
上周有个做 Agent 平台的同学复盘面试,他以为 Skill 版本管理只是 SemVer 和发布流程,结果面试官连续追问:用户锁了 v1、新版灰度到 1%、旧版要废弃、两个 Skill 依赖冲突时,系统到底怎么保证稳定和可回滚。面试官不是在考概念,而是在测你面对真实治理复杂度时的决策链条。
一、为什么 Skill 版本管理决定系统能不能长期演进
1.1 面试官真正想听的不是定义,而是治理能力
Skill 版本管理的本质不是“给包打个号”,而是一套向后兼容的契约机制。当平台积累了几十个业务 Skill、几十个调用方时,每一次版本发布都可能是地震:某个 Skill 突然依赖冲突、某个用户的 Workflow 因为底层 Skill 升级而失效、灰度策略没做好导致 P0 故障。
面试官追问“锁版本+灰度+废弃”三件事同时发生时系统怎么跑,考核的是你是否有多层策略叠加的治理思维。不是背答案,而是说清楚:如果用户锁了 v1.2.3,平台还能给他推 v1.3.0 的热修吗?如果灰度 1% 用户遇到指标下跌,回滚链路怎么设计?旧版 Skill 被标记 deprecated 后,系统给用户多少窗口期?
核心回答框架:版本管理 = 版本策略 × 发布策略 × 迁移策略 × 依赖策略。四个维度缺一不可,面试时至少要能讲清前两个。
1.2 项目里最容易出事故的版本边界
实际项目中,版本事故通常发生在三类边界:
边界一:用户自主迁移时机 vs 平台强制推进的矛盾。用户锁了具体版本(如 skill/resume-parser@v1.2.3),平台发布 v2.0.0 大版本并标记 v1 为 deprecated。此时平台面临抉择:是强制用户在迁移窗口内升级,还是给锁版本用户提供独立的 v1 维护分支?大多数平台的工程取舍是锁版本用户走独立维护通道,直到迁移率低于阈值再关闭,避免因强制升级引发的客诉。
边界二:灰度指标观察期内的回滚决策。新版 Skill 灰度到 1% 用户后,延迟率从 5ms 跳到 45ms,平台要在多短时间内判断是调用方流量特性问题还是 Skill 本身问题?工程上通常设置双阈值告警:一级告警触发自动切回旧版(不影响用户),二级告警触发人工 review。这种灰度策略的工程实现需要 Skill 调度层支持同 Skill 多版本实例并行。
边界三:依赖解析时的循环依赖检测。当 Skill A 依赖 Skill B 的 v1,Skill B 依赖 Skill A 的 v2 时,系统要能检测并拒绝发布,同时给出清晰的依赖拓扑图告诉开发者冲突点在哪里。

这一段,面试官开始看你工程感了
yaml version: '1.0' title: 'Skill 版本管理核心机制' nodes:
- id: user-config label: '用户配置层' type: decision
- id: version-strategy
label: '版本策略'
type: process
children:
- lock-version
- semver-range
- latest-tracking
- id: publish-strategy
label: '发布策略'
type: process
children:
- canary-release
- full-rollout
- id: migration-strategy
label: '迁移策略'
type: process
children:
- deprecation-notice
- auto-migration
- forced-cutover
- id: dep-resolution
label: '依赖解析'
type: process
children:
- dep-graph
- cycle-detection
- version-conflict edges:
- from: user-config to: version-strategy
- from: version-strategy to: publish-strategy
- from: publish-strategy to: migration-strategy
- from: migration-strategy to: dep-resolution style: theme: blue-grey caption: 'Skill 版本管理四层策略叠加:用户配置→版本策略→发布策略→迁移策略,依赖解析贯穿全局'
二、五大核心机制拆解
2.1 锁版本策略:锁定具体版本 vs 跟随最新
用户在引用 Skill 时面临两种策略选择:锁定具体版本(如 skill@1.2.3)或跟随版本范围(如 skill@^1.2.0)。这与 npm 的 ~ 和 ^ 语义完全对应。锁定版本的用户在 Skill 发布新 patch 时不会自动感知,需要手动升级;跟随最新的用户则在兼容范围内自动获取更新,但也承担了引入 regression 的风险。
工程实践中,平台通常会设置默认行为:生产环境推荐锁版本并通过审批流程升级,测试环境允许跟随 latest 以便快速验证。关键是平台侧必须记录每个用户当前引用的 Skill 版本,而不是仅记录引用关系,否则回滚时无法定位到具体需要恢复的 Snapshot。
锁版本策略的语义对比,面试中容易被追问语义边界
2.2 多版本共存:v1/v2 同时运行的流量分配
当 Skill 从 v1 演进到 v2 时,平台需要同时托管两个版本,直到所有依赖方完成迁移。多版本共存的核心问题不是“能否共存”,而是“流量如何路由”。
常见方案有三种:按用户灰度(同一用户始终路由到同一版本,保证体验一致性)、按调用方标记(调用方显式声明所需版本,平台透传)、按 Skill 引用时间(用户在哪个时间点引用,就用当时的最新兼容版本)。第三种方案的工程实现成本最高,但用户体验最平滑——用户无需感知版本号,只需知道“我用的是我引用的那时候的版本”。
2.3 灰度发布:新版 Skill 先对 1% 用户生效
灰度发布是 Skill 系统中平衡稳定性与快速迭代的核心机制。平台需要在控制面实现流量分割,在数据面记录每个用户的版本归属,以便在发现 regression 时能够精准回滚。
典型的灰度策略采用金丝雀 + 指标监控组合:新版本先对 1% 用户生效,平台自动采集该批用户的任务成功率、响应延迟、错误率等指标,与存量用户基线做统计显著性检验。当指标恶化超过阈值(如 p99 延迟上涨 20%)时,触发自动回滚,无需人工介入。指标平稳则逐步扩大灰度比例至 10% → 50% → 100%。
这里有个面试高频追问陷阱:如果用户锁了 v1,但灰度策略覆盖了该用户,系统是否强制升级?正确答案是看 Skill 的变更级别——patch 和 minor 版本因不破坏兼容性,平台可以透明升级;major 版本因包含 breaking changes,必须用户主动确认才能迁移。平台侧需要维护每套 Skill 的兼容性矩阵,提前标注哪些版本之间是 safe to auto-upgrade。
2.4 Deprecation 流程:通知期 + 自动迁移 guide
当 Skill 需要废弃某个历史版本时,平台必须提供清晰的 Deprecation 流程,否则会导致用户依赖悬空、任务无法执行。标准流程包含三个阶段:
第一阶段:公示期。在 Skill 页面、版本列表和用户 Dashboard 明确标注废弃版本,显示 EOL(End of Life)倒计时。平台通过 Webhook 或邮件通知所有引用了该版本的用户,提供迁移到哪个具体版本的建议。
第二阶段:引导迁移。平台为每个废弃版本生成 Migration Guide,包含 API 变更对照表、代码迁移示例、常见问题排查。最好能提供自动化迁移工具(如 AST 重写脚本),降低用户迁移成本。
第三阶段:强制下线。公示期结束后,平台在执行时拒绝加载废弃版本,返回明确的错误信息并重定向到最新稳定版。这一步必须谨慎——如果用户任务正在运行中,应该让任务完成再拒绝新请求,而不是强制中断。
2.5 依赖关系解析与循环依赖检测
当 Skill A 依赖 Skill B,Skill B 又依赖 Skill C 时,平台需要解析完整的依赖图,并在发布变更前验证兼容性。更复杂的情况是两个 Skill 相互依赖——Skill A 声明了对 Skill B 的依赖,Skill B 也声明了对 Skill A 的依赖,这会形成循环依赖。
循环依赖检测应在 Skill 注册时触发,而非运行时兜底。平台维护一个有向无环图(DAG),每次 Skill 提交新版本时,对新增的依赖声明做拓扑排序,如果检测到环则拒绝发布。检测算法本身不复杂(DFS 或 Kahn 算法),但容易忽略的是依赖版本范围:即使 Skill A@1.0 和 Skill B@1.0 不循环,但 Skill A@1.0 依赖 Skill B@2.0,Skill B@2.0 反过来依赖 Skill A@1.0,这种跨版本的循环同样会导致问题。
依赖冲突的仲裁策略也是高频追问点:当 Skill A 需要 Skill C@^1.0.0,Skill B 需要 Skill C@~1.2.0 时,平台需要找到同时满足两个约束的版本。npm 使用的语义是选择符合两个约束的最小版本(在 ^1.0.0 和 ~1.2.0 的交集里选最小),但如果交集为空,平台应该报错而非静默选择其中一个——静默覆盖会导致用户预期与实际行为不符。
{"title":"【AI面试八股文 Vol.2.5:Skill】Skill 版本管理:锁版本、多版本共存、Deprecation、依赖解析和灰度发布","summary":"围绕 Skill 版本管理展开,串讲多版本共存、灰度发布、用户引用策略、Deprecation 流程与依赖解析四大机制,重点讲清机制原理、工程边界和真实取舍。","opening_hook":"","outline_markdown":"## 二、核心机制拆解
2.1 多版本共存:v1 / v2 同时运行,用户自主迁移时机
2.2 灰度发布:新版 Skill 先对 1% 用户生效,观察指标后全量
2.3 用户 Skill 引用策略:锁定具体版本 vs 跟随最新(类比 npm ^ 语义)
2.4 Deprecation 流程:通知期 + 自动迁移 migration guide
2.5 Skill 依赖关系解析与循环依赖检测","word_count":1334,"body_markdown":"上周有个做 Agent 平台的同学复盘面试,他以为 Skill 版本管理只是 SemVer 和发布流程,结果面试官连续追问:用户锁了 v1、新版灰度到 1%、旧版要废弃、两个 Skill 依赖冲突时,系统到底怎么保证稳定和可回滚
二、核心机制拆解
2.1 多版本共存:v1 / v2 同时运行,用户自主迁移时机
多版本共存是 Skill 系统的韧性所在。平台在发布 v2 时,不会强制下线 v1,而是让两个版本同时注册到版本索引中,每个版本携带完整的元数据:依赖声明、接口签名、能力标签和最低运行环境要求。
用户自主迁移的时机选择是系统设计的分水岭。激进方案是 v2 发布后立即置顶 v2,v1 仅保留在"历史版本"入口,适合能力跃迁明显、用户有强动力升级的场景。保守方案是 v2 发布后保持 v1 为默认,用户需主动切换,适合企业级 Skill —— 一次不经意的强制升级可能导致下游工作流断裂。
版本策略的选择,映射的是平台对用户工作流稳定性的尊重程度
平台侧需要提供的最小能力是:版本感知路由。用户在引用 Skill 时,系统能识别其锁定的版本,并将其请求路由到对应的执行环境,而不是强制重定向到最新版本。这个能力通常在 Skill Registry 层实现:每个用户的 Skill 绑定记录中存储 skill_id + version,执行时以此为准。
2.2 灰度发布:新版 Skill 先对 1% 用户生效,观察指标后全量
灰度发布是可控上线节奏的核心手段。平台对新版 Skill 的灰度策略通常分三阶段:
灰度阶段(1%~10% 用户池):新版本 Skill 对小比例用户可见,平台开启增强监控,收集执行成功率、响应延迟、异常率等指标。这个阶段核心目标是验证"新版本在生产环境下不会崩溃"。
扩量阶段(10%~50%):指标达标后逐步扩大用户比例,同时开启特性开关,允许特定用户群(如企业租户)选择降级回 v1。这个阶段验证"新版本对不同用户画像无差异化问题"。
全量阶段(100%):所有用户切换到新版本,旧版本保留一段时间后下线。整个流程中,回滚策略始终在线:任意时刻发现指标异常,可立即将流量切回旧版本,执行环境保持热备状态。
灰度发布的核心价值是把"爆炸半径"从全局收敛到百分比
灰度发布的技术支撑来自两个能力:流量分级路由(基于用户 ID 哈希或租户标签做流量拆分)和版本热备环境(旧版本执行镜像不销毁,随时可回切)。没有这两点,灰度只是"手动把用户分批切到新版本",谈不上可控。
2.3 用户 Skill 引用策略:锁定具体版本 vs 跟随最新(类比 npm ^ 语义)
用户在代码或配置中引用 Skill 时,有两种主流策略:
锁定具体版本(skill://data-processor@v1.2.0):精确到 patch 级别,每次部署使用的 Skill 二进制完全一致。这是最保守的策略,适合对执行结果有严格幂等性要求的工作流,任何非预期的 Skill 变更都可能导致下游结果漂移。
跟随主版本最新(skill://data-processor@^1):Major 版本不变时自动跟随 minor/patch 升级,自动吸收 bug 修复和性能优化,但不跨越 breaking change 边界。这是对标 npm 的 ^ 语义的策略,平衡了安全性和新鲜度。
平台需要实现版本解析器,在用户每次发起 Skill 调用时,动态将引用解析为具体版本号:锁定版本直接返回;跟随最新则查询 Registry 中该 Major 分支的最新版本,并做兼容性校验。
这里有个典型面试追问:如果用户锁了 v1,而平台要强制废弃 v1,系统怎么处理? 答案是平台无权强制覆盖用户引用记录,只能通过 Deprecation 流程通知用户,并提供迁移工具。如果用户坚持不迁移,平台侧可以做的是:在 v1 执行环境上追加安全补丁(不升级功能版本),同时给用户展示明确的"你的工作流运行在已废弃版本上,存在安全风险"警告。
2.4 Deprecation 流程:通知期 + 自动迁移 migration guide
Deprecation 不是简单"标记然后删除",而是一个有法律效力的过渡协议。一个完整的 Deprecation 流程包含:
通知期(通常 30~90 天):平台在 Skill 详情页、用户工作台和 API 响应 header 中持续展示废弃警告,警告中必须包含:废弃生效时间、推荐迁移目标版本、自动迁移工具入口。
迁移 guide 自动生成:平台根据两个版本之间的 diff,自动生成迁移变更点说明 —— 哪些 API 签名变了、哪些参数被移除、哪些行为不再向后兼容。如果 Skill 有结构化定义(类似 Claude Code Skills 的 Manifest),这一步可以由平台自动推断;如果 Skill 是非结构化的描述性文档,则需要 maintainer 手动编写。
Deprecation 的质量,反映的是平台对用户技术债务的尊重程度
强制废弃后的兜底策略:通知期结束后,平台保留 Skill 的只读元数据(可查询不可执行),并给仍然引用的用户返回明确的 HTTP 410 Gone,响应体中携带迁移指引 URL。这比直接 404 更友好,让用户有迹可循。
2.5 Skill 依赖关系解析与循环依赖检测
当 Skill A 的执行依赖 Skill B 的能力时,系统需要维护一张依赖图。依赖解析的核心问题是:如何保证用户引用的 Skill 链不会在某个环节断裂?
平台在 Skill 发布时,要求 maintainer 声明 dependencies 字段(类比 package.json)。解析器在用户绑定 Skill 时,以递归方式展开依赖树,检查:依赖版本是否兼容当前平台运行时;是否存在版本冲突(同 Skill 的两个不同主版本同时出现在依赖链中);是否存在循环依赖。
循环依赖是 Skill 生态的硬性禁区:Skill A 依赖 Skill B,Skill B 依赖 Skill C,Skill C 依赖 Skill A —— 这种结构在执行时会陷入死锁。平台在发布时必须运行循环检测算法(Tarjan 算法或 DFS 环检测),一旦检测到环,直接拒绝发布并返回错误。
yaml skill: id: github-code-review version: 1.2.3 description: 自动化 GitHub PR 代码审查 Skill entry: run.py dependencies: - id: github-api-wrapper version: ">=2.0.0,<3.0.0" - id: llm-judge-engine version: "^1.5.0" capabilities: - analyze_pr_changes - generate_review_comments runtime_constraints: max_execution_time: 300 memory_limit: 512MB

> Skill manifest 结构:ID + 版本 + 依赖 + 运行时约束
这里 version 字段用 SemVer 语义,dependencies 里的 version specifier 借鉴了 npm 的 ^、>=、< 语法,让 Skill 作者可以声明兼容性范围。
Registry(注册表)是这些 manifest 的集中存储,提供版本查询、依赖解析和发布审核能力。运行态(Runtime)则在 Agent 执行时从 Registry 按引用策略拉取对应版本,实例化到隔离的沙箱里执行。这三者的边界必须清晰:
1. **Registry 负责元数据**:只存 manifest、版本索引、依赖图谱,不负责 Skill 代码的实际执行。
2. **运行态负责执行隔离**:每次 Skill 调用都在独立的容器或进程里跑,防止版本间互相影响。
3. **manifest 是唯一契约**:Skill 的能力集和依赖声明以 manifest 为准,任何时候代码变更必须同步更新 manifest 版本号。
很多项目出事故的原因是把这三个边界混在一起——比如让 Registry 直接调用 Skill 代码,或者运行时直接读仓库源码而不走 manifest 版本校验。一旦依赖版本对不上,轻则能力退化,重则运行时崩溃。
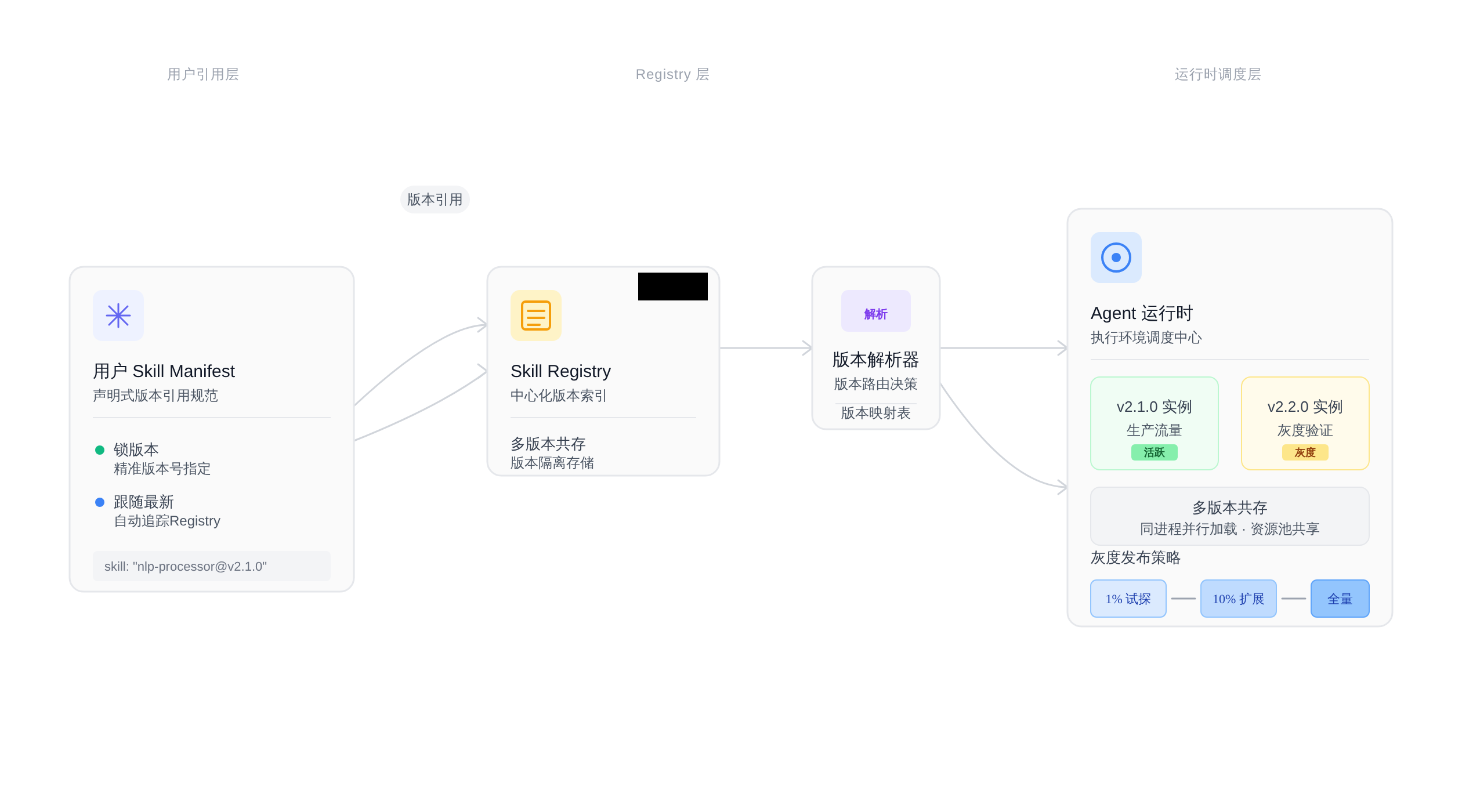
> Skill 版本管理三组件边界
### 3.2 CI 校验、灰度发布、回滚和审计链路
有了数据模型,接下来是发布流水线怎么把版本安全地推到用户手里。典型链路分四步:
**第一步:CI 校验。** Skill 提交 PR 时,CI 自动跑依赖冲突检测、版本号规范校验(必须是合法 SemVer)、manifest schema 验证,以及单元测试和集成测试。如果 Skill 声明了依赖,CI 还要跑兼容性矩阵——确保新版本和下游 Skill 的兼容范围有交集。这一步是守门员,很多团队省掉兼容矩阵测试,上线后才发现新版 Skill 破坏了某个依赖方的能力。
**第二步:灰度发布。** 修完 CI 进入正式发布流程,采用灰度策略:先对内部用户或 1% 线上用户生效,观察错误率、延迟和业务指标(TPS、成功率),稳定后再扩量。全量发布后旧版本不立即下线,而是保持存活一段时间,供仍锁定了旧版本的用户使用。灰度阶段的核心监控指标包括 Skill 执行时长分布、Token 消耗异常、调用成功率,以及 LLM judge 的评分漂移。
**第三步:回滚机制。** 如果灰度期间指标恶化,需要能快速回滚到上一版本。技术上依赖 Registry 的版本隔离能力和运行时的热切换能力——运行态拉取新版本失败时,自动降级到用户锁定的旧版本。这个降级路径必须在设计阶段就写进架构文档,而不是出问题再临时加。
**第四步:审计链路。** 所有版本发布、用户引用变更、Deprecation 通知都记录到审计日志里,供安全合规和故障溯源使用。典型字段包括操作者身份、操作时间戳、操作类型(发布/回滚/Deprecate)、涉及的 Skill ID 和版本号、受影响的用户数。

> 这一段,面试官开始看你工程感了:CI 怎么卡位、灰度怎么监控、回滚怎么落地
落到面试回答里,这套流水线可以用一句话收尾:**我们用 Registry 做版本索引,用 CI 卡住兼容性和规范,用灰度阶段验证线上表现,用审计日志做事后追溯。** 面试官追问细节时可以逐层展开:CI 跑什么检测、灰度指标怎么选、回滚的降级路径怎么走。
回到开篇那个同学的复盘——他被问住的本质,不是不知道 SemVer,而是没想过把版本管理当成一个系统工程:从用户可以锁版本,到 Registry 能索引多个版本,到灰度能逐步放量,到旧版本能保持存活。这整条链路才是面试官想听的东西。
这些追问串起来就是一道完整的系统设计题,考的不是你背没背概念,而是你在真实项目里踩过多少坑、想过多少边界情况
## 四、典型追问与易错边界
### 4.1 锁版本 vs 跟随最新怎么取舍
面试官抛出的第一个陷阱题往往是:你的 Skill 引用策略是锁死版本还是跟随 latest?看似二选一,实际考的是你对业务场景的判断力。
**锁定具体版本的适用场景**:生产环境跑核心业务流程、依赖强一致性保证、审计合规要求严格。这种模式类比 npm 的 "1.2.3" 精确语义,用户拿到的是稳定可复现的执行态。风险在于长期不更新会积累安全漏洞和兼容性债务。
**跟随最新(latest tag 或 SemVer range)的适用场景**:内部工具、快速迭代的实验性 Skill、愿意承担更新成本的团队。这类似 npm 的 "^1.2.0" 或 Python 的 ">=1.2.0,<2.0.0" 语义。风险在于语义化版本如果维护不规范,major 升级可能直接炸掉下游。
真正的工程取舍是**分层策略**:核心业务 Skill 锁版本 + 定期 review + 强制 CI 校验;内部工具 Skill 跟随最新 + 灰度验证 + 快速回滚机制。如果你回答“我全锁死”或“我全跟最新”,面试官会立刻追问边界 case,这恰恰暴露了你没有思考过代价。

> 这一段,面试官开始看你工程感了
### 4.2 多版本共存什么时候该保留,什么时候该强迁移
多版本共存是双刃剑:保留能保护用户迁移窗口,但维护成本随版本数指数增长。面试官想知道你是否有清晰的决策框架。
**应该保留多版本的场景**:用户量级大且迁移意愿分散、旧版本有不可替代的能力(如 v1 支持某 legacy API,v2 移除了但部分用户强依赖)、Deprecation 通知期内的过渡态。这时候系统要做的是提供清晰的迁移路径、监控两套版本的错误率差异、设置明确的时间窗口。
**应该强迁移的场景**:旧版本存在安全漏洞且无补丁计划、协议层变更导致必须 break、两版本同时维护的成本超过迁移成本。强迁移不是一刀切砍掉,而是在给了充分通知和迁移工具后,对超期未迁移的用户执行强制切换,并在日志里留下可追溯的审计记录。
很多团队踩的坑是:要么永远保留旧版本导致技术债堆积,要么强迁太激进导致用户流失。好的做法是**设定明确的 Deprecation 时间线**(比如 v1 保留 6 个月,通知期内每周提醒,末期提供自动化迁移脚本),让用户有预期,也让自己的运维边界清晰。
### 4.3 依赖冲突和循环依赖怎么发现、怎么阻断
Skill 之间有依赖关系是常态,但依赖解析失败或循环依赖会直接让系统跑不起来。面试官会假设你已经踩过这种坑,追问你的检测和兜底方案。
**依赖冲突的发现机制**:CI 阶段做 manifest 解析,构建依赖图,检测版本范围重叠导致的冲突。比如 Skill A 依赖 B >= 1.0 且 < 2.0,Skill C 依赖 B >= 2.0,这时候系统要能识别出不可调和的版本约束,并在发布前阻断。
**循环依赖的检测与阻断**:通过拓扑排序在构建时检测环路,一旦发现 Skill A 依赖 B 且 B 依赖 A,直接拒绝发布并给出清晰的错误路径。运行时如果出现循环依赖,通常表现为调用栈溢出或超时,这时候除了阻断发布,还要在 CI 里加自动化测试用例覆盖常见的循环依赖 pattern。
**工程边界上的坑**:很多人忽略了传递依赖的循环,比如 A→B→C→A 这种三层环路检测起来比直接 A→A 复杂得多。另外,条件依赖(仅在特定条件下触发的依赖)也可能隐藏循环,静态分析要配合动态测试一起跑。
如果面试官继续追问“线上跑着跑着发现依赖冲突怎么办”,你要能答出三层兜底:CI 强制校验(发布前阻断)、运行时降级(部分功能不可用但核心流程保命)、监控告警(第一时间发现问题而不是等用户报障)。这三个层次对应的是工程上从预防到发现到恢复的完整链路,也是面试官判断你是否有真实 SRE 思维的关键。
## 五、核心复习清单与回答框架
### 5.1 必背关键词速查
| 概念 | 核心要点 | 易踩坑 |
|------|----------|--------|
| 锁版本 | 绑定 manifest 中具体版本号 | 升级时需用户主动触发 |
| 跟随最新 | 类似 npm ^ 语义,自动匹配兼容版本 | 可能引入静默破坏性变更 |
| 多版本共存 | Registry 层并行存储,用户按需引用 | 存储成本与运维复杂度 |
| 灰度发布 | 分级流量策略,从 1% → 10% → 100% | 指标回滚阈值设计 |
| Deprecation | 通知期 + 迁移 guide + 强迁移时间窗口 | 过度期用户流失 |
| 依赖解析 | DAG 拓扑排序,循环依赖检测阻断 | 跨团队依赖协调 |
### 5.2 典型追问快速应答
**Q: 为什么推荐锁版本而不是跟随最新?**
> 锁版本保证了用户环境的确定性,跟随最新虽然能享受 bug 修复,但引入了"静默破坏"风险。类比生产环境的 npm 包管理:CI 锁 package-lock.json,Dev 允许 ^ 快速迭代。Skill 同理:核心业务 Skill 必须锁版本,非关键工具 Skill 可跟随最新。
**Q: 多版本共存什么时候该保留?**
> 三看原则:看用户基数(>20% 仍在用旧版则保留)、看迁移成本(用户有持久化状态无法热升级)、看破坏程度(API 签名变更必须强迁移,纯实现优化可共存)。
**Q: 循环依赖怎么发现、怎么阻断?**
> 构建时用拓扑排序遍历依赖图,检测到闭环立即报错并输出环路径。阻断策略可选:ERROR(直接阻断发布)、WARN(允许发布但页面警示)。生产级系统推荐 ERROR 策略。
### 5.3 一句话总结(面试收尾用)
> Skill 版本管理的本质是 **在灵活性与稳定性之间找到工程化平衡**:锁版本保稳定、灰度控风险、Deprecation 给过渡、依赖解析防循环。
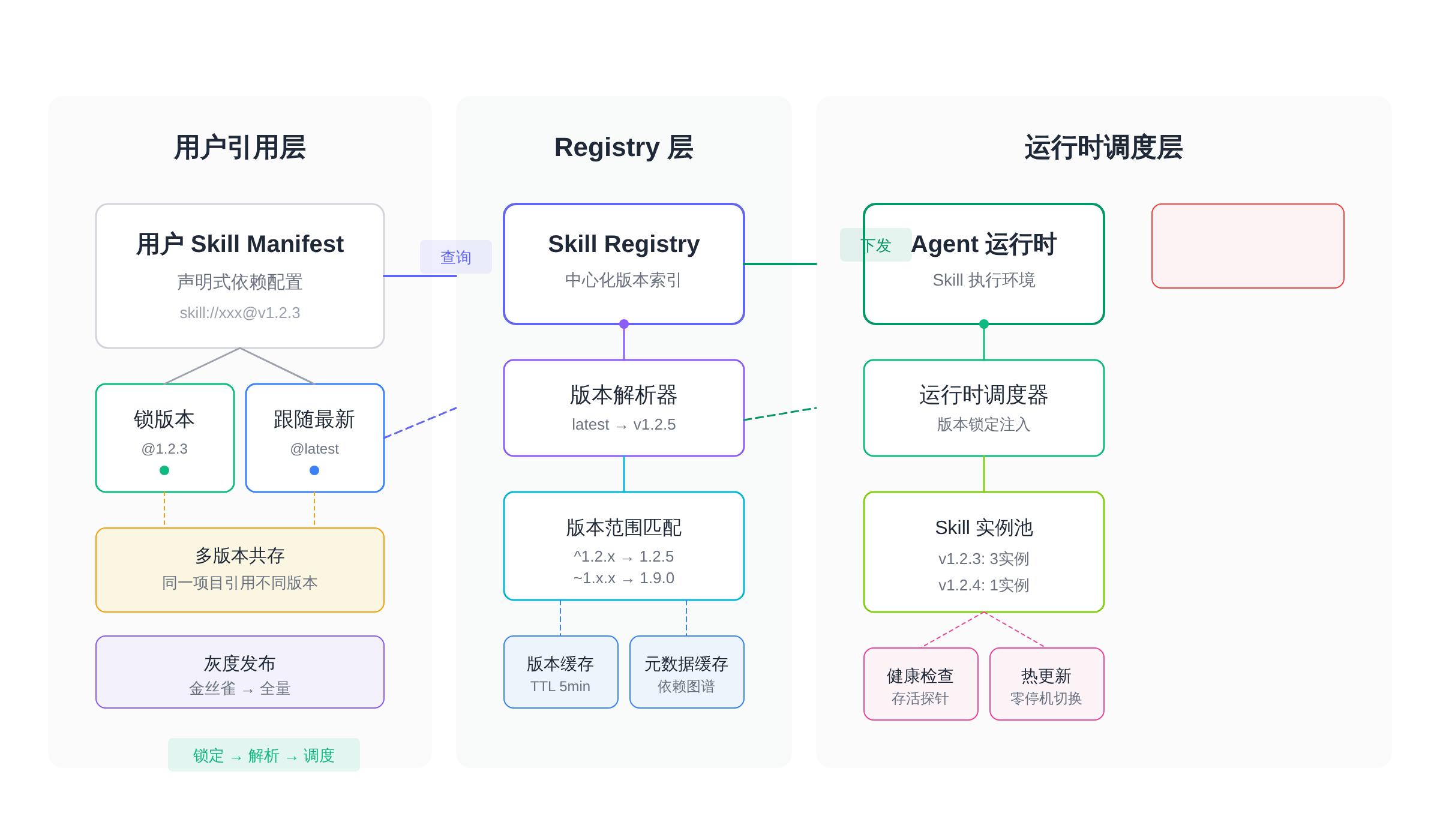
> Skill 版本管理全链路架构:用户引用层 → Registry 层 → 运行时调度层

> 这一段,面试官开始看你工程感了
## 参考文献
1. Semantic Versioning 2.0.0 - https://semver.org/
2. npm Docs: About semantic versioning - https://www.npmjs.com/about-semantic-versioning
3. GitHub Docs: About releases - https://docs.github.com/en/repositories/releasing-projects-on-github/about-releases
4. Claude Platform Docs: Agent Skills overview - https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview
5. Model Context Protocol Specification: Lifecycle - https://modelcontextprotocol.io/specification/2025-06-18/basic/lifecycle
---

<div class="hexo-wechat-follow-card" style="margin:28px 0 0;padding:16px 18px;border:1px solid #dbe7f3;border-radius:14px;background:#f8fbff;"><a href="weixin://profile/gh_1ab72c968bef" style="font-weight:700;color:#0f5b9f;text-decoration:none;">点这里一键关注『计算机魔术师』</a><p style="margin:8px 0 0;font-size:13px;color:#6f8299;line-height:1.7;">如果浏览器无法直接唤起微信,可在微信内打开公众号主页:<a href="https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=MzkwNjQyOTUwOA==#wechat_redirect" style="color:#0f5b9f;text-decoration:none;">计算机魔术师</a></p></div>


