
2026 年 4 月的 GTC 之后,如果你还在只盯着 H100 的租用价格做预算,那这份预算表大概率下个季度就得作废。
NVIDIA 刚刚交出的 FY2026 财报显示全年营收冲到了 2159 亿美元,同比增长 65%,净利润率超过 55%1。这本来应该是一场狂欢,但股价却从高点回落了将近 20%1。
这种反差本身就值得玩味:市场在担心什么?更重要的是,这种担心会如何传导到每一个正在做架构选型和成本核算的工程师头上?
这不仅仅是二级市场的情绪波动,而是整个行业正在经历从“训练军备竞赛”到“推理落地战争”的转折信号。
当 NVIDIA 把下一代 Rubin 架构的推理吞吐量拉到 Blackwell 的 3 倍,又花 200 亿美元买下做推理专用芯片的 Groq 时,基础设施的成本模型其实已经被重写了。
如果你还在用去年的经验估算今年的算力成本,很可能会在项目立项阶段就埋下隐患。
01. 2159 亿美元背后的“AI 税”与市场焦虑
财报里的信号与噪音
翻开 NVIDIA 的 FY2026 财报,最直观的冲击来自数字本身:数据中心业务营收 1923 亿美元,占总营收的 89%1。
这意味着 NVIDIA 已经不再是一家游戏显卡公司,甚至不再是一家通用 GPU 公司,它本质上变成了一家向全球科技公司征收“AI 税”的机构。
任何想要在 AI 领域有所动作的公司,无论是训练大模型还是部署 AI 应用,第一笔硬性支出就是给 NVIDIA 交钱。
这种极高的议价权反映在财务报表上,就是 55% 的净利润率——作为对比,同属芯片巨头的 Intel,净利润率常年徘徊在个位数,甚至一度为负。
但市场从来不是只看过去的数字。股价下跌 20% 的核心原因,在于增速放缓的预期。
从 100% 以上的同比增长回落到 65%,虽然绝对值依然惊人,但对于支撑起万亿美元市值的预期来说,这被视为一种“不及格”。更关键的信号在于,华尔街开始质疑下游客户的变现能力。
Microsoft 一年在 AI 基础设施上投入超过 500 亿美元,但 Copilot 的营收目前还远远覆盖不了这笔投入1。如果下游应用赚不到钱,上游的算力需求迟早会面临回调。
这种焦虑并非空穴来风。
为什么华尔街在担心
NVIDIA 在 GTC 2026 上抛出的 1 万亿美元订单预测,覆盖了 2025 至 2027 年2。这虽然展示了需求端的强劲,但也侧面印证了一个事实:大客户们正在疯狂囤卡,但囤卡不等于赚钱。
Wolfe Research 的分析师 Chris Caso 指出,这 1 万亿美元更像是一个“地板”而非“天花板”2,但这建立在一个假设之上——AI 应用的商业化能够如期兑现。
OpenAI 承诺部署至少 10 千兆瓦的 NVIDIA 系统,Anthropic 承诺 1 千兆瓦,CoreWeave 目标是到 2030 年超过 5 千兆瓦的 AI 工厂3。
这些数字宏大,但每一瓦特背后都是真金白银的投入,需要真实的用户付费来买单。

需求是真实的,但变现账单还在路上
对于工程师而言,这种宏观层面的焦虑会直接转化为项目层面的压力。
资本开支(Capex)不会无限制扩张,当 CFO 开始审视 AI 投入的 ROI 时,基础设施团队面临的第一个问题往往就是:“能不能用更少的卡,跑出同样的效果?”
这不再是一个单纯的技术优化问题,而是一个关乎项目生死的商业命题。
AWS 宣布购买 100 万颗 NVIDIA GPU 用于推理操作,交易价值预计超过 300 亿美元1,这看似是对 NVIDIA 的信任票,实则也包含了对成本控制的迫切需求——必须通过规模化部署来摊薄推理成本。
02. Rubin 架构:从“训练为王”到“推理为王”的转折
性能参数里的成本革命
如果说财报反映的是市场情绪,那么 Rubin 架构的参数则揭示了技术演进的真实方向。根据 AIEII 的分析,Rubin 的推理吞吐量是 Blackwell 的 3 倍,但功耗只增加了 40%4。
换算成最直观的指标:每 token 的推理成本,Rubin 能做到 Blackwell 的三分之一。这不仅仅是性能的提升,这是一场成本结构的革命。
过去三年,AI 行业的主旋律是“训练”。谁有更多的 H100,谁就能训练出更大的模型,谁就拥有话语权。但到了 2026 年,情况发生了变化。
基础模型的参数量增长开始遭遇边际效用递减,GPT-5 级别的模型虽然强大,但训练成本已经高到只有少数巨头能负担得起。
与此同时,随着 AI 应用渗透进搜索、办公、代码编写等场景,推理请求量正在呈指数级爆发。
Rubin 正是为这个拐点设计的:它不再一味追求训练时的双精度浮点性能,而是针对推理场景的低精度计算进行了极致优化。
配合 HBM4 高带宽内存和 NVLink 6 互联技术,Rubin 在处理大规模 Token 并发时,能效比达到了前所未有的高度。
架构演进:Ampere 到 Rubin 的路线图
从 Ampere(A100)到 Hopper(H100),再到 Blackwell(B200),NVIDIA 的架构演进逻辑一直是在堆高训练性能的上限。
但 Rubin(R100)的出现,标志着路线图的分叉。它不再只是“更强的 GPU”,而是开始分化出专门的推理特性。
这种分化在技术路线上体现为对内存带宽、互联延迟以及低精度计算单元的重新设计。
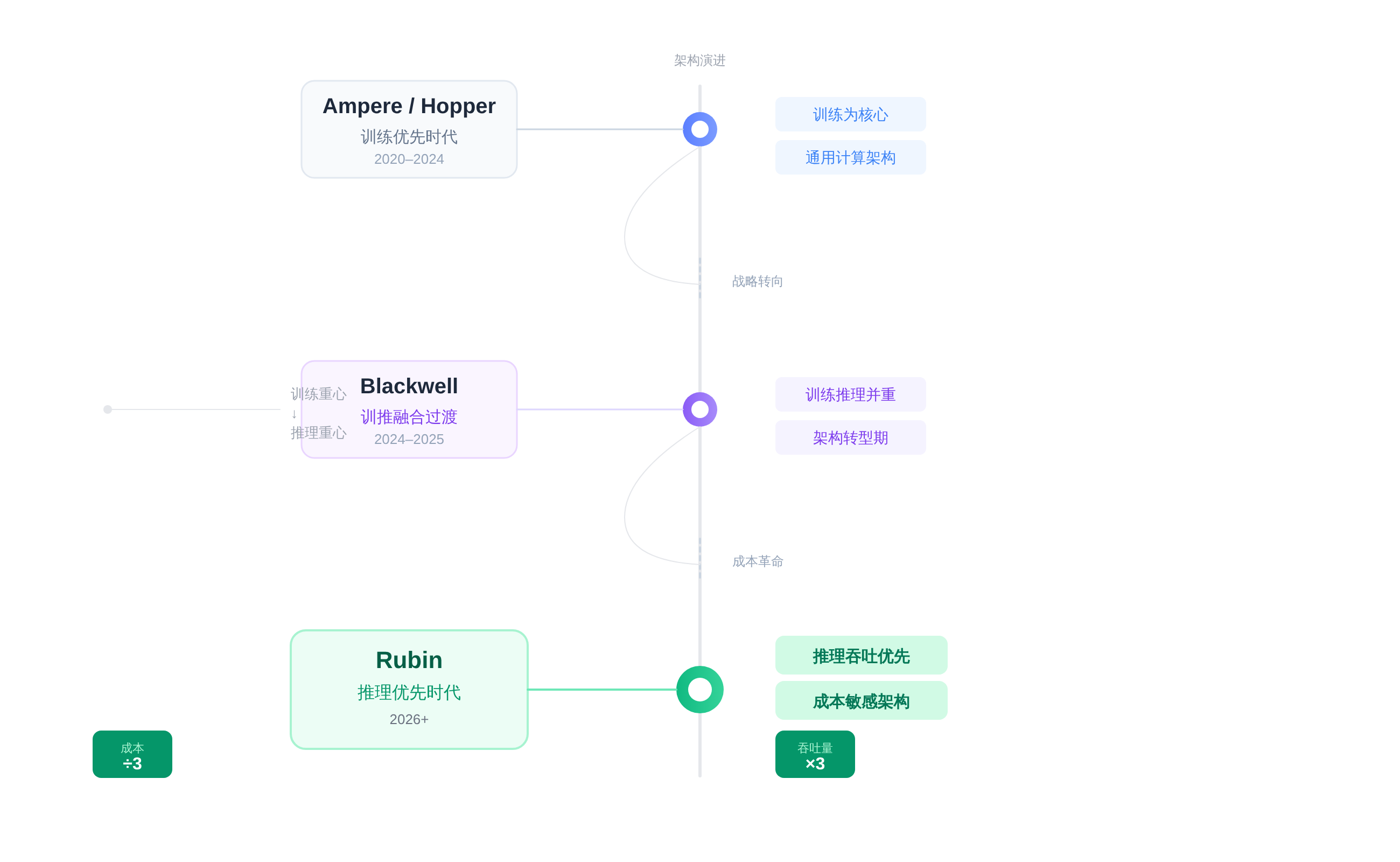
这种架构变化对工程师的选型影响巨大。在 Hopper 时代,我们习惯了用同一套硬件既做训练也做推理,虽然效率不是最优,但胜在运维简单。
到了 Rubin 时代,这种“一刀切”的方案在成本上将不再具备竞争力。训推分离不再是一个可选项,而是一个必选项。
如果你的团队还在用训练集群直接承载线上推理流量,那么在 Rubin 面前,你的单位算力成本可能比竞争对手高出两倍。

预算表还没批,技术路线先翻了
03. 收购 Groq:防御性布局与 LPU 的崛起
为什么要花 200 亿买一家推理公司
如果说 Rubin 是 NVIDIA 在 GPU 架构内部的自我革命,那么以 200 亿美元收购 Groq 则是对外部威胁的防御性布局。
Groq 做的不是 GPU,而是 LPU(Language Processing Unit)。它的设计理念非常极端:放弃图形渲染和通用计算能力,专为大语言模型推理设计。
这种“偏科生”在特定场景下极其强悍——推理速度能达到 GPU 的 10 到 20 倍,延迟低至毫秒级5。
NVIDIA 买 Groq 的逻辑很清晰:与其等着 Groq 联合其他云厂商在推理市场撕开缺口,不如把它收编进自己的生态。
新的 Groq 3 LPX 推理加速器将与 Rubin 搭配销售,形成“训练用 Rubin,推理用 Groq”的组合拳1。
这实际上是承认了一个事实:GPU 并不是推理场景的最优解,它只是目前生态最成熟的解。通过收购,NVIDIA 把“最优解”也纳入了自己的版图。
值得注意的是,NVIDIA 还宣布恢复 H200 芯片的生产,并推出符合出口管制的中国版 Groq 3 芯片4。
这一举动预计将每年带来约 320 亿美元的收入,这原本在 Q1 指引中是被排除在外的。
这说明 NVIDIA 正在全方位地巩固其在推理市场的统治力,从高端的 Rubin+Groq 组合到合规版的中端芯片,寸土不让。
GPU 与 LPU 的分工边界
这笔收购给基础设施架构带来的最大变化,是明确了 GPU 与 LPU 的分工边界。
在未来的算力集群里,GPU(Rubin)将主要负责模型训练、微调以及复杂的混合专家模型路由,而 LPU(Groq)则负责高并发、低延迟的在线推理。
这种分工将彻底改变目前“一卡多用”的现状。
架构又要重构了,这回是因为省钱
对于工程师来说,这意味着技术栈的复杂度上升了。你不仅要懂 CUDA 编程,还要懂 LPU 的编译优化;不仅要管理训练集群的调度,还要处理异构推理集群的流量分发。
但回报也是丰厚的:在实时对话、自动驾驶决策等对延迟敏感的场景,LPU 能提供 GPU 无法企及的性能,而且成本更低。这不再是简单的硬件升级,而是整个软件栈和运维体系的重构。
04. 工程师决策:基础设施成本模型的重构
推理成本下降 60% 意味着什么
根据行业预测,随着 Rubin 量产和 Groq 的加入,AI 推理成本将在 12 个月内下降 60% 到 70%3。这个数字听起来很抽象,但如果把它放到具体业务场景里,冲击力是巨大的。
假设你的团队目前每月在推理 API 上的支出是 10 万美元,明年同期这笔钱可能只需要 3 万到 4 万美元。或者反过来说,同样的预算,你可以支撑 3 倍以上的用户请求量。
这直接改变了产品的商业逻辑。很多在 2025 年因为“太贵了做不起”而被砍掉的功能,在 2026 年下半年可能就会变成“不做不行”的标配。
比如长上下文的实时文档分析、多模态的智能客服,这些曾经因为推理成本过高而无法规模化的应用,都将迎来爆发窗口。
工程师在做技术可行性评估时,不能再沿用去年的成本假设,否则很可能会误判产品的盈利模型。
AMD 的 MI300 系列已经在推理市场拿到了约 15% 的份额1,竞争加剧本身也会进一步压低市场价格。NVIDIA 不再是唯一的玩家,但它依然是规则的定义者。
训推分离架构的落地路径
面对这种变化,最务实的应对策略是提前布局“训推分离”架构。这不仅仅是把训练和推理部署在不同的物理机上,而是要在软件层面做彻底的解耦。
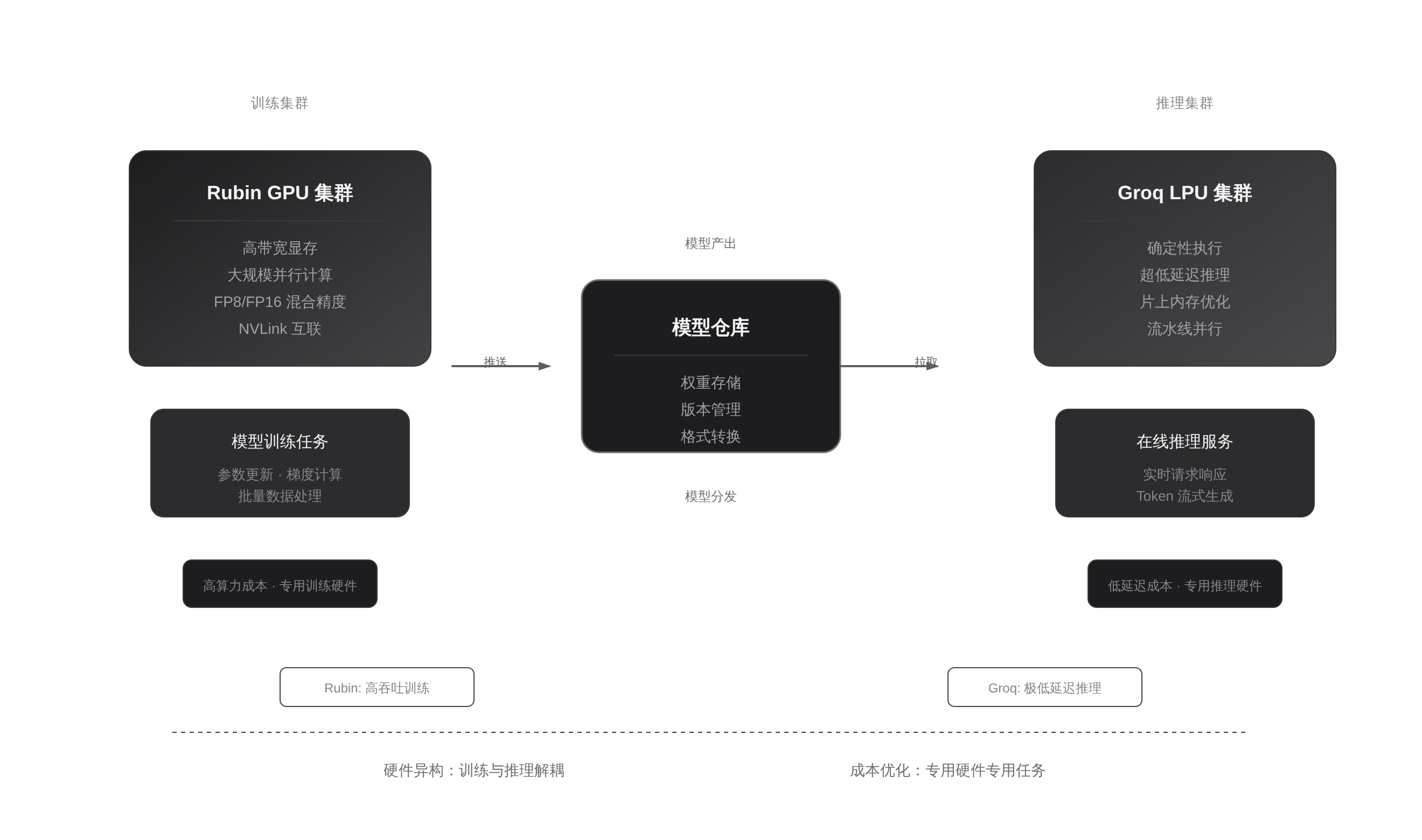
首先,在模型层面,需要针对不同硬件准备不同的量化版本。为 Rubin 准备的高精度模型用于训练和复杂推理,为 Groq 准备的极低精度模型用于高并发场景。
其次,在流量调度层面,需要根据请求的延迟要求和成本预算,动态路由到不同的推理后端。这要求基础设施团队具备更精细化的流量治理能力。
最后,在监控层面,不能只看 QPS 和延迟,还要把“每千次请求成本”作为核心指标纳入观测体系。未来的架构优化,将不再是单纯的性能优化,而是成本与性能的博弈。

省钱也是一种技术能力
写在最后
从 Blackwell 到 Rubin,从 GPU 到 LPU,NVIDIA 正在用一种近乎激进的方式推动行业从“训练崇拜”走向“推理务实”。对于工程师而言,这既是挑战也是机会。
挑战在于,我们熟悉的“堆卡”逻辑正在失效,取而代之的是更复杂的异构计算和成本博弈;机会在于,算力成本的下降将解锁大量以前无法落地的应用场景。
未来的基础设施竞争,不再是比谁卡多,而是比谁算得精。当推理成本打掉三分之二,你准备好重构你的架构了吗?
风险提示与免责声明:本文仅整理公开信息与免费工具用法,不构成任何投资建议、目标价判断或买卖依据。
参考文献
如果你想继续追更,欢迎在公众号 计算机魔术师 找到我。后续的新稿、精选合集和阶段性复盘,会优先在那里做串联。


