
摘要:当 agent 的产出速度超过人类 review 的消化速度,质量风险从「写不出」变成「验不过」。
周二下午三点,你打开 Slack,看见 AI agent 提了一个 PR:diff 干净、commit message 规范、单元测试全绿。
但当你点进去细看,它把用户权限校验的逻辑从 RBAC 改成了一个布尔 flag,理由是「更简洁」。
这个 PR 过了 CI,但它真的能发吗1?
这就是 agentic delivery 进入工程团队后正在发生的真实张力。
以前风险是「agent 写不出」,现在风险是「agent 写得比你 review 得快,但你来不及判断它写的是不是对」2。
为什么 Agent 越强,质量门禁反而越急
Reddit 的 r/AI_Agents 社区最近有一条帖子在讨论一个很具体的问题:当 autonomous PR 开始规模化,human reviewer 到底在 review 什么3。
回复里有个说法很扎心:「你说这是 autonomous PR,但它只是更快地产生了不确定性。」这句话点出了当前 agentic delivery 的核心矛盾:生成速度提升后,风险从「写不出」转移到了「验不过」4。
这不只是一个主观感受,有数据可以佐证。
根据 AgenticCareers 网站上一位 AI Agent Engineer(网名 Priya)的现身说法,agent 工程师现在大约有 30% 到 40% 的时间花在 eval 相关工作上——构建测试集、写评估函数、跑回归套件、解读评分结果5。
这意味着 agentic delivery 的瓶颈已经不是生成速度,而是验证成本。

这 PR 全绿,但我心里不踏实
再往深处看一层,风险还来自「产出形式的变化」。传统的 human developer 提 PR,reviewer 面对的是一小块增量变更,背景信息隐含在上下文里,边界是清晰的。
但 agent 提的 PR 可能是:修改了基础设施模块、调整了依赖版本、顺手改了一个看似无关的配置文件。
这个 PR 逻辑上通过了 CI,但它改变了系统的隐式假设,而 CI 并不知道这些假设是什么。
金融合规场景更能说明这个问题。
根据 SmartOSC 的行业调研,金融客户引入 agentic AI 系统后,实际花在 evidence 收集和合规文档生成上的时间占到了 60% 到 80%,而非自动化本身6。
换句话说:当 agent 的产出直接进入监管审计链路,「它跑过了测试」和「它符合交付标准」根本就是两件事。
所以问题的本质是:agentic delivery 引入了新的交付契约,而这个契约的验证方式还没有被系统性地建立起来。
这个契约不是「跑过分」,而是「你知道它做了什么、知道它没做什么、知道它在什么条件下会出错、知道谁来为这个决策背书」。
这正是四层质量门禁要解决的事:定义「对」的标准(Eval)、自动拦截不合格交付(CI)、建立完整的交付证据包(Evidence Pack)、保留人类签名的最后关口(Human Review)。
每个层级通过的标准不同,失败的代价也不同,叠加在一起才构成一个完整的质量保障体系。

跑分全通过,上线就翻车
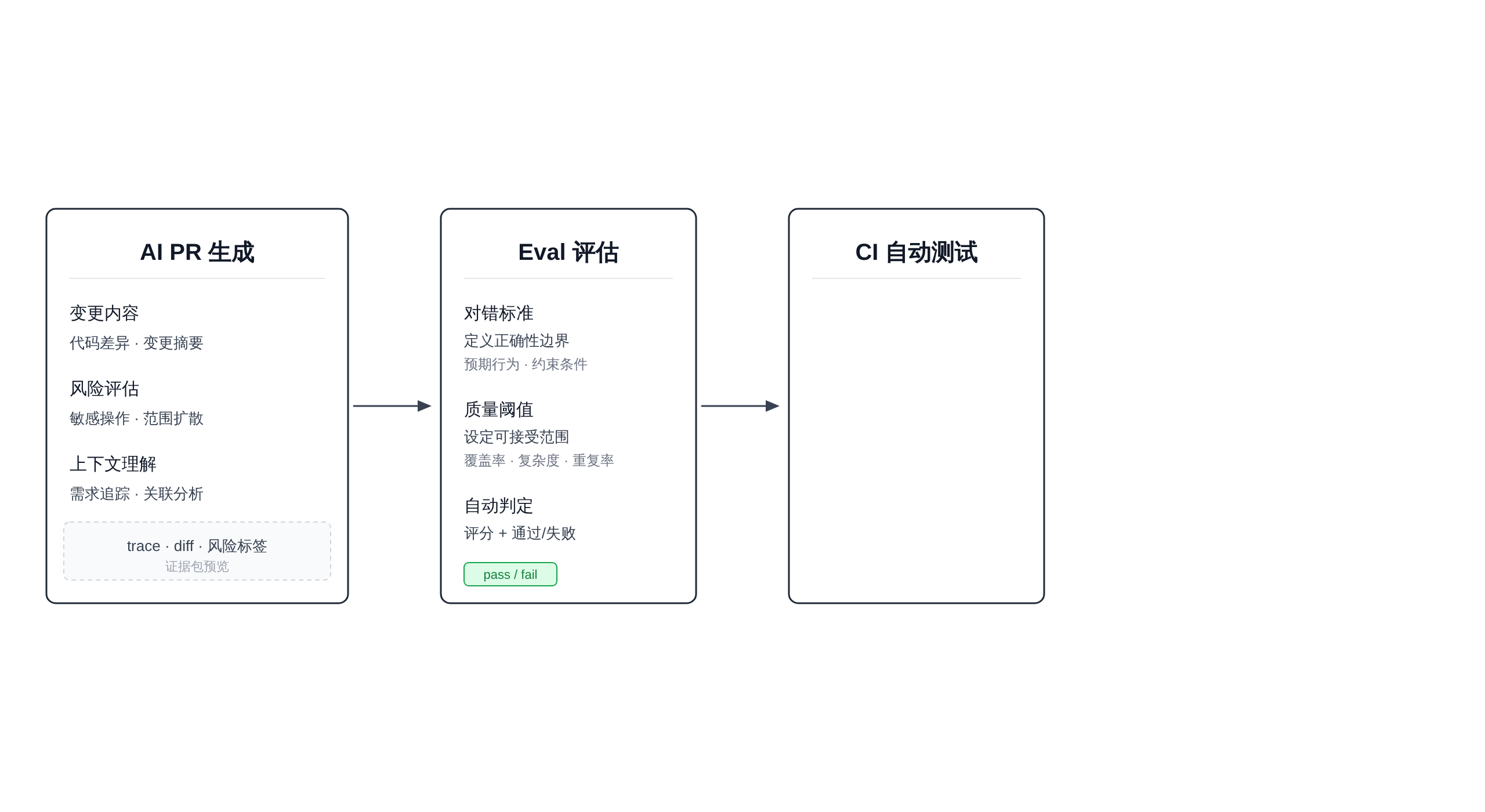
Agentic Delivery 质量门禁链路
这张图把 Eval、CI、Evidence Pack、Human Review 放成一条可复核的工程链路。
四层质量门禁的完整架构
把上面那个布尔 flag 的 RBAC 故事套进一个具体框架,问题就变得可以操作了。

这一段,懂的都懂
我倾向于把 agentic delivery 的质量保障拆成四层叠加的门禁,每层通过的标准不同,失败的代价也不同,漏掉任何一层都会在某个意想不到的地方爆雷。
Eval——不是跑个分,是定义「对」的标准
第一层门禁是最容易被误解的一层。
很多人把 eval 等同于「在 benchmark 上跑个分数」,但对于 agentic delivery 来说,eval 的真实角色是「定义这个任务什么叫对」1。
这个区别至关重要。
模型评测 benchmark(AgentBench、WebArena、AgentEval)测的是模型在通用任务上的能力天花板,但 agentic delivery 的 eval 测的是「特定业务任务在当前配置下能否稳定完成」。
两个东西解决的是不同问题。
一个可用的 agentic eval 通常包含三个维度7:4
任务级成功率 :agent 是否在给定输入下产出了符合 acceptance criteria 的输出。
这是最基础的一层,但也是最容易被「看起来跑过了」所迷惑的一层——因为 LLM 输出天然具有流畅性,流畅不等于正确。
行为级审计 :agent 在完成任务的过程中有没有做出超范围的操作,比如调用了不该用的工具、访问了不该访问的数据、在没有 human approval 的情况下直接写入了生产状态。
这是 CI 层要拦截的东西,但 eval 阶段也应该用回归套件捕获。输出质量 :即使任务完成了,输出的格式、可读性、可维护性是否在团队标准之上。
这里通常用 LLM-as-judge 做辅助评分,由 human reviewer 定期校准 judge prompt,避免评分标准悄悄漂移。
在实际工程中,eval dataset 的构建质量直接决定了整个评估体系的有效性8。
一个常见错误是用公开 benchmark 数据训练,用同样的数据做验收——这样你测的不是「agent 在真实任务上能不能工作」,而是「agent 有没有记住训练集里的答案」。
真正的 eval dataset 应该有代表性任务样本、边界 case 和回归 case 三类,且必须定期用生产 trace 回填新发现的翻车模式。
还有一个实践上的坑值得专门提一下:用 Weave 这类工具做 eval 追踪时,很多团队只关注「最终分数」,忽略了「轨迹特征」——比如 tool call 的平均步数、context window 的使用率、retry 发生的频率。
这些特征本身不会让你的 eval 失败,但它们是回归的前兆信号,能在分数恶化之前提前预警。
CI——自动门禁的工程实现
过了 eval 这层人工定义的标准,第二层门禁是 CI——把「哪些情况绝对不能通过」编码成自动检查,让机器替你拦住不该流向下游的交付物。
在 autonomous PR 场景下,CI 需要扩展传统定义,不再只跑单元测试和 lint,还要捕获以下几类信号:
Trace capture :记录 agent 执行的完整 tool call 序列,包括每一步的输入、输出和耗时。
这个 trace 不是给人类 review 用的——它是审计证据,也是 CI 失败时定位 root cause 的第一手资料。
Permission scope check :agent 在当前 session 里被授权访问了哪些资源?它有没有尝试访问不在白名单里的 API、数据库表或文件系统路径?
这个检查在 CI 阶段通过检查 tool call 日志完成,不需要运行时监控。
Tool call audit :某些工具调用模式本身就是高风险信号——比如连续写入、无条件删除、跳过 approval 的状态变更。
在 CI 里对这些模式配置 regex 或规则匹配,比在代码里埋 if-else 更可控。
这个方向的工程实现已经在大规模生产环境里验证过了。
Equinix 和 Moveworks 合作的 E-Bot 项目里,AI agent 在 Microsoft Teams 里自主处理 IT 支持请求,CI 层的 routing accuracy 达到了 96%,单次分诊时间中位数 30 秒,相比原来人工 5 小时的平均处理时间效率提升了接近 600 倍9。
Equinix 共有 400 人的 IT 团队支持分布在全球的员工,E-Bot 独立处理了 82% 的工单路由,剩下的才进入人工队列。
Connecteam 引入 11x 的 AI SDR agent Julian 之后,同样的思路在销售场景落地:autonomous outbound 在没有额外招聘的情况下处理了每月超过 12 万次电话外呼,人工介入比例降到仅处理高价值商机对接,sales team 的 no-show 率下降了 73%,按当地 SDR 薪资水平折算每年节省超过 45 万美元9。
这两个案例的共同点不是「AI 很强」,而是「它被放进了明确的 CI 门禁里,human reviewer 只需要处理门禁放行之后的高价值决策」。
CI 负责拦住模糊地带,只把真正需要判断的 case 送交人工。
Evidence Pack——每类任务需要什么证据
这是四层门禁里最容易被跳过、但实际上最关键的一层。
Eval 定义了「对」的标准,CI 拦截了「绝对不行」的情况,但一个任务从 agent 手里交付出去到最终上线,还需要一份结构化的证据文档——这就是 Evidence Pack2。
Evidence Pack 的核心价值不是「记录」,而是「转移责任」。
当一个 autonomous PR 被合并出事故之后,团队里最先被问的问题不是「哪个 LLM 产生了这个 bug」,而是「谁签了这个字的」。
Evidence Pack 就是那个字的签名页。
一个完整的 Evidence Pack 应该包含以下五类证据的任意组合,具体由任务类型决定:
测试结果 :包括单元测试、集成测试、端到端测试的输出。关键是不仅要有「通过/失败」,还要有覆盖率报告和失败 case 的完整日志。Trace 和行为日志 :agent 执行过程中的完整 tool call 序列、context window 使用情况和 retry 记录。
如果 CI 已经捕获了 trace,这一项可以直接引用 CI 产物的链接。PR diff 注释 :逐行解释为什么这样改、为什么这个实现优于其他候选方案。
这一步目前无法完全自动化,但可以借助 LLM 生成初稿,由 human reviewer 补充关键判断点。风险说明 :这个改动可能影响的边界条件是什么?
在什么输入下会触发非预期行为?有没有已知的 limitation?这是最容易被省略的一类证据,但它往往是事故复盘时最需要的东西。
回滚方案 :如果上线后出现问题,从什么状态回滚?需要执行哪些步骤?回滚的风险是什么?
很多团队在 forward deployment 上花了大量精力,却从没在 PR 阶段写过一次回滚计划。
Reddit r/AI_Agents 社区里有一个 governance 帖子专门讨论这个:当你需要向审计人员证明一个 agent 的行为在合规范围内,光有 output log 是不够的——你需要可回放的 context、scope 边界内的授权记录,以及「在什么时间点什么人批准了什么操作」的完整链路。
Evidence Pack 的设计原则是「按任务类型配置」,不是「所有任务同一套清单」。下一节会给出具体场景的 evidence 配置模板。

测了,但风险说明呢
Human Review——边界在哪里,怎么保留这个门
最后一层门禁是人。听起来最简单,做起来最复杂。
「保留 human review」这件事在很多团队的讨论里被简化成了「加一个人审批」,但没有说清楚的是:这个 human reviewer 应该 review 什么,以及在什么条件下可以跳过 review。
如果 human reviewer 每次都把 autonomous PR 从头 review 到尾,reviewer 很快会成为 bottleneck——这恰恰是 agentic delivery 想要解决的效率问题。
所以这层门禁的关键设计是:明确划定 human review 的关注范围,让 reviewer 只处理真正需要人类判断的事情 3。
根据经验,以下几类判断确实需要 human review 参与:
意图校验 :agent 理解的任务目标和 product owner 的真实意图是否一致。
这个差距经常出现在复杂业务场景里——agent 能执行,但它执行的是「字面意思」而不是「业务意图」。权限边界确认 :这次变更是否触及了系统中最敏感的权限模型?
比如修改了认证流程、调整了数据访问层级,或者改变了审计日志的记录方式。这类改动的影响半径太大,即使 CI 全绿也需要 human owner 签字确认。
异常 case 处置 :agent 在 trace 里出现了非预期行为——比如 tool call 失败后走了不常见的 fallback、context window 接近上限时做了隐式截断、retry 次数超过了配置的阈值。
这些都不是 CI 失败,但它们是「系统在自己不知道的情况下做出了妥协」的信号。
可降级 review 的场景判断则需要更保守地处理。
一个可行的参考标准是:如果这个任务已经在 staging 环境里完成了 N 次成功执行(N 由团队根据任务复杂度约定,比如 5 次),且没有产生新的 failure trace,那么可以降级为 monthly audit review——不每次都审,但每月抽审一次 trace 样本10。
Coinbase 内部正在测试的「1-person team + AI agents」模式是这个方向最激进的实验:团队极度精简,agent 承担大部分执行工作,但 human owner 对外仍然是唯一的 accountability 节点。
这个模式的问题不在于 agent 能不能完成任务,而在于:当 accountability 链条上只剩下一个人,这个人实际上有没有能力 review agent 产出的所有细节?
答案大概率是「没有」,所以 evidence pack 的质量直接决定了这个人能否真正承担起 owner 的职责。
典型场景的 Evidence 配置
把上面的框架落地,需要针对具体任务类型配置 evidence 清单。三个高频场景的参考模板:
| 场景 | 必选 evidence | 可选 evidence | 通过门槛 |
|---|---|---|---|
| 代码修改 | test results + trace + diff annotation | risk note + rollback plan | CI 全绿 + risk note 完成 |
| 数据操作 | query log + before/after snapshot | permission scope + audit trail | 日志完整 + 数据校验通过 |
| 对外 API 调用 | request/response trace + error rate | contract test + fallback behavior | error rate < 阈值 + fallback 验证通过 |
Dutch insurer 和 Beam 的合作案例提供了一个很有参考价值的比例数字6:Beam 的 AI agent 负责车险理赔决策链路,最终 91% 的理赔案件由 agent 自动处理,只有 9% 被路由到 human adjuster。
这个 91:9 的比例不是拍脑袋定的——它是经过业务方、风险团队和合规部门共同谈判出来的 configuration decision,背后是一套明确的 routing criteria:金额超过一定阈值的、涉及多方责任的、存在欺诈信号的,直接进人工队列;
剩下的走自动路径,且每条自动路径都有完整的 trace 和决策日志留存。
Langfuse 的 trace 监控在这个场景里扮演了基础设施角色——它能识别「tool stallers」模式:当 agent 在某个 tool call 上停留时间异常长,或者连续调用同一个 tool 超过 N 次,trace 系统会自动标记这个 session 需要优先 review。
这不是 CI 失败,但它是 evidence pack 里「异常行为」这一栏的自动填充。

这个锅,谁签谁背
风险边界:Evidence Pack 解决不了的三个问题
说清楚这套门禁能做什么之后,必须诚实地说清楚它不能做什么。
第一层边界:Durable State
如果任务涉及长 running context、跨 session 的状态持久化,或者需要在多个隔离环境之间同步状态,这套门禁本身可能不够用。
workflow runner 的设计假设是「给定输入,经过已知步骤,产出已知输出」,但 durable state 场景里的状态变化往往是隐式的——上下文里没有显式记录,但系统行为已经改变了。
当这种隐式变化累积到一定程度,trace 日志里记录的只是「agent 调用了什么 tool」,而不是「这些调用在持久化层面造成了什么后果」。
第二层边界:消费者信任
即便内部 evidence pack 做得再完善,它解决不了的是用户端的信任问题。
Bain 的研究报告指出,大约 50% 的消费者对端到端的 autonomous transaction(不需要任何人工介入的自动交易)仍然存有顾虑11。
这个数字在金融、医疗和法律服务领域更高。
在这些场景里,evidence pack 是内部合规工具,不是用户沟通工具——如果你的 agent 产出需要直接面对终端用户,透明度设计和用户侧的 explainability 需要单独做,不能用 evidence pack 替代。
第三层边界:责任归属的灰区
prompt injection、scope creep 和 OAuth token 泄露这三类问题,evidence pack 能记录它们的发生,但无法预防它们的发生2。
当一个 agent 在被授权的范围内执行了看似合法的操作,但这个操作实际上触发了超出预期的影响链——比如一个文件写入操作恰好覆盖了备份脚本,或者一个 API 调用带出的 side effect 影响了另一个系统的状态——evidence pack 记录的只是「按计划执行」,而不是「后果是否可接受」。
这三个边界的共同特征是:它们不是工程质量问题,而是制度设计问题。
Evidence Pack 能让一个团队在事后说清楚发生了什么,但它不能代替事前对 agent 的权限边界、影响半径和 contingency plan 的主动设计。

出了事,谁来担这个责
开源工具链:哪些工具可以用来搭这套门禁
框架说清楚了,接下来最实际的问题是:用什么工具搭。

屏幕一红,心率先上去了
这一节按四层门禁的层级逐层梳理,每个工具给出核心能力和适用场景判断,不做过度展开——工具有效性的上限永远在团队的实施能力,不在工具本身71。
Eval 层:Braintrust 和 Weave
Braintrust 是目前 eval platform 赛道里工程化程度最高的工具之一。
核心能力不是「跑分」,而是 eval dataset 的管理——你可以把一个任务的成功标准定义成结构化的 test case,然后让任意 agent 版本在同一套 dataset 上跑分,结果自动聚合进评分看板。
Braintrust 的 LLM-as-judge 功能支持自定义评分维度:tone、completeness、factual fidelity 三维度是最常见的配置,你可以加第四维、第五维,只要你的 eval dataset 设计得过来。
关键设计点是 judge prompt 的质量——一个写得很糙的 judge prompt 会让整个 eval 体系产生系统性偏差,而且这种偏差在跑分上是看不出来的,只有上线后才会暴露。
Weave 是 Weights & Biases 旗下的 eval 管理工具,定位更偏向「给 AI 应用跑分的 CI」。
它的优势是和你已有的 W&B 实验追踪体系天然打通——如果你团队已经在用 W&B 做模型训练实验,Weave 可以直接复用同一套 API,把训练 metrics 和 agent eval metrics 放在同一个 dashboard 里看。
选 Braintrust 还是 Weave,经验判断是:如果你的团队有专职的 AI 工程师岗位、eval dataset 是持续迭代的核心资产,选 Braintrust;
如果你的团队用 W&B 比较多、agent eval 只是模型训练的延伸工具,选 Weave。两者都有 LLM-as-judge,核心差异在生态集成和团队工作流匹配度上。
Observability 层:Langfuse 和 Raindrop
Langfuse 是目前 production agent trace 监控最成熟的开源选项之一。
核心能力是「把 agent 的一次执行完整地记录下来」——包括 tool call 的序列、输入输出的 token 数量、context window 的使用率、retry 和 fallback 的路径。
Langfuse 有一个功能在 evidence pack 场景里特别有用:tool staller 检测 。
当 agent 在同一个 tool call 上停留时间超过配置的阈值,或者连续调用同一个 tool 超过 N 次,Langfuse 会自动把这个 session 标记为「异常」,并生成一个短报告推给 reviewer——这个报告可以直接作为 evidence pack 里「异常行为」这一栏的自动填充12。
Raindrop 提供的 agent observability 能力更偏向「全局视图」:它能追踪跨 agent 的依赖关系、tool call 的共享使用情况、以及整个 agent 系统的 SLA 达成率。
如果你的团队同时跑多个 agent、或者 agent 之间有上下游依赖关系,Raindrop 的全局 trace 功能比 Langfuse 的单 agent trace 更适合做系统级的 evidence 收集12。
这两个工具的共性是:它们解决的都不是「agent 跑得好不好」,而是「agent 到底怎么跑的」——这个区别是 evidence pack 和普通 CI report 的根本差异。
CI/CD 层:GitHub Actions 和 Buildkite
CI 层是四层门禁里工程化程度最高的一层,因为它本质上就是把传统的代码 CI 逻辑扩展到 agent 场景。
GitHub Actions 的优势是生态完整——autonomous PR 触发 action、action 执行 trace capture、trace 通过后进入 human review 队列,这整条链路在 GitHub 原生生态里就能走完,不需要额外的编排层13。
Buildkite 适合更复杂的 agent pipeline:如果你需要在 CI 里做分支判断(不同类型的 agent 任务走不同的验证路径)、或者需要并行跑多个 eval suite,Buildkite 的 pipeline 语法比 GitHub Actions 的 YAML 配置更灵活。
Equinix 和 Moveworks 合作里的 E-Bot 就是跑在 Buildkite 风格的自研 CI 系统上的——96% routing accuracy、30 秒分诊时间背后是一套精密的 agent routing criteria 配置。
Orchestration 层:LangGraph
LangGraph 是 LangChain 生态里的 workflow orchestration 工具,核心抽象是「state machine + enrichment node」。
它解决的是「一个复杂任务怎么在多个 agent 之间流转」的问题——每个 node 代表一个 agent 或一个处理步骤,edges 代表状态转换规则,conditional edges 代表分支逻辑。
在 evidence pack 场景里,LangGraph 的价值是它让「哪一步生成了什么 evidence」变得可追踪——每个 node 的执行结果可以显式地写入 evidence store,而不是散在各个 agent 的内部状态里。
Factory 的 multi-agent architecture 案例里就有一个明确的 enrichment node 设计模式:主 agent 负责规划,子 agent 负责执行,enrichment node 负责把每一步的 evidence 自动聚合到同一个 evidence pack 文档里13。
LangGraph 的局限是它目前更偏向「设计时 orchestration」——你需要提前定义好 state machine 的结构,而不是让 agent 自己动态决定下一步怎么走。
如果你的场景需要更动态的 agent 协作,LangGraph 可能不够,需要配合专门的 multi-agent orchestration 层一起用。
工具选型的实用判断
四个层级各自选一个工具搭最小可行版本,技术上完全可以跑通:
Braintrust(eval)
↓
GitHub Actions(CI)
↓
Langfuse(trace capture)
↓
Human review board(最终签字)
如果团队已经有现成的工具栈,替换对应层级即可,不要为了「新工具」做不必要的迁移。工具链的目标是「让 evidence pack 能被持续积累」,不是「看起来完整」。

我去给 agent 补 evidence 了
我的判断:Evidence Pack 是下一个工程标准
写到这里,有一个判断值得直接说出来。
Agentic Delivery 的核心瓶颈已经转移了。
2023 到 2024 年,这个领域的讨论焦点是「怎么让 agent 跑得更快」——推理速度、token 吞吐量、tool call 并发能力,每个都是当年最热的优化方向。
但到了 2025 年下半年,方向开始分化:速度问题被解决得差不多了,但验证成本没降下来9。
当 autonomous PR 可以批量产生,CI 全绿只是起点——真正的问题是:这个 PR 有没有通过验收所需的所有证据?如果没有,那它「全绿」的意义只是「没有明显错误」,而不是「可以发布」。
Evidence Pack 本质上是一份工程契约:它回答的不只是「这个 PR 对不对」,而是「谁为这个 PR 背书、在什么条件下可以跳过哪一步 review」。
这份契约的签发人和签发时间是审计追踪的核心字段,也是团队在出事故后最先需要找到的信息。
它解决不了 durable state 问题,解决不了消费者信任问题,也解决不了 prompt injection——这些是制度设计问题,不是工程质量问题。
但它让「制度设计」这件事变得可落地、可追踪、可审计。
一个可预见的趋势是:未来 12 到 18 个月内,会有一批工程团队把 Evidence Pack 写成 SOP,并且把 SOP 的执行情况纳入 team health metrics 里14。
不是因为管理层喜欢 SOP,而是因为没有 evidence pack 的 autonomous PR,在监管严格的行业里根本过不了合规审计。
这个变化在金融和保险领域会来得最快。
Dutch insurer 和 Beam 的 91:9 自动理赔比例,已经证明了这个方向在商业上的可行性6。
剩下的只是其他行业从「观望」到「跟进」的时间窗口。
最后留一个问题给你的团队:
你的 autonomous PR,现在有 evidence pack 吗?如果没有,出事故之后第一个被问「谁签了这个字」的问题,你答得出来吗?

补 evidence 去了,回聊
参考文献
如果浏览器无法直接唤起微信,可在微信内打开公众号主页:计算机魔术师


