摘要:ToT不是ReAct的简单加强版,而是把推理空间从线性链变成树状搜索。
有个朋友上周跟我吐槽:他面一家自动驾驶公司,简历上写着「熟悉ReAct范式」,面试官顺着问了一句「那你了解ToT吗,ToT和ReAct最大的区别是什么」。
他当场卡了大概五秒,然后说:「ToT好像是ReAct的多步加强版?」面试官没说话,但那个沉默比他答错还难受。
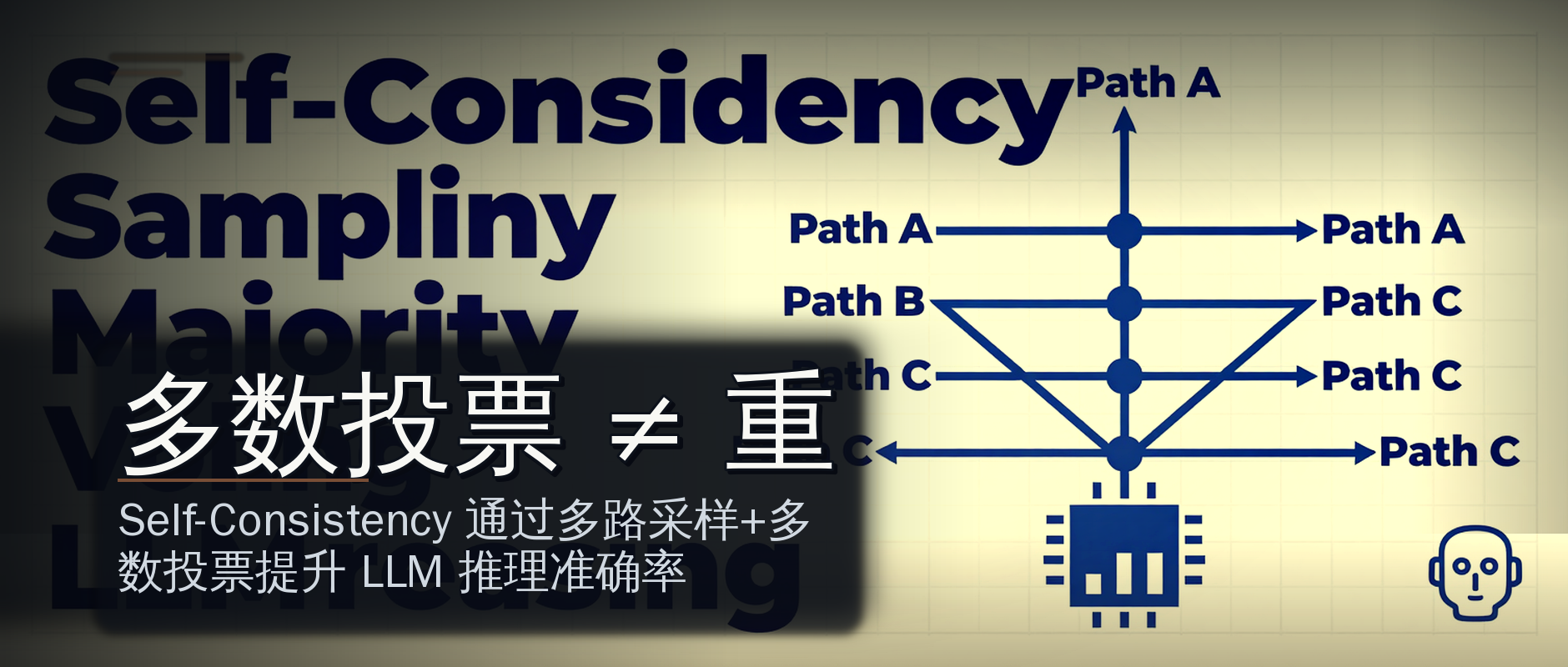
问题不在于他不懂——在于他把ToT理解成了「ReAct多走几步」这个量变,而ToT真正改变的是推理结构的质变:ReAct的输出是一条线,ToT的输出是一棵树。
这两个东西不是一个概念的两种实现,而是两个不同层次的东西。
这篇文章就是要把ToT讲清楚:不只是定义,还要拆开来告诉你节点里存什么、树怎么长出来、评估函数怎么决定剪枝、BFS和DFS各自适合什么场景、LangGraph里怎么搭一棵能跑的ToT树,以及面试官真正会追问的那些点。

五秒沉默比答错更致命
为什么ToT是ReAct的自然延伸,而不是另一个独立概念
要理解ToT为什么是ReAct的延伸,先要理解ReAct的问题出在哪。
ReAct的核心循环是 Thought → Action → Observation,每一步只往前走一步,下一步的输入就是上一步的输出。
这套机制在简单任务上非常好用——搜索天气、查数据库、写代码,步骤不超过十步的时候,线性推理足够稳定。
但问题来了:如果任务本身有多条可能的解决路径呢?
比如让你「写一个推荐系统的冷启动方案」,这不是简单的一步一步执行,而是涉及到方向选择——先收集数据还是先定义指标?用协同过滤还是内容召回?
这些决策点有多个分支,每条分支都可能走得通,但成本和效果完全不同。ReAct在每个决策点只会选一条路走下去,没有能力同时探索多条路然后比较哪个更好。
ToT做了什么?它把每个决策点展开成多个子节点,每个节点代表一个候选的思考方向,然后通过评估函数对所有节点打分,保留得分最高的继续往下走。
这就是为什么说ToT是ReAct的延伸,而不是另一个东西:ReAct的骨架还在(思考→行动→观察),但现在每个Thought不再只出一条线,而是长出一棵树杈。
树的根节点还是问题本身,每个叶节点是一次完整的推理路径,终点就是答案。
用更学术的话讲:ReAct是一种线性规划(Linear Planning),ToT是一种树搜索(Tree Search)。
前者假设每一步只有一个最优选择,后者承认每一步可能有多个选择,然后通过评估和剪枝来找到真正最优的那条。
树搜索才是本体,线性规划是特例
ToT树结构的三个核心构成:节点、状态与评估函数
一棵ToT树能跑起来,依赖三个核心要素:节点(Node)、状态(State)、评估函数(Evaluate)。这三个东西缺一不可,面试时也经常围绕它们展开追问。
状态定义:每个节点存什么
在LangGraph的实现里,每个树节点本质上是一个State快照,包含了到这一步为止所有中间信息。一个典型的ToT状态大概长这样:
class ToTState(TypedDict):
problem: str # 原始问题
current_depth: int # 当前树深度
path: list[str] # 从根到当前节点的路径(文本序列)
nodes: list[TreeNode] # 当前候选节点列表
scores: dict[str, float] # 节点ID到评估分的映射
terminated: bool # 是否已经找到足够好的解
关键在于path:它不是简单记录「我思考了什么」,而是完整记录了从根节点到当前节点的完整推理链。这个链在后续评估时会完整参与打分,在节点被选中继续往下探索时也会作为上下文继续生成子节点。
节点转移:树怎么长出来
节点转移(Node Transition)有两种模式,对应两种搜索策略,见下一节。这里先说节点的生成逻辑。
每次ToT循环里,当前被选中的节点会经过一个Generate过程,LLM在这个节点的基础上生成多个候选子节点(通常3到5个)。
生成时通常会在prompt里加上策略指导,比如「请给出三种不同的解题方向,每种方向要有明显区分」。生成结果就是树的下一层节点。
生成的子节点不是全部保留,而是要经过评估之后才能进入下一轮。评估函数在这里发挥作用。
评估函数:剪枝的逻辑是什么
评估函数(Evaluation Function)是ToT里的核心决策组件。它的输入是一个候选节点的状态,输出是一个分数,分数越高说明这个分支越有希望。
评估函数的设计有几种常见策略:
基于LLM自评:让LLM直接对当前节点的解题质量打分,通常配合few-shot prompt给出评分标准和示例。
这种方式最简单,但评估本身的token消耗很大,而且评估结果依赖于LLM本身的能力。
启发式评分:设计规则化的评分函数,比如「方案覆盖的用户数」「算法复杂度」「实现成本」。适合有明确量化指标的子任务,但不适用于开放性问题。
混合评分:先用规则过滤明显不靠谱的节点(剪掉离题太远的分支),再用LLM对保留下来的节点打分。实际工程中这是最常见的做法,平衡了效率和准确性。
评估之后,低于阈值的节点会被剪掉(pruned),不再参与后续生成。高分节点进入下一轮,继续Generate出新的子节点。这个循环一直持续,直到找到足够好的解,或者达到最大深度/步数限制。
⚠️ 踩坑提醒:评估函数设计得不好,整个ToT就会退化——要么剪得太狠漏掉了正确答案,要么剪得太松导致搜索空间爆炸。
实际项目中评估函数通常是调出来的,不是设计出来的,多跑几组对比实验才能找到合适的阈值。

评估函数调不好,树会原地爆炸或者什么都不长
BFS vs DFS:什么时候该用宽度优先,什么场景下深度优先
ToT树的生长有两种基本搜索策略:BFS(广度优先搜索)和DFS(深度优先搜索)。这不是一个玄学选择,而是有明确工程约束的行为决策。
BFS适用场景与工程约束
BFS在一层的所有节点全部生成并评估完之后,才进入下一层。换句话说,它先横向展开所有可能方向,再逐层向下推进。
BFS的核心优势是全局视野:在所有第一层节点都被评估过之前,系统已经看到了所有方向的初始质量。
这对于需要找「最优解」而非「可接受的解」的场景特别重要——比如数学证明、搜索优化、解码类任务,越早找到全局最优的方向,后续浪费的计算越少。
但BFS的代价是token消耗翻倍甚至指数增长。每一层都要同时生成和评估所有节点,假设每层生成4个节点,3层树就有4³=64个节点,LLM调用量和上下文长度会快速失控。
实际工程中BFS通常配合严格剪枝使用:每层最多保留2到3个高分节点,不展开所有生成结果。
DFS适用场景与截断策略
DFS遇到一个节点就一路向下走到底,走不通了才回溯到上一个分叉点换一条路。这种策略的token消耗远低于BFS,因为同一时间只维护一条路径的上下文。
DFS适合的场景有几个特点:
正确性有判断标准:比如「只要找到一个能编译通过的方案就行」,DFS找到一个有效解就结束了,不需要遍历所有可能。
分支质量差异明显:如果不同方向的初始评估分数差距很大(比如一个0.9分,另一个0.3分),DFS先走高分路径的效率通常高于BFS的均衡展开。
计算资源有限:本地LLM调用、有QPS限制的API、边缘设备上的推理,BFS的开销往往不可接受,DFS是更务实的选择。
DFS的核心风险是截断策略(cutoff strategy):如果走到一半发现方向选错了,已经消耗了大量token和时间,但没有回退机制,就会陷入「死路走到黑」的困境。
工程上通常设置两个截断条件:最大深度限制(比如最多探索8层)和无进展步数限制(比如连续3步分数没有提升就回溯)。
追问:BFS token消耗翻倍怎么办
面试官喜欢追问这个问题,因为它考的是你有没有真正在工程层面考虑过资源约束。
标准答案是分层剪枝 + 提前截断:
Beam Search变种:每层只保留评估分数最高的K个节点(K通常取2到4),而不是展开全部。这种做法接近BFS的全局视野,但token消耗控制在K倍而不是指数倍。
预测性剪枝:用一个小模型对候选方向做快速初筛,只把通过初筛的节点交给大模型做完整评估。成本下降效果显著,但引入了额外延迟和初筛准确率的 tradeoff。
缓存复用:相同或相似的子问题在树的不同分支里反复出现,用一个短期缓存(如Redis)保存已评估过的节点结果,避免重复LLM调用。
这里的核心逻辑是:BFS的全局最优性是拿token换来的,工程上要判断这笔账值不值。对成本敏感的场景,Beam Search + 强剪枝的性价比通常高于纯BFS。

Beam Search就是用K换指数的那个K
从ToT到Graph-of-Thoughts(GoT):树不是终态
ToT虽然比ReAct灵活,但它仍然有一个隐含限制:树的结构不允许节点之间有横向关联。每个子节点只知道自己的父节点,不知道自己和其他分支的节点有什么关系。
真实推理过程中,很多子问题之间其实是相互依赖的:一个分支的结论可能是另一个分支的前置条件;两个分支探索到一定程度可以合并成一个更完整的答案。
这种横向关联树表达不了,这就是Graph-of-Thoughts(GoT)的动机。
GoT的核心扩展:节点合并与循环
GoT在ToT的基础上引入两个新机制:
节点合并(Aggregation):当两个不同路径探索到相似的中间结论时,系统会把它们合并成一个节点,后续推理基于合并后的统一结论继续向下。这避免了重复探索,也允许更复杂的跨分支信息流动。
循环(Cycle):树的结构是单向的——父节点生出子节点,子节点不再影响父节点。GoT允许子节点的结论反馈影响父节点的状态,相当于在树里加入了边,构成了一个有向图。
这意味着推理过程不再是一条单向链,而是一个可以迭代优化的闭环。
举一个具体例子:假设在解一道算法题时,一个分支探索了「动态规划方向」,另一个分支探索了「贪心方向」,两个方向各自推进到一定程度后,系统发现「动态规划的状态定义」可以作为「贪心证明」的关键引理,于是把这两个节点合并成一个新节点,这就是GoT的节点合并。
ToT/GoT在LangGraph中的实现边界
需要诚实说的是:LangGraph对ToT/GoT的支持是间接的,不是开箱即用的。
LangGraph的核心抽象是StateGraph和有向图,边是节点之间的转移关系,不原生支持「节点合并」或「循环回到父节点」这类GoT特有的图操作。
实现一个ToT需要自己维护节点列表和评估分数,通过条件边来模拟「评估→剪枝→继续」的逻辑。GoT的合并和循环就更难用LangGraph的原生API表达,通常需要额外维护一个合并状态和循环计数器。
这也是为什么有些团队会在LangGraph之上再封装一层ToT引擎,或者直接用NetworkX+LLM调用来构建更灵活的图结构。
面试时被问到「你用LangGraph怎么实现ToT」,要能说清楚这里的工程约束和折中方案。
LangGraph搭ToT不难,但要自己补很多边角逻辑
工程落地方案:LangGraph里怎么搭一棵能跑的ToT树
这一节给一个具体的实现框架,基于LangGraph的StateGraph,不只是概念,是能跑起来的节点设计。
正文图解 1
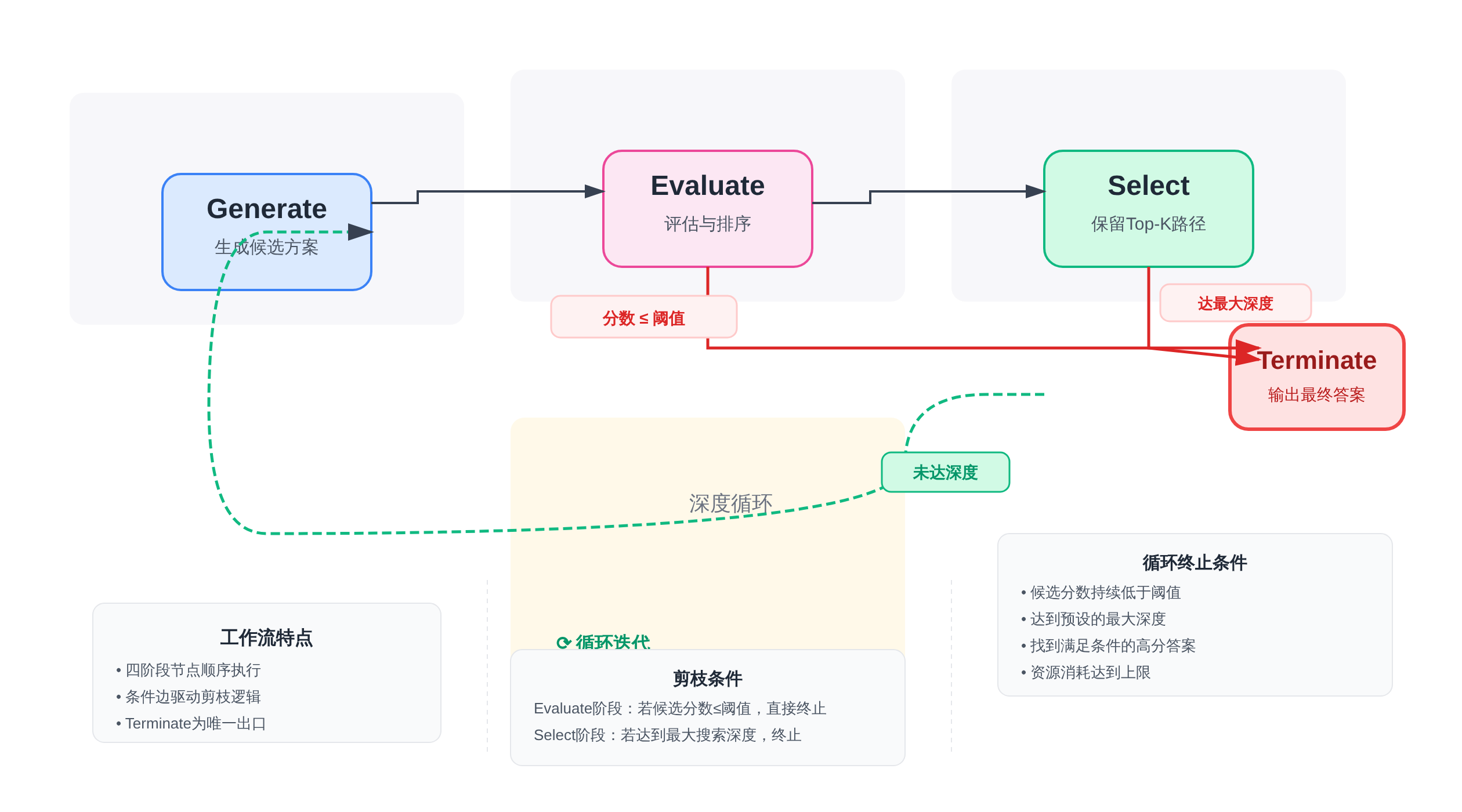
StateGraph节点设计:Generate → Evaluate → Select → Terminate
整个ToT工作流由四个核心节点组成:
Generate节点:接收当前状态中的nodes列表,调用LLM为每个候选节点生成子节点。
实现上通常用model.bind_tools把生成函数注册为tool,每次调用返回一个或多个新的思考路径。
这里有个细节:Generate不是对所有历史节点重新生成,而是在Select节点选出的「最有希望的节点」上单独生成,防止上下文无限膨胀。
Evaluate节点:对Generate输出的所有候选节点做评估打分。这个节点的核心是评估函数的设计——可以用规则(复杂度、覆盖度),也可以用LLM自评,或者两者结合。
评估结果更新scores字典,同时检查是否达到终止条件。
Select节点:根据评估分数对所有候选节点做排序,保留分数最高的K个(Beam Width),其余剪掉。
同时检查深度是否达到上限,如果达到就跳过Generate,直接进入Terminate。这里要特别处理「所有候选都被剪光」的边界情况——通常会回退到上一轮的最高分节点做备选。
Terminate节点:输出最终答案,同时写入终止标志。终止条件有两种:找到满足评估阈值的解(质量终止),或者达到最大步数限制(资源终止)。
两种终止都应输出,以便调用方判断结果是「找到了好方案」还是「资源耗尽」。
条件边路由:评估分数驱动的分支选择
LangGraph的条件边(conditional edge)在这里是核心机制。标准写法是:
from langgraph.graph import StateGraph
from typing import Literal
def route_after_evaluate(state: ToTState) -> Literal["select", "terminate"]:
"""评估后:如果最高分超过阈值就进入Select,否则Terminate"""
top_score = max(state.scores.values()) if state.scores else 0.0
if top_score >= state.config["score_threshold"]:
return "select"
return "terminate"
def route_after_select(state: ToTState) -> Literal["generate", "terminate"]:
"""选择后:如果还有深度空间就继续生成,否则终止"""
if state.current_depth >= state.config["max_depth"]:
return "terminate"
return "generate"
graph.add_conditional_edges("evaluate", route_after_evaluate)
graph.add_conditional_edges("select", route_after_select)
这种路由方式的好处是业务逻辑和图结构完全解耦:评估阈值、最大深度、Beam Width都在state.config里配置,修改不需要动图的拓扑。
checkpointer与长链路状态恢复
ToT树在深度较大时(比如20步以上的复杂推理),中途如果LLM调用超时、连接断开,或者需要暂停去人工检查中间结果,必须有状态恢复机制。
LangGraph内置的MemorySaver或RedisSaver可以解决这个问题。
在每个节点执行完毕后自动checkpoint当前状态,重启时从最近的checkpoint恢复,不需要从头开始。配置方式也很简单:
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver() # 生产环境换RedisSaver
app = graph.compile(checkpointer=checkpointer)
# 中断后恢复
thread_id = "user_session_123"
config = {"configurable": {"thread_id": thread_id}}
# 从断点继续执行
for event in app.stream(None, config):
pass
⚠️ 踩坑提醒:checkpoint恢复时要注意nodes列表的序列化。
复杂LLM返回对象(如带有工具调用的结果)可能无法直接JSON序列化,需要在checkpoint前做清洗预处理,把中间结果转成纯文本或dict格式再存。

checkpoint不好好处理,断点恢复时会收获一屏幕序列化报错
面试高频追问路径:ToT被追杀时怎么答
这一节整理六个最容易被追问的方向,每条都给出回答思路和具体的工程语境。
追问1:ToT和ReAct最大的区别
标准答案要落在推理结构上,不落在「步数」上。
参考回答:「ReAct的思考链是一条直线,每步只往前走一个方向。ToT把每个决策点展开成一棵树,每一步可以有多个并行的候选方向,然后通过评估函数筛选最优路径再继续。
这不是步数多少的问题,是推理空间从一维变成多维的问题。」
要能补一句:「ReAct适合步骤线性、每步只有一个最优选择的场景;ToT适合有多条可能路径、需要主动探索和比较的场景。」可以举例:数学证明类任务适合ToT,工具调用类任务ReAct通常就够了。
追问2:评估函数怎么设计
这里要展示工程思维,不是背概念。
参考回答:「评估函数的设计取决于任务类型。对有明确量化指标的任务(算法题、搜索优化),可以用规则函数——覆盖度、时间复杂度、得分提升幅度这些直接算出来。
对开放性任务(方案设计、文案生成),通常让LLM自评,配合few-shot prompt给出评分标准和示例。
我自己的经验是先用规则做粗筛,把明显离谱的分支剪掉,再对保留下来的节点用LLM细评分,这样token消耗可控。」
能再补一个tradeoff更好:「评估函数本身也有成本,如果每个节点都做完整LLM评估,评估的token消耗可能超过生成本身。所以工程上通常是规则预筛+LLM精评的混合方案。」
追问3:token消耗怎么控制
这道题本质是考你有没有在真实项目里跑过ToT。
参考回答:「三个方向。第一是Beam Search变种,每层只保留评估分数最高的K个节点,控制展开的节点数量。第二是预测性剪枝,小模型快速初筛后再上大模型精评,延迟换成本。
第三是缓存,已经评估过的相似子问题直接复用结果,不重复调用。实际项目中我会先用Beam Search+严格阈值,把每层的节点数控制在4以内,根据任务复杂度再动态调K值。」
不要只说「用Beam Search」,要能说清楚K怎么选、阈值怎么设,这是面试官真正想听到的工程细节。
追问4:项目里ToT比ReAct好多少
这道题没有标准答案,面试官想看的是你有没有在具体场景里做过对比实验,而不是泛泛说「好很多」。
参考思路:「我在做XX任务时,ReAct跑了20次,成功率大概XX%。
ToT在相同budget下(相同token消耗),成功率提升到XX%,但平均步数从X步变成了X步,延迟从X秒变成X秒。
核心收益是在有多个等价解的场景下,ToT找到最优解的概率明显更高,但代价是单次推理延迟增加了。」
如果自己没有做过对比实验,就说「看过相关论文的benchmark」——PlanBenc和PAstro的论文里有具体数据,可以引用。
易错点:把ToT说成「多走几步ReAct」
这是最容易踩的坑,也是面试官用来区分「背过概念」和「真的理解」的分水岭。
关键区别在于并行探索 vs 顺序执行:ReAct的每一步是顺序的,不存在「同时探索多个方向」这个操作;
ToT的每一步本质上是一个批量操作(生成N个候选→评估N个候选→选择K个保留),这是一个搜索策略,不是执行次数的差异。
如果被追问,可以反问面试官:「您说的是每步还是每层的概念?ToT的每层我可以理解为ReAct的每步,但ToT允许每步同时探索多个方向,ReAct不允许——这个理解对吗?
」展示理解的同时把球踢回去,也是一种有效的面试策略。

说「多走几步ReAct」,面试官心里已经打叉了
参考文献与延伸学习路径
Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models" (2023) — Google Research,ReAct原始论文,理解ToT为何是延伸的起点。链接
Long et al., "Large Language Model Planner: Enhanced Hierarchical Planning with Chain-of-Thought (CoT) and Strategies" — ToT思想的奠基工作,定义了树搜索在LLM推理中的应用框架。链接
Yao et al., "Graph of Thoughts: Making LLMs Clarify through Deliberate Reasoning" — GoT的核心论文,对比ToT和GoT的图结构扩展逻辑。链接
LangChain官方文档,"Introduction to LangGraph" — 官方文档里有关于StateGraph、条件边、checkpointer的详细示例代码,是LangGraph ToT实现的第一手参考。链接
BFS vs DFS在LLM规划中的对比分析 — LangChain Academy课程中关于搜索策略选择的讲解,提供了工程层面的决策框架。链接