装在脑子里。
人类也是这样工作的,模型这样设计之后训练更稳定,显存占用从O(n²)降到了接近O(n)的水平。
这是V4能在「万亿参数+百万上下文」两个条件同时成立的关键技术前提。
没有mHC或者其他类似的长序列优化方案,直接用标准Attention训练百万上下文,万亿参数模型在A100上会直接OOM(显存不够)到怀疑人生。
正文图解 1
华为昇腾适配:一次需要「大规模重构」的转身
这一节是整篇文章最「干」的部分,但也是最决定V4能不能成功的部分。
华为昇腾910B/910Pro是目前国内性能最强的自研训练芯片,官方标称FP16算力分别约为320 TFLOPS和512 TFLOPS2。
作为对比,A100的FP16算力是312 TFLOPS(H100是989 TFLOPS)。也就是说,昇腾910B的单卡算力接近A100,910Pro略有超出。
但数字接近不代表软件生态接近。
英伟达的CUDA生态花了十几年建立的护城河,不是一张芯片能替代的。
昇腾的底层是达芬奇架构(Da Vinci),配套的软件栈是CANN(Compute Architecture for Neural Networks)。
主流AI框架(PyTorch、MindSpore等)对昇腾的支持是「能用但不够顺滑」的状态——很多PyTorch原生算子在昇腾上需要通过CANN的算子适配层绕一下,这个绕的过程会产生性能损耗,也会引入各种奇怪的bug。
DeepSeek的工程团队如果要把V4的训练基础设施从英伟达切换到昇腾,需要做以下事情(按难度从高到低):
重写或适配所有依赖CUDA特定指令的算子;把NCCL(英伟达集合通信库)替换成HCCL(昇腾集合通信库),并重新调优多卡通信拓扑;
针对昇腾的内存层次(Ascend 910系列有独特的HiChip互联结构)调整混合并行策略;
用昇腾的调试工具链替换英伟达的NVTX/Nsight体系,重新建立性能profiling基线。
这是典型的「看起来硬件够用,软件全是坑」场景。一位参与过昇腾迁移的工程师私下说:「适配阶段每天不是在训练模型,是在训练自己对bug的耐受度。」
算力选择背后的地缘信号
把上面几节连起来看,一条清晰的逻辑链就出来了:
美国芯片出口管制从2022年10月(首批高端芯片禁运)到2023年10月(H800进一步受限)逐步收紧。这意味着国内AI公司用英伟达合规芯片训练大模型的窗口越来越小,成本越来越高。
华为昇腾是国内目前唯一在训练场景具备接近国际水平算力密度的国产GPU方案。
DeepSeek V4选择或被迫转向昇腾,无论主动还是被动,都代表了一条「国产算力+开源模型」的完整技术栈探索。
如果V4最终证明了这条路可行——即用昇腾训练出与使用英伟达芯片相近水平的SOTA模型——那美国芯片禁令的政策效果将面临根本性重估:禁的是芯片,但挡不住算法优化和工程适配。
反过来,如果V4跳票的根因真的是昇腾适配难度远超预期,那这条路的技术代价也比市场预期的要大得多。

这锅该算力背,还是工程能力背?
黄仁勋说它是「对美国的灾难」,动了谁的蛋糕?
从算力禁令到绕道传言:DeepSeek的芯片困境
黄仁勋那句「灾难」的原话背景值得还原。2025年1月R1发布后,他在英伟达2025财年Q4财报电话会上被分析师问到这个问题。
他的原话大意是:DeepSeek展示了算法效率的重要性,美国AI行业必须持续投入算力以保持领先;R1的出现不会改变英伟达的长期增长逻辑,但确实提醒了市场「算力需求的多样性」。
翻译成大白话:黄老板在安抚投资人,但语气里明显有一丝被刺痛的感觉。毕竟6000亿美元市值单日蒸发不是小事。
更深层的逻辑是:英伟达的估值体系建立在「AI训练需要大量GPU」这个前提上。
如果开源模型(DeepSeek系列)+高效算法让这个前提松动,哪怕只是松动5%,在英伟达当前40倍以上的PE倍数下,市场也会放大解读。
华尔街在怕什么:V4可能再次冲击美股
2025年1月R1的市场冲击逻辑是:开源替代→算力需求预期下降→英伟达估值承压。
这个逻辑链在R1发布后立刻兑现了,但后来有几个因素让它没有形成持续下跌:一是R1发布后OpenAI、Google等公司跟进更激进的产品迭代,市场把「AI竞争加剧」解读为「算力需求总量不减反增」;
二是DeepSeek的技术优势没有持续扩大,R1的领先窗口被快速追平。
V4的增量风险在于:如果它最终成功,并且证明国产算力+开源模型可以稳定复现SOTA水平,那这就不是「某一家公司的技术突破」了,而是一条可以被复制的技术路径。
路径一旦可复制,就会有第二家、第三家、第一百家中国AI公司跟进,量变到质变,美国芯片禁令的政策效果就会出现系统性折扣。
这不是危言耸听,而是可以推演的商业逻辑:英伟达数据中心业务里中国区的占比、国产替代的进度、昇腾的量产能力,这三个变量会共同决定「禁令效果重估」的幅度。
金融圈实测:AI选股能力已经让交易员紧张了
说完了芯片博弈,再看一个更直接的金融应用场景。
AI量化交易已经不是新闻了。
2024年到2025年间,Two Sigma、DE Shaw、Millennium等头部对冲基金都已在策略研究流程里引入大模型辅助,方向主要是:海量研报快速摘要、自然语言策略思路验证、另类数据(卫星图、舆情)处理。
目前AI在量化领域还是扮演「助理」角色,核心策略决策由人类PM把关。
但「助理」角色也在快速侵蚀「卖方分析师」的岗位空间。卖方分析师的核心工作是读研报、整数据、写报告——这三件事大模型都能做,而且做得更快、更全、更便宜。
国内某头部券商研究所2025年已经开始试点「AI研报助手」,一个模型能覆盖几十个行业的每日信息追踪,报告生成时间从几个小时压缩到几分钟。
DeepSeek V4如果能在金融场景里拿出有竞争力的长上下文处理能力(处理一整年的财报、产业链上下游数据、宏观经济指标),加上百万上下文和多模态支持,它在金融场景的渗透速度会比R1快得多。
届时「AI取代分析师」就不再是段子,而是实实在在的预算压力了。
所以我现在是该焦虑AI,还是该焦虑V4跳票?
DeepSeek V4适合谁用?现在要不要等?
这三类人值得等
第一类:需要100万token长上下文的用户。 这个规格目前主流模型里几乎没有直接对标产品。
如果你的工作涉及处理大部头技术文档、法律合同审计、超长代码库分析,100万上下文不是一个锦上添花的数字,而是一个从0到1的能力跃迁。
等V4发布后的真实评测确认长上下文质量可用,这个场景值得切过去。
第二类:对推理成本极度敏感的企业用户。 MoE架构+35倍推理加速如果属实,意味着同等性能下的推理成本可能比V3降低一个数量级。
对于日均调用量在百万token级别的to B企业,这个成本差距直接关系到商业模型是否成立。
**第三类:关注国产技术栈的工程师和求职者。
** 如果你所在的公司正在做昇腾迁移、或者你的目标岗位要求掌握国产AI工具链,V4会是第一个完整跑通「昇腾+开源SOTA模型」生产级案例。
吃透它的技术文档和踩坑记录,比刷一百道LeetCode对职业发展的帮助更具体。
如果你现在就在用V3/R1,要不要切换
一个实用的决策框架:
切换信号:V4正式发布 → 权威第三方评测(不是官方宣传稿)证实性能显著提升 → 评测里长上下文通过了真实任务测试 → 推理成本和延迟符合你的业务需求
不切换信号:V4跳票持续超过6月 → 华为昇腾的生产级部署案例反馈不稳定 → 你现有的V3/R1工作流已经稳定运行、没有明显瓶颈
技术选型最忌讳的是「因为恐惧错过」去做切换,而不是「因为真实收益」去做切换。
留给读者的问题:国产算力+开源模型,这条路能走多远
这篇文章写到这里,给了很多信息,但核心问题只有一个:
DeepSeek V4最终能否证明——用华为昇腾而非英伟达芯片,能够稳定训练并部署SOTA水平的开源大模型?
如果答案是肯定的,那这不只是DeepSeek一家公司的胜利,而是整个「美国芯片禁令框架」有效性的系统性质疑。
如果答案是否定的——跳票继续延期,或者最终性能不如预期——那「国产算力+开源模型」的完整技术栈还需要再等几年。
无论哪种结果,V4的发布都将是2026年AI行业最重要的单一变量之一。
你现在的判断是什么?是继续等,还是有更重要的仗要打?

搬砖去了,V4出了记得踢我一脚
风险提示与免责声明:本文仅基于公开资料讨论公司公告、技术投入与行业信号,用于研究和信息分享,不构成投资建议,也不作为投资依据。