你在实习里接到的第一个正式需求,是一个需要调用6个后端接口、完成数据聚合再写回数据库的多步骤任务。用ReAct写完demo,跑了三遍没问题,review也过了。
上线第一天,任务跑飞了——不是因为接口报错,而是Planner(也就是模型自己)在第4步开始胡来:它觉得第3步返回的数据"看起来不太对",决定自己先处理一下再往下走,结果越绕越远,最后栈溢出。

屏幕一红,心率先上去了
这不是你的prompt写得烂,是ReAct天然的设计缺陷:它把「想」和「做」耦合在同一个循环里,一旦任务稍微长一点,规划能力就被实时推理吃干净。
这一段,懂的都懂
是的,上线第一天,任务跑飞了

看到这里,人先沉默了
这个翻车场景在2026年的大厂面试里被反复提起。
GitHub上那套373道题的AI面试指南在2026年4月30日更新到v3.86,专门在ReAct与推理范式这个模块下新增了Plan-and-Execute的追问链——有经验的面试官发现,能讲清楚「为什么规划需要独立出来」的候选人,通常在系统设计上也更有判断力,而不是只会背概念。

背概念和真正理解,中间隔着一整个线上事故
从一个翻车现场说起:ReAct为什么撑不住长任务
ReAct(Reasoning + Acting)的核心循环非常优雅:模型接收任务 → 生成一个思考 → 调用一个工具 → 观察结果 → 进入下一轮。
这个循环在小任务里几乎是完美的:步骤少、依赖关系简单,模型可以在每一次tool call的间隙顺带完成「规划」,不需要提前知道全局路径。
问题出在步骤数超过某个阈值之后。这个阈值因模型能力而异,但经验数据指向一个共同区间:8到12步。超过这个范围,三个问题开始同时爆发。
**第一个问题:规划能力被实时推理吃干净。
** 每一次tool call之后,ReAct需要模型同时做两件事:理解当前状态(observation),和决定下一步做什么(action)。
当模型已经生成了5到6步的思考链时,上下文窗口里积累的中间状态已经开始稀释模型的「规划专注度」。
这不是记忆问题,是注意力分散——模型在第7步的思考里,还要同时操心「第3步的数据是不是有问题」「第5步的调用参数是不是对的」,真正的决策质量断崖式下跌。
第二个问题:错误传导没有恢复机制。 ReAct循环里没有「回退到规划层」的概念。
一旦某一步因为环境变化(前序接口返回值变了、依赖数据被外部修改)产生偏差,模型的选择只有两个:要么硬着头皮继续,要么在错误的方向上多走几步才发现走不通。
整个执行过程没有「规划-验证-重规划」的闭环,只有「行动-反馈-再行动」的单线程。
**第三个问题:资源消耗无法提前评估。
** 假设一个任务需要调用15次工具,每次tool call平均消耗3000个token的上下文,在ReAct模式下,你只有在跑完全程之后才能知道总消耗是多少。
在需要提前做成本预估的合规场景或生产环境里,这种不确定性本身就是风险。
大厂面试里关于Plan-and-Execute的追问,通常不是问你「Plan-and-Execute是什么」,而是给你一个具体场景让你判断:「这个任务应该用ReAct还是Plan-and-Execute?
」——能给出有判断依据的答案,前提是你真的理解ReAct在哪里开始失效。
Plan-and-Execute的核心架构:规划循环与执行循环为何必须分离
Plan-and-Execute(规划-执行)的基本思想非常直觉:先把要做的事想清楚,再动手做。但工程实现远比这句话复杂。
它不是简单地在ReAct外面套一层while循环,而是把整个执行模型拆成两个各自独立的子循环——规划循环和执行循环——它们以状态共享的方式协作,但各自维护自己的调用链。
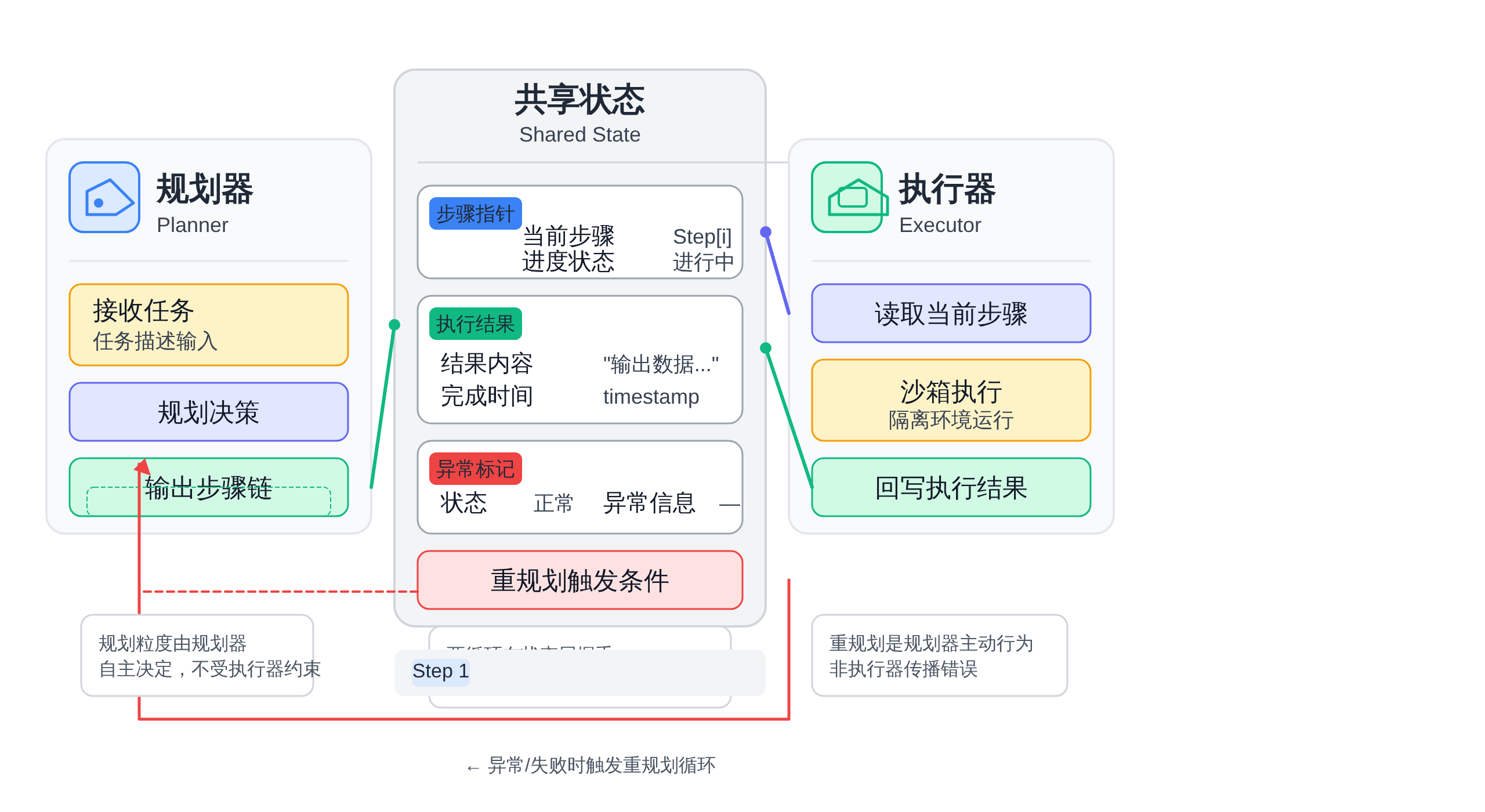
正文图解 1
这个架构的核心价值在于:把「生成任务步骤」和「执行任务步骤」交给不同稳定性的组件。
Planner可以是大模型,Executor可以是确定性脚本或另一个模型,但它们不再争抢同一个注意力资源。
规划时不用操心执行细节,执行时不用重新想「接下来应该做什么」——这本该是计算机科学里早就解决的关注点分离问题,只是在Agent语境下重新出现了一次。
规划器(Planner):生成可验证的任务步骤链
Planner的职责边界很清晰:接收任务描述,输出一个有序的步骤列表,每个步骤至少包含动作类型、目标工具、输入参数。在工程实现里,这通常表现为一个结构化的输出格式:
# Planner 输出示例
{
"step_number": 3,
"action": "query_database",
"tool": "sql_executor",
"params": {
"query": "SELECT * FROM orders WHERE user_id = ?",
"args": ["${user_id_from_step_1}"]
},
"expected_output": "list of order records",
"dependencies": ["step_1"] # 前置步骤依赖
}
规划粒度是第一个设计决策点。 粒度过粗(比如只规划3步,每步都是一个高层目标),Executor在执行时需要自己补全中间逻辑,等于把规划浪费了。
粒度过细(把每一步都拆到单个tool call),Planner的token消耗爆炸,而且一旦环境变化,细粒度规划的容错空间几乎为零——改一行参数,整条计划作废一半。
一个实用的经验法则是:让Planner规划的粒度等于「一个人看懂了能直接执行」的粒度。
如果Planner输出的是「获取用户画像」而不是「先查user表、再查profile表、再聚合」,Executor要么需要另一个模型来补全细节,要么会直接选择一个默认路径然后跑偏。
规划稳定性与模型能力高度相关。GPT-4级别以上的模型,通常能在5-10步的规划里保持较高的步骤正确率;
但即使是同一个模型,当任务的前置条件不确定时(比如依赖外部数据源的具体schema),规划质量也会断崖式下降。这是面试中「追问Plan-and-Execute局限性」的高频切入点。
执行器(Executor):在隔离环境中忠实执行步骤
Executor的哲学和Planner完全相反:不思考,只执行。给定第N步的完整描述,Executor按照描述执行,如果成功就把结果写回共享状态,如果失败就上报异常并携带足够的诊断信息。
这里最关键的工程设计是sandbox隔离。Executor运行在受限环境里,只能访问Planner在当前步骤里明确授权的工具和数据源,不能自己决定去调用额外的辅助工具。这个约束有两个价值:
第一,防止错误传导。假设Executor在执行第3步时发现某个边缘情况,它不能自己决定「我先去查个东西再回来」,这条路径必须在Planner的步骤链里预先规划好。
如果Planner没规划,那就是一个需要触发重规划的异常,而不是一个可自愈的行为。
第二,支持可恢复性。
当Executor执行第5步失败时,checkpointer已经记录了前4步的完整执行结果和状态快照,重规划时可以只针对第5步之后重新生成步骤链,而不是从头开始。
腾讯云那篇2026年4月的Agentic状态机文章里专门分析了这一层——在90%以上的实际生产场景里,步骤失败往往只影响局部,checkpointer是避免「一步错、步步错」的关键基础设施。
所以sandbox不只是安全考虑,也是可恢复性的前提
Executor上报异常的时机选择也有讲究。常见的三种策略:
立即上报:工具调用失败、参数校验失败、依赖数据缺失,直接停当前步骤,回写State触发重规划。适合步骤之间强依赖的场景。
批量上报:执行完N个步骤后统一汇报,降低重规划频率,但增加了故障定位难度。适合步骤之间相对独立、失败成本低的场景。
可配置阈值上报:允许Executor在连续N次同类异常后自动降级,而不是每次都触发重规划。适合长链路里偶发的边缘情况,避免过度反应。
面试中如果被问到「Executor挂了怎么办」,标准答案是「看挂的位置」:如果是环境异常(工具不可达、超时),立即上报;
如果是工具返回值不符合预期,需要先判断是Planner的规划问题还是Executor的执行问题,再决定是重规划还是重试。
面试核心:Plan-and-Execute vs ReAct vs ToolLoop三范式横评
能讲清楚三个范式的适用边界,说明你对Agent架构的理解不是从「哪个火学哪个」来的,而是真的在项目里对比过、权衡过。
ReAct的核心优势是实时响应:每一步都在根据最新观察调整下一步行动,不需要提前知道全局路径。
这使得它在探索性任务(比如「先查查这个API返回什么,再决定怎么用」)和步骤数少于8步的短任务里几乎不可替代。
ReAct的致命弱点我们前面说过了:长任务下规划质量衰减,以及缺乏可恢复性机制。
ToolLoop(或者叫Tool-Use Loop)是比ReAct更扁平的范式:模型在一次调用里决定多个工具的调用顺序,生成一批tool calls,批量执行,再接收结果。
没有中间的thought环节,也没有单步observation。ToolLoop的优势是token效率高:减少了每步的思考开销,在工具调用成本敏感的场景下有明显优势。
但它失去了「每步都能基于最新观察调整策略」的能力——一旦前序tool call的返回值变了,后面的调用可能全部失效,模型没有机会中途修正。
Plan-and-Execute的核心优势是全局规划能力与执行稳定性的解耦:Planner在执行前生成完整的步骤链,Executor在执行中忠实遵循步骤,不引入额外的不确定性。
这使得Plan-and-Execute在需要提前审计执行路径(合规场景)、成本预估(预算有限的生产任务)、以及步骤依赖关系复杂的场景里表现最优。
但它也有代价:规划本身需要额外的token消耗,而且Planner生成的计划可能因为环境变化而过时,需要有重规划兜底。
| 范式 | 步骤数上限 | 实时调整能力 | token效率 | 可恢复性 | 典型场景 |
|---|---|---|---|---|---|
| ReAct | <10步 | 强 | 中 | 弱 | 探索性任务、短链路对话 |
| ToolLoop | <15步 | 弱 | 高 | 中 | 批量工具调用、低成本场景 |
| Plan-and-Execute | 无硬性上限 | 依赖重规划 | 规划阶段偏高 | 强(checkpointer) | 长链路、合规审计、依赖复杂的任务 |
决策矩阵:什么时候选Plan-and-Execute
不是所有任务都需要Plan-and-Execute。
引入双循环架构本身是有代价的:代码复杂度上升、checkpointer需要额外维护、Planner和Executor之间的状态契约需要设计清楚。
如果你用Plan-and-Execute做了一个5步任务,等于用一套精密的外科手术器械撬开了一个只需螺丝刀的场景。
第一个判断条件:步骤数是否超过10步且存在依赖关系。 如果任务可以自然地拆成若干相互独立的短步骤,每个步骤的输入不依赖前序输出,ToolLoop往往更合适。
如果步骤之间有数据依赖(前一步的输出是后一步的输入),Plan-and-Execute的规划层可以提前把这些依赖关系编码进步骤链里,Executor不需要运行时再推导。
**第二个条件:是否需要提前评估资源消耗。
** 在Anthropic的Claude Managed Agents和OpenAI的Agents SDK更新(2026年4月)里,企业级Agent平台的计费模式都在向「可预期的运行成本」方向收敛。
Plan-and-Execute的规划阶段可以提前估算步骤数和工具调用次数,这在需要做预算控制的合规场景里是硬需求,而不是锦上添花。

面试官往往在这里埋一个追问:怎么估算?
**第三个条件:human-in-the-loop的介入节点设计。
** 如果任务需要在关键步骤暂停等人工确认,Plan-and-Execute天然支持这个模式:Executor在执行到某个步骤之前上报State,Planner等待人工输入后再生成后续步骤链。
ReAct的human-in-the-loop需要把人工输入插入到observation流里,破坏了循环的结构完整性,而Plan-and-Execute只需要在State里加一个字段标记「等待人工确认」。
工程落地:LangGraph实现Plan-and-Execute的最小代码结构
讲到这里,面试已经从「概念理解」进入了「工程实现」阶段。能写出可运行的最小实现,比能画架构图更有说服力——这说明你真的动手做过,而不是只在脑子里想过。
LangGraph是实现Plan-and-Execute的主流框架,它的优势在于状态图的结构天然支持「规划节点→执行节点→判断节点→重规划边」这套双循环模型。以下是一个经过实战验证的最小结构:
from langgraph.graph import StateGraph, END
from langchain_openai import ChatOpenAI
from typing import TypedDict, List, Optional
class PlanExecuteState(TypedDict):
original_request: str
plan: List[dict] # Planner 生成的步骤链
current_step: int # 当前执行到第几步
step_results: List[dict] # 每步的执行结果
error: Optional[str] # 异常信息,触发重规划
needs_replan: bool # 是否需要重新规划
# ========== Planner 节点 ==========
def planner_node(state: PlanExecuteState) -> dict:
"""接收任务,生成步骤链,写入 state['plan']"""
llm = ChatOpenAI(model="gpt-4o")
prompt = f"""任务:{state['original_request']}
当前执行进度:已完成 {state['current_step']} 步
历史结果:{state['step_results']}
请生成接下来的执行计划,返回 JSON 格式的步骤列表。"""
response = llm.invoke(prompt)
# 结构化解析步骤链
steps = parse_steps(response.content)
return {"plan": steps, "needs_replan": False}
# ========== Executor 节点 ==========
def executor_node(state: PlanExecuteState) -> dict:
"""从 state 读取当前步骤,在 sandbox 中执行"""
current = state['plan'][state['current_step']]
try:
result = execute_in_sandbox(
tool=current['tool'],
params=current['params']
)
step_results = state['step_results'] + [{
"step": state['current_step'],
"output": result,
"status": "success"
}]
return {
"step_results": step_results,
"current_step": state['current_step'] + 1,
"error": None
}
except ExecutionError as e:
return {
"error": str(e),
"needs_replan": True # 触发重规划
}
# ========== 判断节点:是否继续执行 ==========
def should_continue(state: PlanExecuteState) -> str:
if state.get('needs_replan'):
return "replan" # 回到 planner
if state['current_step'] >= len(state['plan']):
return END # 计划执行完毕
return "execute" # 继续执行下一步
# ========== 构建图 ==========
graph = StateGraph(PlanExecuteState)
graph.add_node("planner", planner_node)
graph.add_node("executor", executor_node)
graph.set_entry_point("planner")
graph.add_conditional_edges(
source="executor",
path=should_continue,
path_map={
"replan": "planner", # 重规划:回到 planner
"execute": "executor", # 继续执行下一步
END: END # 正常结束
}
)
app = graph.compile()
规划节点的prompt设计陷阱
这个最小结构能跑,但工程里真正出问题的地方往往在prompt设计。三个高频踩坑点:
粒度过细导致token爆炸。 有些工程师习惯让Planner输出「step 1.1、step 1.2、step 2.1」这种嵌套粒度,以为越细越好。
实际上,Planner生成的步骤越多,规划token消耗线性增长,而且Executor在执行时需要频繁地在节点之间切换,上下文窗口里积累的中间状态反而降低了执行效率。
合适的粒度是「一个步骤等于一次工具调用加上它必要的参数准备」,不要把工具调用的内部逻辑再拆进规划层。
**角色混淆引发的循环调用。
** 最常见的错误是把Planner和Executor的prompt写得太相似,导致模型在Planner节点里开始执行,在Executor节点里又开始规划。
两个节点必须职责边界清晰:Planner的输出是步骤描述,Executor的输入是步骤描述,两者在语义层面不要有重叠。
如果你在Executor的prompt里写了「思考一下是否需要调用额外的工具」,Executor大概率会在没有规划授权的情况下自己去调用辅助工具,破坏sandbox约束。
**缺乏验证节点的风险链式传导。
** Executor每步执行完后,标准实现会在下一个循环开始前加入一个轻量级的「结果验证」逻辑:如果当前步骤的输出格式或值域不符合Planner的预期,直接标记为异常并触发重规划。
没有这层验证,错误的输出会流入下一步的执行,可能需要走好几步才发现有问题,白白浪费token不说,还可能产生副作用(比如写入了错误的数据)。
**缺乏验证节点的风险链式传导。
** 没有这层验证,错误的输出会流入下一步的执行,可能需要走好几步才发现有问题,白白浪费token不说,还可能产生副作用——比如写入了错误的数据,或者调用了依赖前置状态的错误接口。
`

这条边的设计最容易被面试官追问
`
面试高频追问:这些变形题该怎么答
面试官追到这里,问法通常有三个方向:缺陷追问、架构对比、项目落地。三个方向各有坑点,也各有可以出彩的机会。
追问1:Plan-and-Execute的最大缺陷是什么
大部分候选人能说出「规划开销大」或「实时调整能力弱」,这两点确实是缺陷,但不是最深的那层。
最核心的缺陷是规划与执行之间的信息滞后。 Planner 生成计划时依据的是当前环境状态,但环境会随着 Executor 的执行而变化。
举一个具体场景:第一步执行改变了数据库中某个字段,第二步 Planner 原本的假设已经不成立了。
如果 Planner 没有在每个执行循环开始前做一次环境状态重新评估,整个计划的有效性就会逐渐衰减。
增量规划和滚动窗口规划是两种缓解手段。增量规划允许 Planner 基于已有执行结果修正后续步骤,而不是完全推翻重做;
滚动窗口规划只规划最近 N 步,保持灵活性同时控制 token 消耗。
Anthropic 在 2026 年 4 月发布的 Claude Managed Agents 文档里就明确提到了「error recovery mechanism enables agents to pick off where they left off after an outage」,这个机制本质上就是增量重规划的工程实现。
如果面试官追问「那为什么还要用它」,回答的结构应该是:Plan-and-Execute 的价值是在「执行可预测性」和「长链稳定性」上,这两点在合规审计和预算控制场景里是硬需求,实时调整能力的损失是可以用重规划兜底的。
追问2:ReAct加个规划层是不是就变成Plan-and-Execute了
不是。两层循环在状态管理上有根本差异。
ReAct 是单循环:每一步的 observation 直接影响下一步的 action,循环没有断点。
Plan-and-Execute 是双循环:Planner 输出计划,Executor 执行计划,两个循环之间通过 State 传递信息,但 Executor 的执行结果不会直接改变 Planner 的决策路径——除非显式触发了重规划边。
这个区别的工程含义是:ReAct 的每一步都可以基于最新观察修正策略,但 Plan-and-Execute 的 Planner 默认是「盲眼」的,它依赖 Executor 上报的状态而不是自己的实时感知。
从 ReAct graph 迁移到 Plan-and-Execute graph 的核心改动点有三个:把原来扁平的 Tool-Use 节点替换成「规划节点 → 执行节点 → 判断节点」的结构;
引入 needs_replan 和 error 两个状态字段;把原来单步 observation 的反馈路径切换成判断节点的条件分支。
不是说加了一层 prompt 就能完成迁移,这两个状态契约完全不同。2
`

这个区别最容易在追问里被追问
`
追问3:如何结合项目经历回答Plan-and-Execute的选型理由
没有真实项目的情况下,关键是展示「观察—判断—调整」这条思维链,而不是硬编一个没做过的系统。
回答框架通常是三层:任务特征描述 → 试过其他方案 → 为什么最终选了这个。
任务特征描述要找具体的维度:步骤数有没有超过 10 步?步骤之间有没有数据依赖?执行环境稳不稳定?有没有需要人工介入的关键节点?这些特征比「任务很复杂」要具体得多。
试过其他方案要诚实:「我们先试了 ReAct,在第 8 步之后发现模型开始重复之前的思考路径,checkpointer 也救不回来」比「ReAct 不适合复杂任务」要有说服力得多。
选型理由要落回具体的权衡:选了 Plan-and-Execute 之后,planner token 消耗上升了多少?重规划触发了多少次?这些数据比「因为它更先进」要管用。
如果你是本科生或研究生,没有生产级项目经验,可以讲课程项目或者 demo 改造:比如把一个多步骤的自动化脚本改成了 Plan-and-Execute 结构,遇到了什么问题,后来怎么解决的。
面试官看的是你「有没有真正动手过」,不是项目规模大小。
实战图解:Plan-and-Execute的状态流转与异常处理
下面的状态流转图展示了完整的执行路径与异常处理路径。
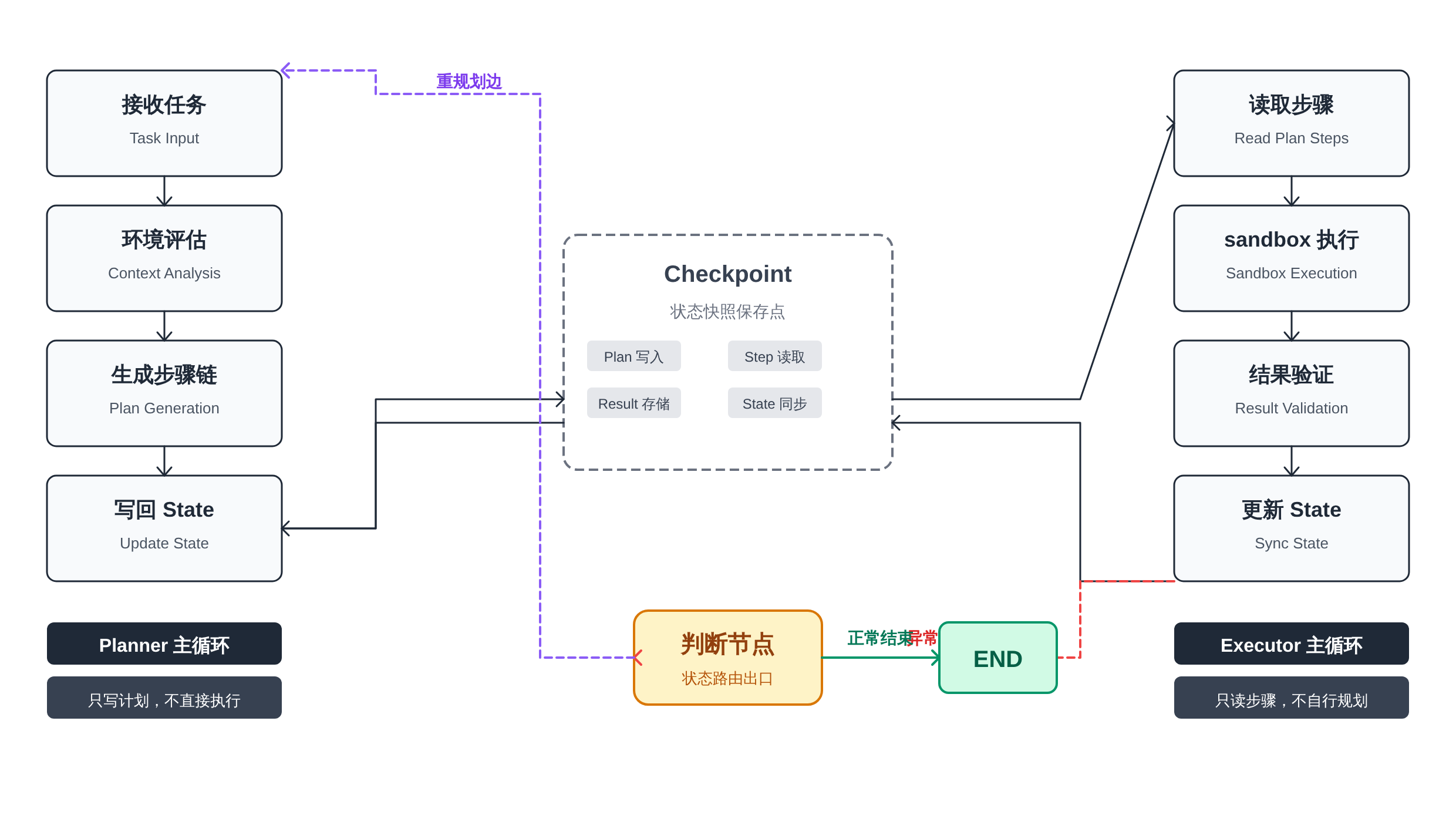
正文图解 2
这张图的核心信息是三层:
循环边界。 Planner 和 Executor 是两个职责完全不同的循环。Planner 接收任务和环境状态,输出步骤链;
Executor 接收步骤链,忠实执行,不做额外的推理决策。两个循环之间靠 State 传递信息,不靠直接的函数调用。
异常路径。 Executor 执行出错时,先上报 error 字段和 needs_replan=True,不直接回到 Planner——先经过判断节点。
如果判断节点认为这个异常可以重试(比如网络超时),可以继续当前步骤;如果认为需要重新评估计划,才触发重规划边回到 Planner。
这种分层设计比「一出错就全部重来」要节省大量 token。
**Checkpoint 的位置。
** Checkpoint 保存的是完整的 PlanExecuteState,包括 original_request、plan、current_step、step_results 和 error。
保存点放在 Planner 和 Executor 之间的交界处,这样无论是从 Planner 崩溃恢复还是从 Executor 崩溃恢复,都可以从最近的一致状态开始,不需要从头走一遍已经成功的步骤。
`
面试官往往会顺着这张图追问:判断节点怎么设计?
`
判断节点的设计细节是面试里最容易被追问的地方。
常见的判断条件至少有三个:当前步骤是否执行成功、是否触发了重规划条件(环境变化、工具不可用、执行超时)、计划是否已全部完成。
前两个条件决定走向,第三个条件决定是否结束。双循环结构的优势在这个节点上体现得最清楚——所有路由决策都集中在一处,不会有多个循环各自为政的混乱。
参考文献与推荐阅读
1 Anthropic launches Claude Managed Agents to speed up AI agent development — Claude Managed Agents 的 error recovery 机制本质是增量重规划,工程实现路径与 Plan-and-Execute 一致。
3 LangChain/LangGraph 官方文档 — 状态图结构支持规划节点、执行节点与条件判断边的组合,Planner-Executor 双循环模型有完整 API 文档。
4 Agentic状态机设计:实现可控的复杂任务执行 — 腾讯云开发者社区 2026-04-20 的状态机设计文章,防循环策略与异常处理路径与本文状态流转图对应。
5 OpenAI updates its Agents SDK to help enterprises build safer, more capable agents — OpenAI Agents SDK 2026年4月更新,引入了 sandbox 隔离能力和 in-distribution harness,这两个特性与 Plan-and-Execute 的 Executor sandbox 设计高度相关。
6 AI 应用开发工程师面试宝典 — GitHub v3.86 版本(2026-04-30),373+ 道高频面试题,24 个核心模块,系统覆盖 Agent 框架、推理范式与状态机设计。
2 2026年Agent大厂面试题汇总:ReAct、Function Calling — 知乎专栏,ReAct 与 Function Calling 的面试追问路径整理。
面试要点速记:Plan-and-Execute 的五条核心判断
整理成面试现场能直接开口说的五条判断,不要背定义,要背判断句:
看到这里,人先沉默了
第一条:什么时候必须用 Plan-and-Execute。 步骤数超过 10 步、步骤之间有数据依赖、执行结果需要提前做合规审计。满足任意两条就可以考虑。

程序员的日常,多少带点离谱
**第二条:ReAct 和 Plan-and-Execute 的本质区别。
** 单循环 vs 双循环,ReAct 每步都基于最新观察修正策略,Plan-and-Execute 的 Planner 默认是盲眼的——它依赖 Executor 上报的状态,而不是自己的实时感知。
这个区别在面试里几乎是必考的。
第三条:Executor 为什么必须在 sandbox 里跑。 不是为了安全,是为了可复现。
sandbox 保证了每次执行的环境一致性,没有它,checkpointer 恢复出来的状态是不可信的。
第四条:判断节点是唯一的状态路由出口。 所有重规划边、继续执行边、正常结束边都必须经过它。不要让 Executor 自行决定下一步该做什么,职责边界要清晰。
**第五条:Planner 最大的坑是粒度控制。
** 「step 1.1、step 1.2」这种嵌套粒度是最常见的错误,Planner 的输出应该等于一次工具调用加上它必要的参数准备,不要把工具内部逻辑拆进规划层。
这五条能覆盖 80% 的面试追问方向。剩下的 20% 靠项目经历补,具体怎么讲,见前文「追问3」的框架。