周一早上,你打开云账单,发现 Token 费用比上周涨了 200%。你试图在日志里找出是哪个用户的哪个请求烧掉了预算,结果 PostgreSQL 的查询转了五分钟还没出结果。
这时候你才意识到,LLM 应用的可观测性,如果存储架构扛不住,就是一句空话。

这一段,懂的都懂
这不是个例。
当你的应用从 Demo 走向生产,每一次 LLM 调用都会产生一条复杂的 Trace:Prompt、Completion、Token 统计、延迟、向量检索过程……这些数据量比传统应用日志高出几个数量级。
如果还在用传统关系型数据库硬扛,查询慢只是表象,存储成本和写入瓶颈迟早会教做人。
LLM 可观测性的“不可能三角”
LLM 应用的可观测性,本质上是在解决三个维度的矛盾:数据粒度、查询速度和存储成本。
你想把每次调用的 Prompt 和 Completion 都存下来做复盘,这是粒度;你想在账单异常时秒级定位到那条请求,这是速度;你想把几百 TB 的历史数据保留一年,这是成本。
在传统架构里,这三者几乎无法兼得。
PostgreSQL 这种行存数据库,写入事务强一致,适合存用户信息和账单,但让它去扫亿级 Trace 数据做聚合分析,就像让一个会计去搬砖——能搬,但效率极低。
Elasticsearch 倒是能搜,但资源消耗惊人,存一份 Trace 往往要付出 3 到 5 倍的存储冗余。
Loki 够便宜,但查询能力又太弱,稍微复杂一点的聚合就得写一堆正则。
这就是 Langfuse 在 2023 年到 2024 年间面临的现实困境。作为一个开源的 LLM Observability 平台,它最初完全基于 PostgreSQL 构建1。
随着用户数据量的暴涨,单表查询超时成了家常便饭,不得不限制用户保留数据的时长。这不是产品功能问题,是底层存储的天花板到了。
为什么 Langfuse 最终选择了 ClickHouse
PostgreSQL 的瓶颈:当 Trace 不再是“日志”
在 Langfuse 的早期架构里,所有的 Observations(Span、Generation、Event)都存在 PostgreSQL 的一张表里。
对于初创项目这没问题,但当单表行数突破 1 亿,索引膨胀、写入抖动、查询超时这些问题就像定时炸弹一样排队引爆。
Trace 数据和业务数据最大的不同在于:它写多读少,但读的时候往往是大范围扫描。
PostgreSQL 的 B+ 树索引是为了点查设计的,面对 `SELECT count() FROM observations WHERE project_id = ?
AND timestamp > now() - interval '7 day'` 这类查询,优化器往往选择全表扫描,直接把 IO 打满。

PG 慢查询告警又响了,心累
更致命的是存储成本。PostgreSQL 的行存模式对字符串压缩效率不高,而 LLM 的 Prompt 和 Completion 往往是大段文本。
同样的数据,在 PG 里可能要占 100GB,在列存数据库里可能只要 10GB。
ES vs Loki vs ClickHouse:一场不对等的较量
在选型时,Langfuse 团队对比了三种主流方案:
Elasticsearch (ES):查询能力强,但资源消耗巨大。为了维持高写入吞吐,需要复杂的分片策略。而且 ES 的存储成本极高,对于初创团队来说,维护一套高可用的 ES 集群是一笔不小的开销。ClickHouse 官方的对比测试显示,在日志分析场景下,ClickHouse 的查询速度比 ES 快 2 到 3 倍,存储成本只有 ES 的 1/102。
Loki:成本最低,因为它是基于对象存储的。但 Loki 的查询语言 LogQL 在处理复杂聚合时非常吃力,而且它不建立索引,查询时需要暴力扫描。对于 Langfuse 这种需要频繁做 Token 统计、评分分析的场景,Loki 的查询性能无法满足需求。
ClickHouse:在查询速度和存储成本之间找到了最佳平衡点。它的列式存储和向量化执行引擎,让它在聚合查询上具有压倒性优势。同时,它对数据压缩的支持极好,ZSTD 压缩算法能将文本列压缩到原大小的 10% 以下。
Langfuse 的架构演进:PG + ClickHouse 混合模式
最终,Langfuse 选择了混合架构:PostgreSQL 作为“元数据主库”,ClickHouse 作为“分析型副库”3。
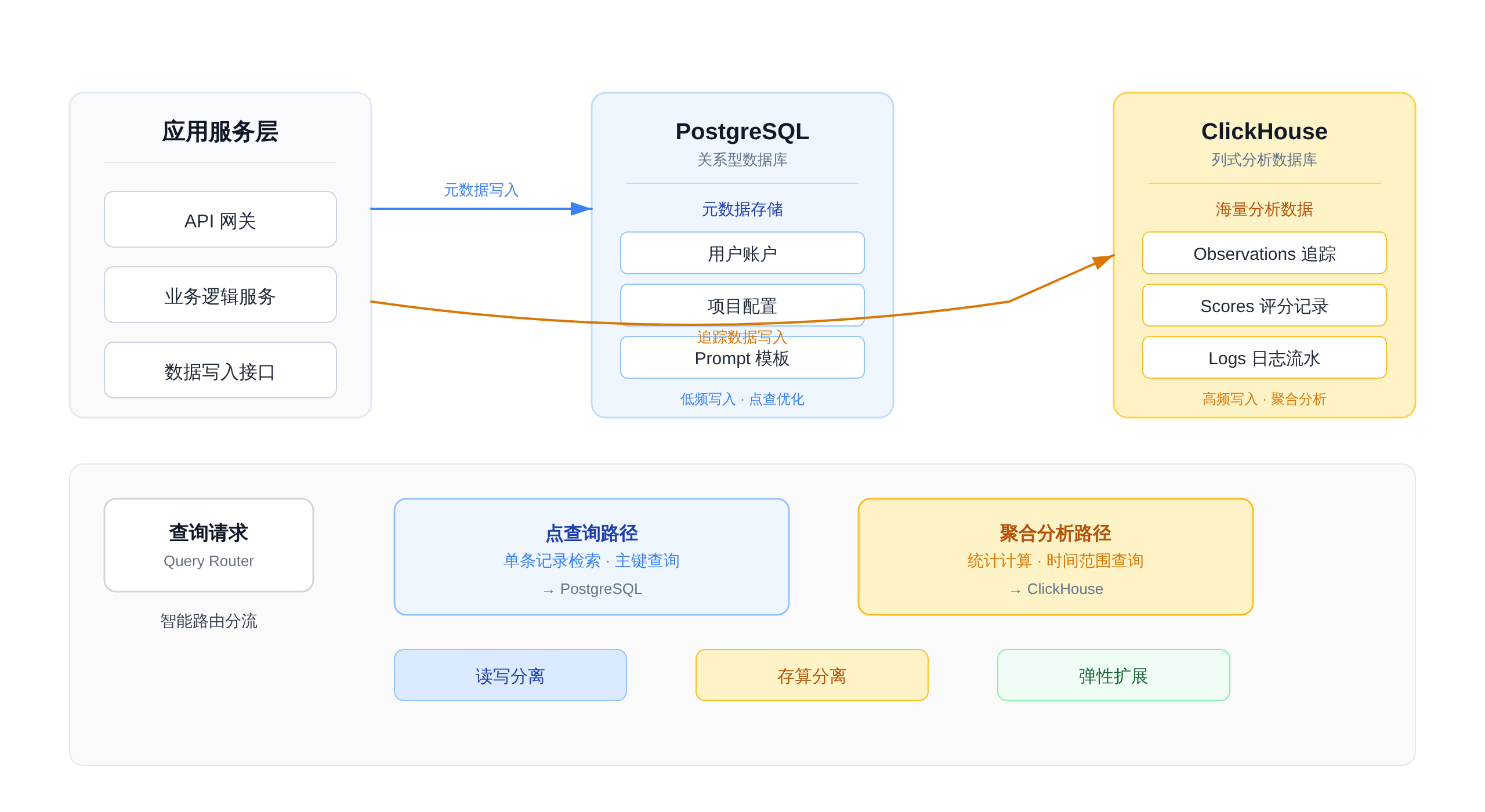
在这个架构里,PostgreSQL 只存“冷”数据:用户账号、项目配置、Prompt 模板版本。这些数据量小,但要求强一致性。
而所有的 Trace 数据、评分数据、Session 数据,全部写入 ClickHouse。
这种设计完美规避了各自的短板:PG 不再承担海量分析查询的压力,ClickHouse 也不需要处理复杂的事务逻辑。
对于开发者来说,这套架构既保留了 PG 的事务特性,又获得了 ClickHouse 的极致分析性能。
ClickHouse 核心原理:快在哪儿?
ClickHouse 的快,不是单点优化,而是从存储结构到计算模式的全面重构。
列式存储:I/O 与压缩的双重胜利
传统数据库按行存储,一条记录的所有字段在物理上连续存放。这对于 SELECT * FROM user WHERE id = 1 这种点查非常友好,一次 IO 就能读出整行。
但在分析场景下,我们往往只需要少数几列。
比如统计“过去 7 天每个模型的平均 Token 消耗”,你只需要 model、input_tokens、output_tokens、timestamp 这四列。
在行存数据库里,你必须把整行读出来再扔掉无用字段,这不仅是 IO 浪费,还会挤占内存带宽。
ClickHouse 按列存储,同一列的数据在物理上连续存放。查询时,只读取需要的列文件。
更关键的是,同一列的数据类型相同,内容往往高度相似(比如 model 列可能 90% 都是 gpt-4o),这使得压缩算法能发挥极致效果。
实测中,ClickHouse 的存储空间通常只有 PostgreSQL 的 1/5 到 1/10。
向量化执行:榨干 CPU 的每一滴性能
光减少 IO 还不够,CPU 的计算效率也是瓶颈。传统数据库是“火山模型”,逐行处理数据,每一行都要经过复杂的函数调用栈。这导致 CPU 大量时间浪费在函数跳转和分支预测上。
ClickHouse 采用了向量化执行引擎。它不是一行一行处理,而是一批一批处理(默认 8192 行)。
比如做加法运算,它利用 CPU 的 SIMD(Single Instruction, Multiple Data)指令,一条指令同时完成 8192 个数值的加法。
这就像把“搬砖”变成了“开卡车”,效率提升不是一点半点。
MergeTree 引擎:追加写的艺术
ClickHouse 最核心的表引擎是 MergeTree 家族。它的设计哲学是:数据一旦写入,就不再修改。
所有写入操作都是追加写。新数据先写入内存 Buffer,定期刷盘形成一个个 Part 文件。后台线程会异步将这些小 Part 合并成大 Part。
这种 LSM-Tree 变体结构,让写入性能极高,因为每次写入都是顺序写,没有随机 IO。
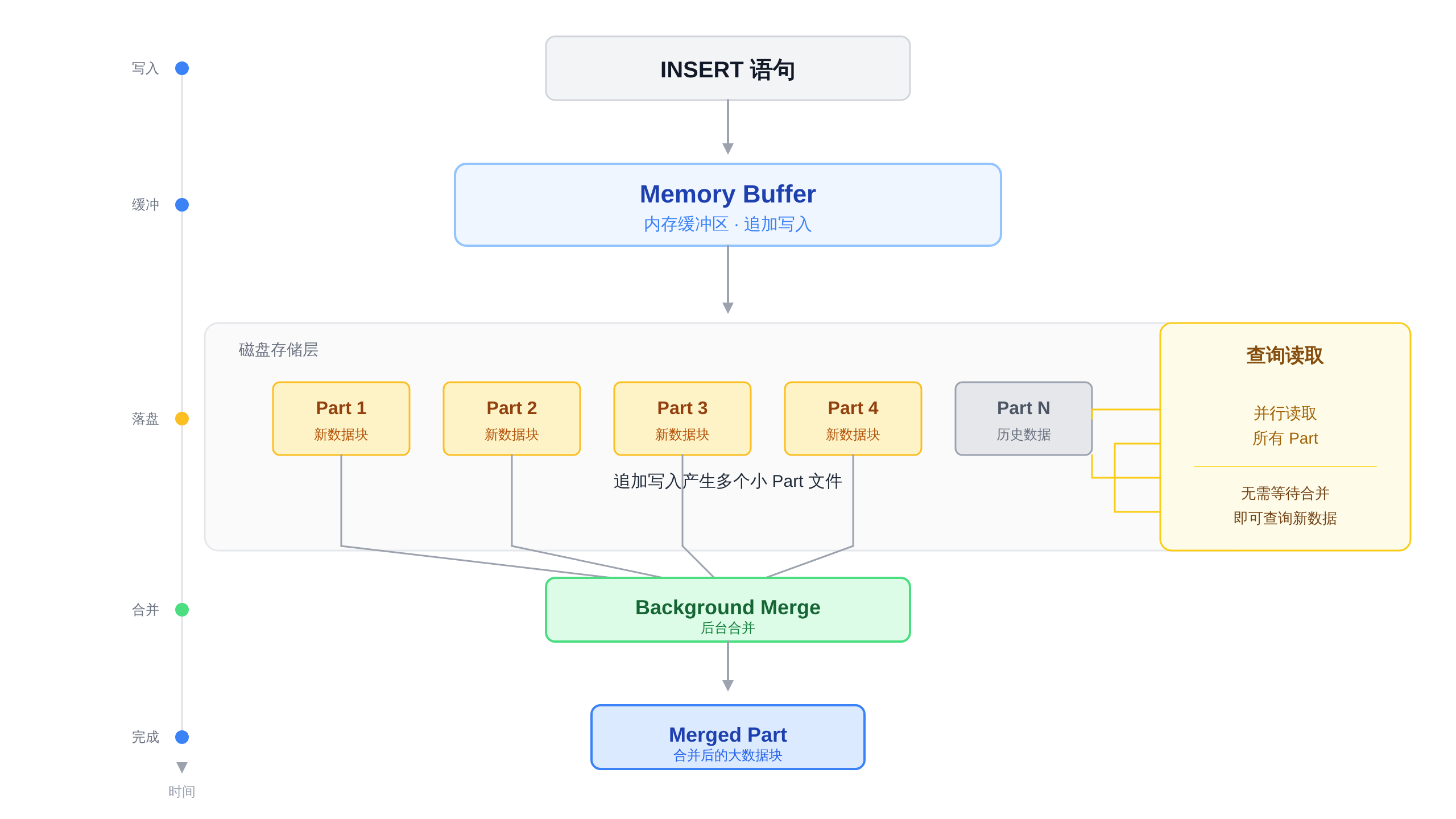
对于 Langfuse 这种写入量极大的场景,MergeTree 简直是绝配。而且,MergeTree 支持稀疏索引,每隔 8192 行才建一个索引标记。
这意味着索引体积极小,完全可以常驻内存,查询时能极快地定位到数据块。
Langfuse 的 ClickHouse 实战落地
表结构设计:排序键是性能的灵魂
在 ClickHouse 里,ORDER BY 不仅仅是排序,它决定了数据在磁盘上的物理布局。Langfuse 的 observations 表设计非常讲究:
CREATE TABLE observations (
id String,
project_id String,
trace_id String,
type String,
name String,
start_time DateTime64(9),
end_time Nullable(DateTime64(9)),
-- ... 其他字段省略
input_tokens Nullable(UInt64),
output_tokens Nullable(UInt64),
-- 省略 Prompt/Completion 等大文本字段
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(start_time)
ORDER BY (project_id, toDateTime(start_time), trace_id);
注意这个 ORDER BY (project_id, start_time, trace_id)。这是经过深思熟虑的:
project_id 在前:因为绝大多数查询都带有
WHERE project_id = ?。这样同一个项目的数据在物理上连续存放,查询时只需要读取该项目对应的数据块,极大地减少了 IO 范围。start_time 在中:时间范围查询是最高频的场景,比如“过去 7 天”。时间字段在排序键中,可以利用稀疏索引快速裁剪数据块。
trace_id 在后:用于保证同一 Trace 的数据局部性,方便关联查询。
如果排序键设计反了,比如把 trace_id 放在最前面,数据就会按 Trace ID 随机分布。查询某个项目的数据时,就需要扫描几乎所有数据块,性能会下降几个数量级。
写入优化:应对高并发 Trace 写入
LLM 应用的 Trace 写入往往是突发性的。比如一个 RAG 应用,一次请求可能产生几十条 Span。
如果每条 Span 都单独写入,ClickHouse 会迅速生成大量小 Part,触发 Too many parts 错误。
Langfuse 采用了两层优化策略:
应用层 Buffer:在服务端内存中维护一个 Buffer,积累到一定数量或时间后再批量写入。这能显著减少写入频率。
异步插入:ClickHouse 支持异步插入模式。客户端发送数据后立即返回,服务端在后台攒批写入。这虽然会带来秒级的数据可见延迟,但对于可观测性场景,这点延迟完全可以接受。
查询加速:从秒级到毫秒级
有了 ClickHouse,Langfuse 的 Dashboard 查询速度有了质的飞跃。以前在 PG 里需要跑 30 秒的 Token 消耗统计,现在可以在 200ms 内返回1。
这得益于 ClickHouse 的预聚合能力。Langfuse 利用 Materialized View,将明细数据实时聚合成小时级、天级的统计表。
Dashboard 查询时直接读聚合表,扫描的数据量减少了几个数量级。
-- 示例:按天聚合 Token 消耗的物化视图
CREATE MATERIALIZED VIEW daily_token_stats
ENGINE = SummingMergeTree()
ORDER BY (project_id, date)
AS SELECT
project_id,
toDate(start_time) as date,
sum(input_tokens) as total_input,
sum(output_tokens) as total_output,
count() as request_count
FROM observations
WHERE type = 'generation'
GROUP BY project_id, date;
这种“空间换时间”的策略,在分析型数据库里是标准操作。但在 PostgreSQL 里,物化视图的刷新成本极高,很难做到准实时。
而 ClickHouse 的增量物化视图,写入时自动维护,几乎零维护成本。
生产环境避坑指南
写入过快:Too many parts 的应对之道
这是 ClickHouse 最经典的报错。当你看到 DB::Exception: Too many parts,说明写入频率太高,后台合并线程跟不上了。
应对方案:
调大写入批次:不要一条一条插,攒够 1000 条或者 1MB 再写。
开启异步插入:
SET async_insert = 1, wait_for_async_insert = 0。让服务端帮你攒批。调整参数:
parts_to_throw_insert默认值是 300,可以适当调大,但这只是治标。根本还是要控制写入频率。
又是 Too many parts,我就知道攒批没攒够
查询 OOM:内存溢出的排查与优化
ClickHouse 是内存大户,复杂的聚合查询容易撑爆内存。
排查思路:
查看
system.query_log,找到memory_usage异常的查询。检查
GROUP BY的基数。如果 Group By 的字段唯一值太多(比如按 User ID Group By),中间结果会极大。
优化方案:
外部聚合:设置
max_bytes_before_external_group_by。当内存使用超过阈值,ClickHouse 会把中间结果溢写到磁盘。虽然慢一点,但不会 OOM。使用近似函数:比如
uniq()替代count(distinct),uniqCombined()误差率不到 1%,但内存占用只有原来的 1/10。
副本延迟:数据一致性的权衡
ClickHouse 的副本同步是异步的。刚写入的数据,可能要过几秒才能在另一个副本查到。对于 LLM Trace 这种场景,秒级延迟完全可以接受。但如果你的业务要求“写完立刻读”,就要注意了。
应对策略:
写入 Quorum:设置
insert_quorum = 2,确保至少两个副本写入成功才返回。这会牺牲写入性能,但能保证强一致性读。读自己的写:在 Session 级别设置
select_sequential_consistency = 1。但这会极大降低查询性能,慎用。
对于 Langfuse 这种监控平台,默认的最终一致性已经足够。毕竟,没人会在意监控数据有 5 秒钟的延迟。
写在最后
ClickHouse 不是银弹,它有自己的适用边界。如果你需要频繁的单行更新、删除,或者需要复杂的事务支持,PostgreSQL 依然是首选。
但在 LLM 可观测性这个赛道,Trace 数据的爆炸式增长,让 ClickHouse 几乎成了唯一的选择。
Langfuse 的架构演进,其实代表了 AI 时代数据栈的一个趋势:混合架构正在成为常态。用 PG 处理事务,用 ClickHouse 处理分析,用对象存储存冷数据。
每一层各司其职,而不是试图用一个数据库解决所有问题。
当你的 LLM 应用还在 Demo 阶段,PG 够用。但当你准备上线,面对真实的用户和流量,是时候考虑一下:你的存储架构,准备好迎接 Trace 数据的洪峰了吗?