
上周有个读者跟我复盘一场 AI 应用工程师面试。 他前面聊 RAG、Embedding、LangGraph 都很顺,直到面试官问了一句:「如果你的 Agent 调了三次工具还是没解决问题,它接下来应该继续试、换计划、反思,还是停下来交给人?」 他当场卡住了。 不是因为不知道 ReAct,也不是没听过 CoT,而是突然发现自己一直在背范式名词,却没有把 Agent Loop 当成一个工程系统来理解:怎么规划,怎么执行,怎么反思,记忆写在哪里,什么时候必须停。 这篇就沿着这五个点,把 CoT、ToT、GoT、Self-Consistency、ReAct、Tool-use、Plan-and-Execute、Reflexion、Self-Refine 串起来讲透。
一、Agent Loop 为什么是 AI 工程师面试的底层题
1.1 Agent Loop 是一类闭环系统
很多候选人把 Agent Loop 等同于 LangGraph 或 CrewAI 的 API 调用,这是把范式理解成了框架选型。Agent Loop 是一类闭环推理-执行架构的设计哲学:模型输出思维步骤 → 执行动作 → 获得反馈 → 依据反馈更新状态并决定下一步。无论用 ReAct、Toolformer 还是 Voyager 的技能库,都属于 Agent Loop 的具体实现。

1.2 五个核心设计点
把 Agent Loop 做工程拆解,核心变量只有五个:
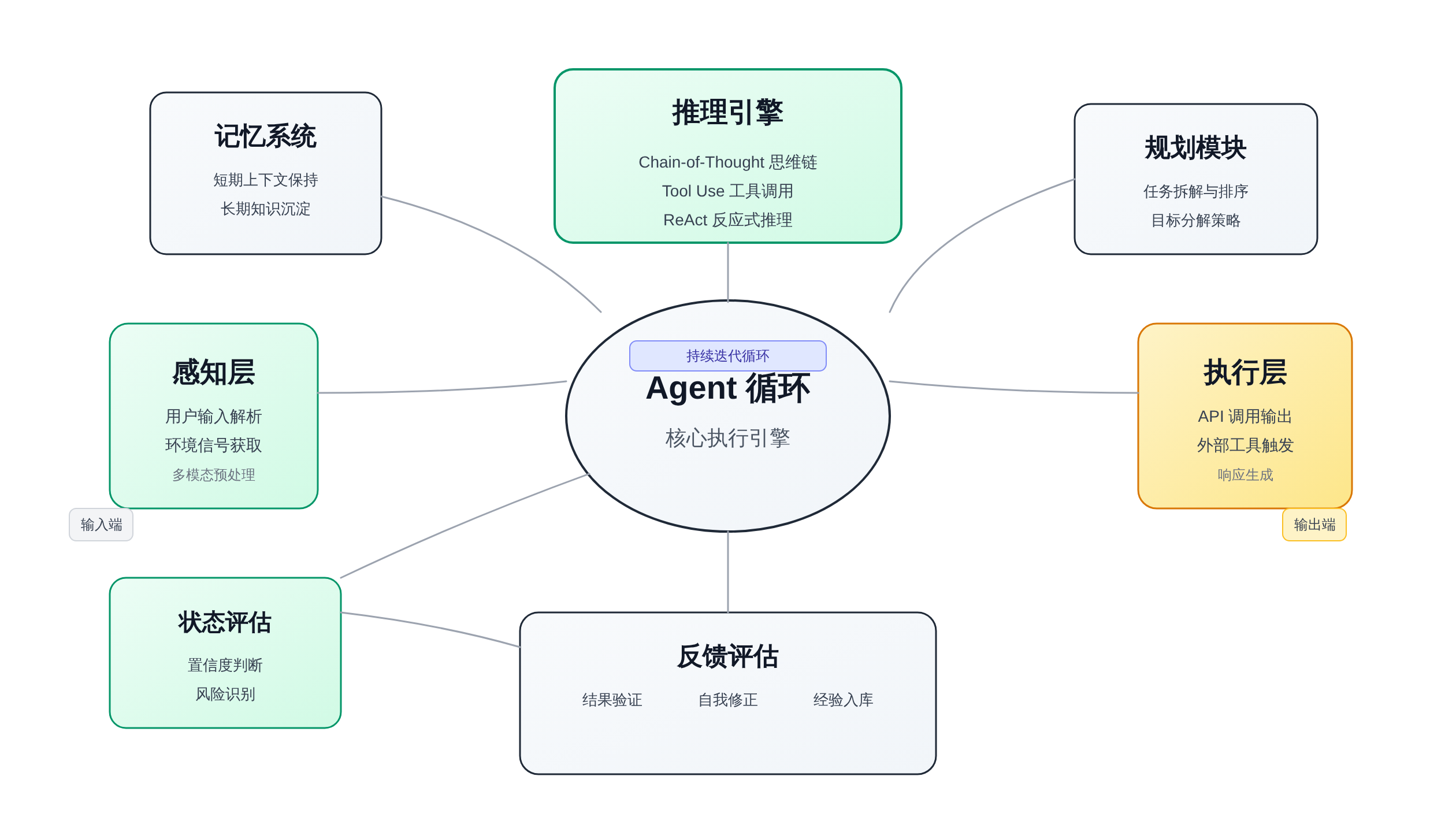
Agent Loop 五大核心设计点及其交互关系
规划决定把问题拆成几步;执行负责调用工具并拿到反馈;反思判断当前路径是否有效;记忆决定上下文窗口里留存哪些历史信息;终止条件防止系统在无效路径上无限循环。这五个变量组合出不同范式:ReAct 把反思内嵌在每一步,Reflexion 把反思做成独立轮次,Self-Refine 用迭代精化替代一次性规划,Plan-and-Execute 把规划和执行解耦成两个阶段。
1.3 面试官考察的是机制、边界和工程取舍
面试官问「调三次工具还没解决该怎么做」,不是在考你知道多少个论文名字,而是想听你在有限轮次 vs. 探索深度之间的权衡逻辑:你有什么依据判断当前路径失败?反思粒度是工具级别还是任务级别?这本质上是考察你把范式论文翻译成生产系统配置参数的能力——最大重试次数设多少、反思触发阈值怎么调、记忆窗口截断策略是什么。
二、推理型 Loop:从 CoT 到 ToT、GoT 和 Self-Consistency
推理型 Loop 的核心不是执行外部动作,而是让模型「看见自己的思考过程」。这类范式不依赖工具调用,但它们设计的评价、采样和搜索机制,直接决定了后续执行型 Loop 的上限。
2.1 CoT:把隐式推理显式化
Chain-of-Thought 的本质是用自然语言显式写出中间推理步骤,让模型在多步任务上克服「直接猜答案」的瓶颈。标准 CoT 需要 few-shot 示例引导推理方向,Zero-shot CoT 则通过「Let’s think step by step」触发器激活模型内部已经具备的隐式推理链。[^1] [^2]
面试中真正有区分度的问题是:你怎么判断 CoT 在某个任务上是否有效?答案是看任务的「步骤可分解性」——数学推导、逻辑证明、多跳问答这类任务天然适合,因为每一步的中间结论都可验证。而开放式写作、情感分析这类任务,CoT 收益有限,因为中间步骤本身难以客观评判。
2.2 ToT:把单链路推理扩展成树状搜索
Tree of Thoughts 在 CoT 的线性链路基础上引入了 BFS 或 DFS 搜索:当模型在某个节点产生多个候选推理分支时,系统会主动探索不同路径、评估中间状态、决定剪枝或回跳。[^3]
面试追问:「ToT 和 CoT 在实现上最大的工程差异是什么?」答案是「评价函数的位置」——CoT 的评价发生在输出层,ToT 的评价发生在每个分支节点,决定了搜索是否继续。工程实现上需要关注两点:第一,评价函数可以是另一个 LLM 调用(带评判 prompt),也可以是规则化的奖励模型;第二,树深度和分支宽度直接决定 token 消耗,根据任务难度动态调整。
2.3 GoT:用图组织有依赖关系的思考
Graph of Thoughts 将树状结构进一步泛化为有向图:节点是「子任务」,边可以表示依赖关系、并行关系或回跳关系。GoT 支持聚合操作,多个中间结果可以合并为一个新的思考节点继续处理。[^4]
面试追问:「GoT 和 Multi-Agent 里的任务分配有什么区别?」核心区别是 GoT 仍在单一模型内部完成图结构推理,而 Multi-Agent 是多个独立 Agent 之间的通信与协作。
2.4 Self-Consistency:多采样后一致性选择
Self-Consistency 的设计哲学不同于 CoT/ToT/GoT 的「主动结构化推理」,而是一种「事后选举」:对同一个问题让模型多次独立生成不同的推理路径,然后用多数投票或加权得分选出最终答案。[^5]
工程落地时需要明确:Self-Consistency 的成本是单次推理的 N 倍(N=采样次数),所以它适合「推理结果价值高且容错空间小」的场景,比如代码生成、数学证明、医疗诊断建议。面试常被问到:「Self-Consistency 和 ToT 你怎么选?」本质上是在问「你是愿意在结构化搜索上投入计算资源,还是愿意用采样多样性换取结果的统计稳健性」。
2.5 推理型 Loop 的共同边界
这四种范式共享三个工程边界:
搜索成本是 ToT 和 GoT 的硬约束。树/图的深度与宽度指数级增长,token 消耗可以从单次生成的几十元飙升到数百元。生产系统里必须有「budget forcing」机制——限定最大搜索步数、超预算直接返回当前最优解。
评价函数是隐含的脆弱点。ToT 的剪枝、GoT 的边权重、Self-Consistency 的投票都依赖一个评价函数,而这个函数本身可能是另一个 LLM 调用,它的能力上限直接决定了推理质量。面试中经常追问「如果评价 LLM 也产生了幻觉怎么办」,答案是「对关键节点使用双 LLM 交叉验证」,或者「引入规则化奖励做辅助评价」。
幻觉在搜索中会被放大。CoT 每一步都可能在「看起来合理」的推理中引入新的幻觉,而 ToT/GoT 的多路径探索会进一步扩散这个风险。Self-Consistency 的投票机制可以部分缓解,但不能根本解决——多个幻觉路径可能相互一致,从而在多数投票中胜出。生产系统必须在推理后增加「事实核查」环节。

三、行动型 Loop:从 ReAct 到 Tool-use 和 Plan-and-Execute
3.1 ReAct:Thought / Action / Observation 闭环
ReAct(Synergizing Reasoning and Acting in Language Models,2022)第一次把推理和行动绑定成循环:模型生成 Thought 识别当前状态,Action 触发外部工具调用,Observation 把返回结果注入下一轮推理。[^8]
ReAct 的核心价值不在于这三个标签,而在于它把工具调用变成了可审计的推理步骤。传统做法里模型直接输出 API 调用,开发者不知道它为什么选这个工具。ReAct 让 Thought 显式化了决策依据:模型先说「当前对话中没有提到北京的历史建筑信息,需要搜索」,然后才执行 Search 操作。
面试追问:ReAct 的 Thought 是模型自己生成的还是 prompt 里写好的?答案:两者都有。论文中用 zero-shot prompting 让模型自发生成 Thought,但工程实践中往往在 system prompt 里预置 Thought 结构,引导模型在每个 Action 前先写推理。
3.2 Tool-use loop:schema、结果回注与失败自修正
ReAct 把工具调用框架化了,接下来要解决的是工具本身的质量问题。ToolLLM(2023)用 ChatGPT 探索了 16000+ 真实 API 的调用轨迹,证明 LLM 可以学会复杂工具链,但前提是工具 schema 足够清晰。Gorilla(2023)进一步发现:当 API 文档结构不好时,模型调用准确率从 95% 掉到 60%——schema 质量直接决定工具调用成功率。[4] [13]
HuggingGPT(2023)把这个逻辑反过来:不是让模型适配固定工具集,而是让模型根据任务描述动态选择模型和工具。它的 pipeline 是:任务解析 → 模型选择 → 执行 → 响应聚合。[3]
Tool-use loop 的另一个关键设计是失败自修正。当 Search 返回空结果或 API 调用超时时,模型需要知道「这次失败了」并决定下一步。常见策略有三种:降级重试(换同类型工具)、跳跃修正(跳过当前步骤尝试下一计划)、回退反思(回到更早的 Thought 重理逻辑)。
3.3 Plan-and-Execute:全局计划与局部执行分离
ReAct 的局限在于它是单步决策:每轮只决定当前做什么,不考虑整体目标。Plan-and-Execute 把这个能力拆成两阶段:Planner 先把任务拆成子步骤,Executor 按顺序执行,必要时回注执行结果给 Planner 重新规划。[^11]
ReWOO(Decoupling Reasoning from Observations,2023)设计了 Planner-Worker-Solver 三角色:Planner 输出完整计划(含各步骤依赖关系),Worker 执行每个步骤并收集 evidence,Solver 汇总 evidence 生成最终答案。这种解耦减少了观察依赖——Worker 执行时不需要等待上一轮 Observation,可以并行处理独立步骤。[11]
Voyager(2023)是 Plan-and-Execute 在具身智能中的落地。它用 LLM 生成技能库(skill library),每个技能是环境相关的操作序列。Planner 根据当前任务从技能库中组装计划,Executor 执行后反馈结果给下一轮规划。[12]
面试追问:「Plan-and-Execute 和 ReAct 哪个更好?」标准答案是:ReAct 适合动态环境(每步结果影响下一步),Plan-and-Execute 适合静态规划(目标明确、步骤可预判)。
3.4 行动型 Loop 的工程边界
权限控制:每次 Action 调用外部 API 前,必须验证调用方权限。你不能把管理员工具直接暴露给用户 prompt——这和 Web 安全里的最小权限原则一致。ToolLLM 的实验中发现「模型可能绕过权限提示调用敏感 API」的问题,实际项目里需要额外加校验层。
幂等性:同一个 Action 执行两次应该产生相同结果(或至少不产生副作用)。Search 是天然幂等的,读操作通常幂等。但写入类操作(发送消息、转账、执行代码)必须设计幂等 token,避免网络重试导致重复执行。
超时设计:每个 Action 必须有超时配置。HTTP 请求默认超时 30 秒,复杂计算任务可以给 5 分钟。超时后的策略取决于任务类型:读取类可以降级返回缓存,写入类必须回滚或标记失败。
四、反思型 Loop:Reflexion 与 Self-Refine
4.1 Reflexion:把失败经验写回记忆
Reflexion 论文(https://arxiv.org/abs/2303.11366)提出的核心思想很直接:Agent 不应该只依赖当次推理的结果,还应该对失败案例做口头自我反思,并把结论编码后写入长期记忆,供后续任务复用。
实现上,Reflexion 分为三个组件:参与者(Actor)负责执行动作并输出结果;评估者(Evaluator)对照期望结果或奖励信号给当次输出打分;自我反思者(Self-Reflector)分析失败原因,用自然语言生成「教训」并存入记忆缓冲区。下一次遇到相似任务时,Agent 从记忆缓冲区检索历史教训,在规划阶段就规避已知陷阱。
工程边界:第一,记忆检索的召回率——如果教训库太大、语义检索不准,Agent 可能检索到无关经验反而带偏决策;第二,口头反思本身的可靠性——当模型对自身错误归因错误时,写入记忆的是错误结论,会导致后续系统性偏差。
4.2 Self-Refine:生成、反馈、重写的自我修订
Self-Refine(https://arxiv.org/abs/2303.17651)走了另一条路:它不依赖外部奖励信号,而是让同一个模型同时扮演生成者(Generator)和反馈者(Critic),在循环中不断自我改进输出质量。
Self-Refine 的循环逻辑是:生成初始内容 → 反馈者给出具体改进建议(而非泛泛评价)→ 生成者据此修订 → 循环直到质量达标或达到最大步数。关键设计点在于反馈的质量——笼统的「不太好」没有操作价值,Critic 必须能给出可执行的修改方向。
Self-Refine 在代码生成、写作优化、SQL 查询修复等任务上效果显著,因为这些领域的结果质量可以被模型自身可靠评估(语法正确性、风格一致性、逻辑连贯性)。但在需要外部事实校验的任务上,自我修订循环有个致命问题:模型对自身输出的信任度会随迭代次数增加而提高,即使初始答案有事实错误,Critic 也可能因为「这是同一模型生成的」而无法发现问题。
4.3 反思型 Loop 适合写作、代码,不适合事实核验
把 Reflexion 和 Self-Refine 放在一起看,能提炼出反思型 Loop 的通用适用边界。
适合场景有三个共性:结果质量可以被相对可靠地评估(语法、风格、逻辑);反馈信号可以由模型自身生成而不依赖外部标注;迭代改进的成本低于重新生成。写作润色、代码 Debug、查询修复都符合这三个条件。
不适用的场景也有明确特征:任务结果依赖外部世界状态(库存数量、实时价格);错误的后果不可逆(金融交易、医疗建议);模型对领域的先验知识存在系统性偏差。这些情况下,反思型 Loop 的多次迭代反而会放大初始偏差,应该在首次输出后直接引入外部校验步骤。
面试追问:「Self-Refine 的 Critic 如果给出错误反馈,模型会越改越差,怎么处理?」标准答案是增加外部校验锚点或者在关键迭代节点插入规则检查。
五、记忆与终止条件:Agent Loop 能不能上生产的分水岭
5.1 三层记忆的职责边界
Agent Loop 里的「记忆」不是把对话历史一股脑塞进 context 就完了,它有三个职责边界完全不同的层。
短期记忆是当前对话窗口内的上下文,约束来自 token 上限。每次工具返回的结果、用户的新输入,都在短期记忆里。设计不好会导致最近的工具结果被「挤出」窗口,Agent 看不到自己刚查到的信息,重复调用同一个 API。
长期记忆解决跨会话的信息复用问题。Generative Agents 提出的 memory stream 架构,把事件压缩成自然语言描述存入外部存储,检索时用向量相似度匹配。MemGPT 进一步把 LLM 当成操作系统,在大上下文(类似 RAM)和外部存储(类似磁盘)之间做 memory paging。当上下文窗口快满时,把不重要的历史压缩或写出到外部存储,下次需要时再 page back 进来。
反思记忆专门存储执行过程中的关键决策和结果。Reflexion 把每次失败经验写成自然语言形式的 self-reflection,写进长期记忆供下次同类任务参考。这个层级的记忆不是「我查了什么」,而是「上次在这个类型的任务上为什么失败」。
5.2 max_turns、质量阈值、预算阈值与人工接管
终止条件不是设一个 max_turns 就完事了,它是一个多维度决策树。
max_turns是最基础的硬限制,防止无限循环。设太小会过早退出,设太大又等于没设。经验值看任务复杂度:简单 API 查询 3-5 轮,复杂多步推理 10-15 轮,有 Plan-and-Execute 结构的可以到 20 轮但每轮成本更高。
质量阈值判断当前结果是否已经满足任务要求。不是所有任务都需要 100 分——一个天气查询只要返回地点和温度就算完成,一个合同审查可能要求召回率 > 95%。质量评估可以是 LLM 自评、规则匹配,或者调用独立的评估模型。
预算阈值面向成本控制。企业级 Agent 系统里每次工具调用都有成本,大模型推理按 token 计费。预算阈值让系统在接近成本上限时主动退出,避免一次失控查询把月度预算烧光。
人工接管是最后的安全网。当系统连续 N 次工具调用失败,或者质量评估结果低于某个底线,主动挂起任务、通知人工处理。接管的触发条件需要和业务方一起定义。
实际工程里这四个条件通常用 AND 逻辑组合:超过 max_turns 且 质量未达标 且 预算未耗尽,才触发人工接管。
5.3 防止死循环的工程策略
死循环是 Agent 上生产时最让人头疼的问题——Agent 在几个状态之间来回切换,既不完成也不退出,消耗大量 token 和预算。常见根因有几类:工具返回结果重复、规划在两个等价方案之间振荡、反思没有产生有效的新信息导致无限自指。
状态追踪是基础。每个 loop 周期记录当前 state 的向量表示或结构化摘要。检测到当前 state 与历史 state 的相似度超过阈值时,判定为循环并触发重规划。这里有个坑:相似度阈值设太高检测不出来,设太低会误判正常回退为死循环。
执行日志与回溯把所有 Action 的输入输出、反思的结论、工具返回的 error 记录下来。一旦进入死循环,可以回溯到上次成功执行的 checkpoint 重试,而不是从头开始。Voyager 的技能库(skill library)机制也类似:新任务先在已验证成功的技能库里搜索,避免重复尝试已经证明无效的方案。
超时机制兜底。即使相似度检测失效,系统也要有 wall-clock timeout,防止真正进入不可恢复的循环。这个超时通常设在预期任务完成时间的 2-3 倍,太短会误杀复杂任务,太长则失去保护意义。
六、范式对比表:不同 Loop 适合什么任务
6.1 推理型、行动型、反思型机制对比
三条范式线的本质差异在于 Loop 的牵引力来源:推理型由搜索空间驱动,行动型由外部反馈驱动,反思型由自我评估驱动。
| 维度 | 推理型(CoT/ToT/GoT/SC) | 行动型(ReAct/Tool-use/P&E) | 反思型(Reflexion/Self-Refine) |
|---|---|---|---|
| 核心驱动 | 候选路径的评分与选择 | 工具返回的 Observation | 失败原因的回溯与改写 |
| 状态外化 | 中间步骤写入 Prompt | 步骤+工具输出写入记忆 | 反思结论写入长期记忆 |
| 终止依据 | 评分收敛或预算耗尽 | 任务完成或 max_turns | 质量达标或重写上限 |
| 典型失效 | 评分函数不准确导致误选路径 | 工具 schema 错误导致循环调用 | 反馈信号弱导致原地打转 |
6.2 搜索、代码、写作、问答、系统操作的选型
不同任务类型对 Loop 范式的需求差异,本质上是反馈密度和路径可逆性两个维度决定的。
搜索类任务(信息检索、实体关系挖掘):反馈密度低、路径基本不可逆。适合 ToT/GoT 做广度探索,配合 Self-Consistency 做结果验证。
代码类任务(代码生成、Bug 修复):反馈密度中等、路径有一定可逆性。适合 Tool-use loop 串联编译器或测试框架,失败后返回错误信息触发重新生成。Self-Refine 在代码风格统一和逻辑优化上有优势。
写作类任务(文案、报告、创意生成):反馈密度低、路径强可逆。适合 Reflexion 做多轮自我修订。Plan-and-Execute 中的规划层可以先生成大纲,执行层逐段落填充。
问答类任务(事实查询、解释生成):反馈密度取决于外部知识源。适合 ReAct 调用检索工具 + 知识库,在 Observation 充分时快速终止。不需要 ToT 的搜索复杂度,除非涉及多跳推理。
系统操作任务(API 调用、文件管理、部署流水线):反馈密度高、路径不可逆。适合 Plan-and-Execute,全局规划避免操作顺序错误,局部 ReAct 处理工具调用。必须设置 max_turns 和人工接管阈值。
6.3 常见组合:Plan-and-Execute + ReAct + Reflexion
单一范式在复杂任务中往往不够用,工程实践中常见的组合是 三层嵌套:Plan 层做任务拆解,ReAct 层处理工具执行,Reflexion 层做质量兜底。
这个组合的分工逻辑很清晰:Plan 层把「做什么」拆解清楚,ReAct 层把「怎么做」执行到位,Reflexion 层在「做不好」时提供自我修复通道。面试时如果被问到「ReAct 和 Plan-and-Execute 的区别」,可以补充一句:ReAct 是紧凑闭环适合简单单步任务,Plan 层加上 ReAct 才适合多步骤复杂任务的全局可控性。
七、项目里怎么讲:把范式落到真实 Agent 系统
7.1 在 LangGraph / deep-agent / OpenClaw 里映射五个设计点
在 LangGraph 里,Agent Loop 的五个设计点被显式建模为状态机节点:规划阶段对应 supervisor 节点,执行阶段对应 action 节点,反思阶段对应 conditional_edge,记忆写入 store 或外部向量数据库,终止条件由 max_turns 参数控制,超时后触发 human_review 路由。deep-agent 则把规划、执行、反思分别抽象为 planner、executor、reflector 三个独立服务,通过消息队列解耦,适合需要横向扩展的异步场景。OpenClaw 采用声明式配置文件,在 YAML 里定义 planning_prompt、tool_schema、reflection_threshold,框架自动生成状态流转图。
| 设计点 | LangGraph 实现 | deep-agent 实现 | OpenClaw 实现 |
|---|---|---|---|
| 规划 | supervisor 节点 | planner 服务 | planning_prompt |
| 执行 | action 节点 | executor 服务 | tool_schema |
| 反思 | conditional_edge | reflector 服务 | reflection_threshold |
| 记忆 | store + vector DB | 外部内存服务 | 插件化 memory backend |
| 终止条件 | max_turns 参数 | 超时队列触发 | human_review 路由 |
这种映射表在面试时能快速展示你对框架内部机制的理解深度,而不只是会说「我用 LangGraph 做过 Agent」。
7.2 Tool 调用失败的四个层次与观察结果回注
Tool 调用失败的工程设计有四个层次。第一层是网络超时或服务不可用,返回 Observation 时标注 status: retryable,由执行器在下一轮自动重试。第二层是业务逻辑失败,比如 API 返回 400 错误,返回 status: failed 并携带 error_code,反思节点读取后决定是换工具还是降级到人工。第三层是权限拦截,Agent 试图调用超出白名单的工具时,框架直接抛出 PermissionError,观察结果回注为 status: forbidden,规划节点在下一轮决策时必须跳过该工具。第四层是循环检测,连续两次调用相同工具且结果相似时,触发 status: circular,直接终止循环并记录日志。
观察结果回注的典型代码结构:
class ToolResult:
status: str # success | retryable | failed | forbidden | circular
observation: str
error_code: Optional[str]
metadata: dict
def execute_tool(tool_call, context):
try:
result = tool_call.execute()
return ToolResult(status="success", observation=result)
except TimeoutError:
return ToolResult(status="retryable", observation="timeout")
except PermissionDenied:
return ToolResult(status="forbidden", observation="permission denied")
except Exception as e:
return ToolResult(status="failed", error_code=str(e))
这段代码对应 LangGraph 的 ToolNode,也对应 deep-agent 里 executor 的 execute_with_retry 方法。面试时能写出具体字段和处理逻辑,比背概念加分很多。
7.3 如何回答「为什么你的 Agent 不会无限循环」
这个问题考察的是你对终止条件设计的系统性思考。答案要覆盖三个维度:硬性边界、软性判断和降级机制。
硬性边界指 max_turns 或 max_time 直接切断循环,比如设置 max_turns=15 或 max_time=120s。软性判断指在每一轮检查 similarity(last_n_observations),如果连续三次观察结果向量相似度超过 0.95,就判定为循环,强制退出。降级机制指当达到任一硬性边界或软性判定触发时,Agent 不直接返回空结果,而是记录 exit_reason,触发 human_review 事件,附带完整的状态轨迹供人工介入。
八、面试追问、易错边界和三分钟回答模板
8.1 高频追问清单
时序问题:「ReAct 的 Thought 和 Action 顺序能颠倒吗?先执行再思考会不会更好?」答案是不能,Thought 必须在前,因为 LLM 需要用语言表达推理链来决定动作,否则没有规划就执行会陷入随机试错。
边界问题:「Reflexion 把反思写回记忆,这个记忆是短期还是长期?如果长期存储,多大的量会开始影响 embedding 质量?」答案要看场景,短期对话用等宽窗口,长期任务用向量检索加定期压缩。
组合问题:「Plan-and-Execute 加 Reflexion 怎么接?Execute 失败后是回到 Planner 还是 Reflector?」答案是回到 Planner,因为 Plan-and-Execute 的全局计划是主轴,反思只负责修正计划,不负责直接重试。
性能问题:「CoT 在推理时 token 消耗大,线上延迟怎么控制?」答案是用 Chain-of-Thought 蒸馏或者限制思考步数,比如 max_thought_tokens=512。
业务问题:「如果你的 Agent 跑在客服场景里,用户说『算了不等了』,你怎么让它停下来?」答案是加 user_abort 信号拦截,收到后无论在哪一步都立即退出到人工。
8.2 易错点:把 CoT 当架构、把 ReAct 当万能、把反思当事实核验
第一个易错是把 CoT 当成架构设计。CoT 本质是 Prompt 技巧,不是系统组件。你可以把它理解为「让 LLM 在输出答案前先写草稿」,但不能把它当成「我的系统有 CoT 模块」来描述。正确的说法是「我们在 Prompt 里加入 step-by-step 要求」,而不是「我们的架构用了 CoT」。
第二个易错是把 ReAct 当成万能执行方案。ReAct 适合工具调用明确、观察结果结构化的场景,比如查数据库、调 API。如果任务需要先做探索性研究再决定调什么工具,ReAct 的固定循环会限制探索效率,应该用 Plan-and-Execute 先规划再执行。
第三个易错是把反思当事实核验。Reflexion 和 Self-Refine 的反思是「策略层面的自我修正」,不是「答案层面的事实查证」。你不能靠反思来纠正 LLM 的幻觉,因为反思本身也是 LLM 输出的,同样可能幻觉。反思机制适合代码质量、写作风格、结构完整性这类主观可量化指标,不适合事实准确性的自动校验。
8.3 三分钟回答模板和复习清单
三分钟模板分三段。
第一段 45 秒,讲框架:「Agent Loop 由五个设计点组成:规划决定下一步做什么,执行负责调用工具并获取观察,反思根据结果修正策略,记忆在不同粒度上存储上下文,终止条件决定什么时候停下来交给人。」
第二段 90 秒,讲范式:「从规划角度,有 CoT、ToT、GoT 做推理探索;从执行角度,有 ReAct 做思考-行动-观察闭环,有 Plan-and-Execute 做全局计划与局部执行分离;从反思角度,有 Reflexion 把失败写回记忆,有 Self-Refine 做生成-反馈-重写。记忆分三层:短期记忆用等宽窗口,长期记忆用向量检索,反思记忆用结构化标签。」
第三段 45 秒,讲生产:「线上要控制 token 消耗和延迟,设置 max_turns 硬上限,加循环检测软约束,失败时走 human_review 降级。面试时经常被追问 ReAct 能否先执行再思考、反思存短期还是长期、Plan-and-Execute 失败后回到哪一步,这些都考验你对范式边界的理解深度。」
复习清单:CoT/ToT/GoT 的搜索策略差异;ReAct 的 Thought→Action→Observation 三段式;Plan-and-Execute 的计划与执行解耦;Reflexion 的记忆回写机制;Self-Refine 的迭代反馈环;终止条件的硬上限、软检测、降级机制;五个设计点在 LangGraph 的组件映射。掌握这七点,Agent Loop 的面试题基本都能覆盖。
参考文献
[^1]: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models - https://arxiv.org/abs/2201.11903 [^2]: Large Language Models are Zero-Shot Reasoners - https://arxiv.org/abs/2205.11240 [^3]: Tree of Thoughts: Deliberate Problem Solving with Large Language Models - https://arxiv.org/abs/2305.10601 [^4]: Graph of Thoughts: Solving Elaborate Problems with Large Language Models - https://arxiv.org/abs/2308.09687 [^5]: Self-Consistency Improves Chain of Thought Reasoning in Language Models - https://arxiv.org/abs/2203.11171 [^8]: ReAct: Synergizing Reasoning and Acting in Language Models - https://arxiv.org/abs/2210.03629 [3]: HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face - https://arxiv.org/abs/2303.17580 [4]: ToolLLM: Augmenting Large Language Models with Tool Reasoning - https://arxiv.org/abs/2307.11690 [11]: ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models - https://arxiv.org/abs/2305.02323 [12]: Voyager: An Open-Ended Embodied Agent with Large Language Models - https://arxiv.org/abs/2305.16291 [13]: Gorilla: A Large Language Model for Software Test Generation - https://arxiv.org/abs/2307.06888

如果浏览器无法直接唤起微信,可在微信内打开公众号主页:计算机魔术师


