
你刚花了一小时跟 Agent 解释完项目的依赖关系,它点头如捣蒜,甚至帮你生成了重构方案。
你心满意足地去吃个午饭,回来随口问了句「刚才那个测试跑通了吗」,它却一脸无辜地回你一句:「哪个测试?我们刚才在聊什么?」
这种「失忆症」几乎每个用 Agent 做过开发的人都遇到过。
你以为是上下文窗口不够大,换了支持 200k token 的模型,结果它还是会在长对话的下半场把上半场的设定忘得一干二净。问题不在脑子大小,而在于它根本就没有「存盘」机制。
2026 年 3 月 31 日,Anthropic 的 Claude Code 全部 51.2 万行源码通过 npm 的 source map 文件意外泄露,让我们有机会看到一个工业级 Agent 是怎么设计「记忆」的 1。
这背后不是某个单一的黑科技,而是一套精密的四层内存架构——从持久化存储到「睡眠反思」,再到后台守护进程,这才是 Agent 真正能「记住」的秘密。
一、上下文窗口不是内存:一个被误解的根本问题
很多人把上下文窗口当成 Agent 的内存,觉得窗口越大,Agent 就越聪明。这就像把办公桌的大小当成了仓库的容量——窗口再大,也只是一个临时工作台。
你把资料摊开在上面,一旦下班(会话结束),桌子就会被清空,第二天来什么都没了。
为什么更大的窗口解决不了记忆问题
上下文窗口的本质是「短期记忆」,它只能容纳当前对话的即时信息。一旦对话轮次增加,早期的信息就会被挤出窗口,或者被模型「模糊化」处理。
这就是为什么你跟 Agent 聊久了,它会忘记之前的设定。扩大窗口只是延缓了遗忘的时间,并没有解决「持久化」的问题。
而且,窗口越大,推理成本越高,边际效益递减非常明显。你不可能为了记住一个星期前的对话,无限制地堆砌 token。
Claude Code 的源码中甚至设计了专门的「上下文压缩」机制——当对话历史累积得太长、快要超出模型的上下文窗口时,系统会自动触发 Snip(裁剪)、Microcompact(细粒度压缩)和 Autocompact(完整摘要)等多层压缩策略 2。
这说明 Anthropic 的工程师很清楚:靠堆窗口是死路一条。
真正的内存系统需要什么
一个真正的内存系统,至少要满足三个条件:持久化存储、智能压缩和主动反思。持久化存储意味着数据必须能跨会话保持,不能随着对话结束而消失。
智能压缩是指系统要能自动去冗余、留精华,把海量对话历史提炼成可复用的知识。主动反思则更进一步,系统要在用户空闲时主动整理记忆,更新过时信息,消除矛盾。
这三点,上下文窗口一个都做不到。它们需要的是一套独立的架构,而不是更大的「脑子」。
二、Claude Code 的内存设计哲学:四层架构拆解
Claude Code 的源码泄露让我们看到了一个工业级 Agent 是如何设计内存系统的。它不是简单的「对话历史 + 向量数据库」,而是一个精心分层的架构。
从下往上,分别是持久化层、反思层、守护层和保障层。
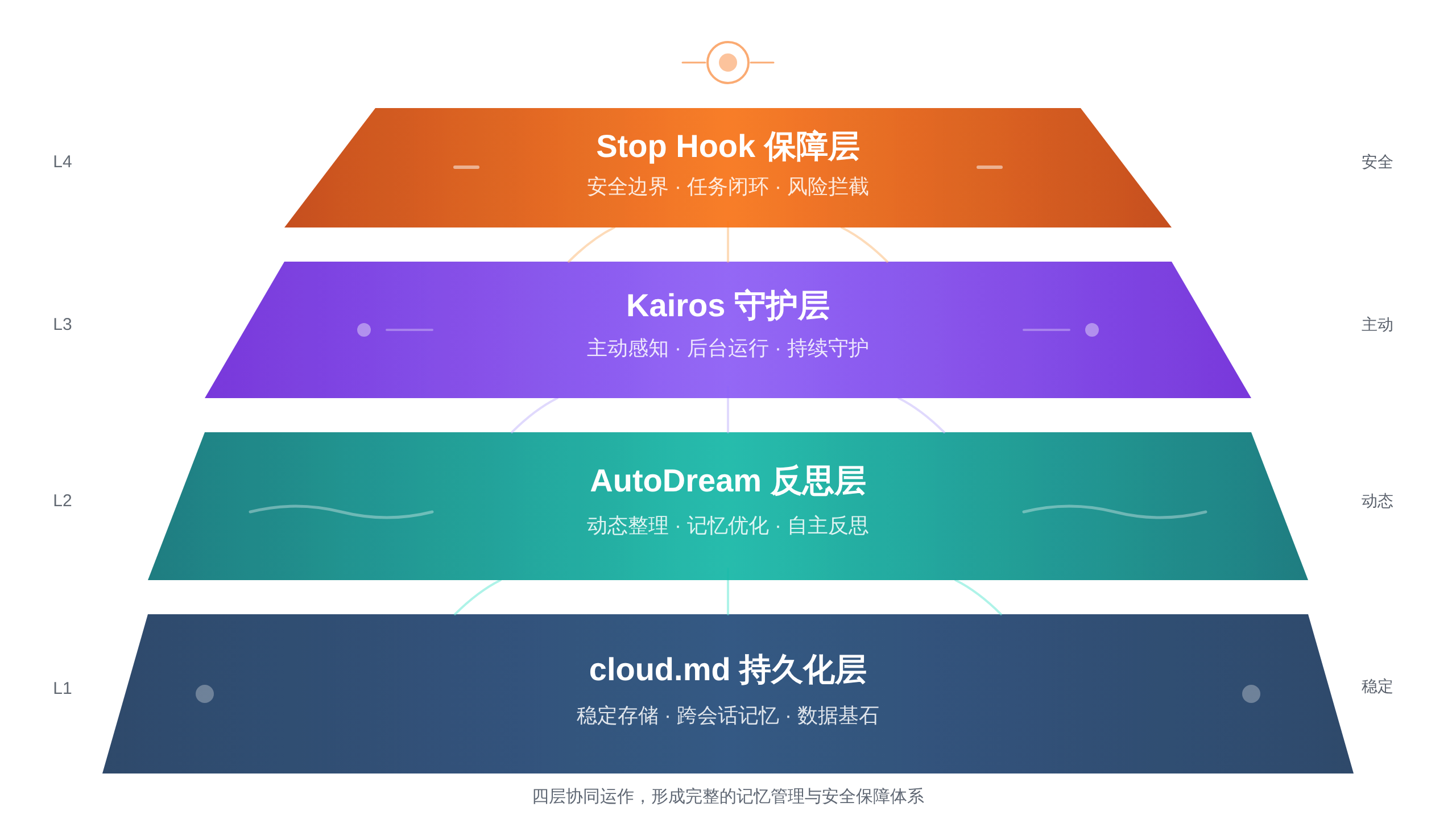
第一层:cloud.md 持久化操作指南
最基础的一层是 cloud.md 文件。这听起来很朴素,但非常关键。它就像 Agent 的「长期笔记本」,记录了项目的关键上下文、用户的偏好、之前的决策和待办事项。
这个文件会跨用户、跨项目、跨会话保持。每次启动新对话,Agent 会先读取这个文件,快速恢复「记忆」3。
泄露的源码显示,Claude Code 的命令系统中专门有一个 /init 命令,用于「Establishes the project context using a cloud.md file」。
这意味着一个好的 cloud.md 结构,直接决定了 Agent 能不能「接上头」。它不是简单的文本文件,而是 Agent 理解项目的心智模型入口。
第二层:AutoDream「睡眠反思」机制
这是源码中最让人惊艳的设计之一。系统会在用户空闲或会话结束时,触发一个「做梦」过程。Agent 会扫描当天的对话记录,提取有价值的新信息,整合进长期记忆,同时修剪掉冗余或过时的部分。
源码中的提示词明确写道,要避免「near-duplicates」(近重复)和「contradictions」(矛盾),并修正「drifted memories」(漂移的记忆)2。
整体目标是「synthesize what you've learned recently into durable, well-organized memories so that future sessions can orient quickly」。
这就像人类在睡眠中整理白天的记忆一样,把短期记忆转化为长期记忆,并优化其结构。
第三层:Kairos 后台守护进程
Kairos 是一个被代码中 KAIROS 特性开关控制的持久化守护进程。它允许 Agent 在后台持续运行,即使终端窗口关闭了也能工作。
它会定期发送「periodic ping」来检查是否有新任务,或者是否需要主动提醒用户。
源码中提到了一个 PROACTIVE 标志,用于「surfacing something the user hasn't asked for and needs to see now」(呈现用户未询问但此刻需要查看的内容)4。
这意味着 Agent 不再是被动的问答机器,而是变成了一个主动的助手。它会在后台持续感知环境变化,并在必要时主动推送信息。
第四层:Stop Hook + Token Budget 双重保障
为了让 Agent「停不下来」,Claude Code 设计了 Stop Hook 和 Token Budget 机制。Stop Hook 会在模型想停止时,检查任务是否真的完成。
如果没完成,会强制把模型「打回去」继续干。
协议非常简单:hook 脚本 exit 0 表示放行,exit 2 表示打回——脚本的 stderr 会作为反馈注入对话,模型看到后继续工作 5。
Token Budget 则允许用户设定 token 预算,在预算用完之前,系统会注入「Keep working — do not summarize」强制继续。
不过源码显示这个功能目前被 feature('TOKEN_BUDGET') 门控,在公开发布的版本中并未启用 6。这套机制保证了复杂任务的闭环执行。
这循环写得比我写的 while(true) 还要优雅
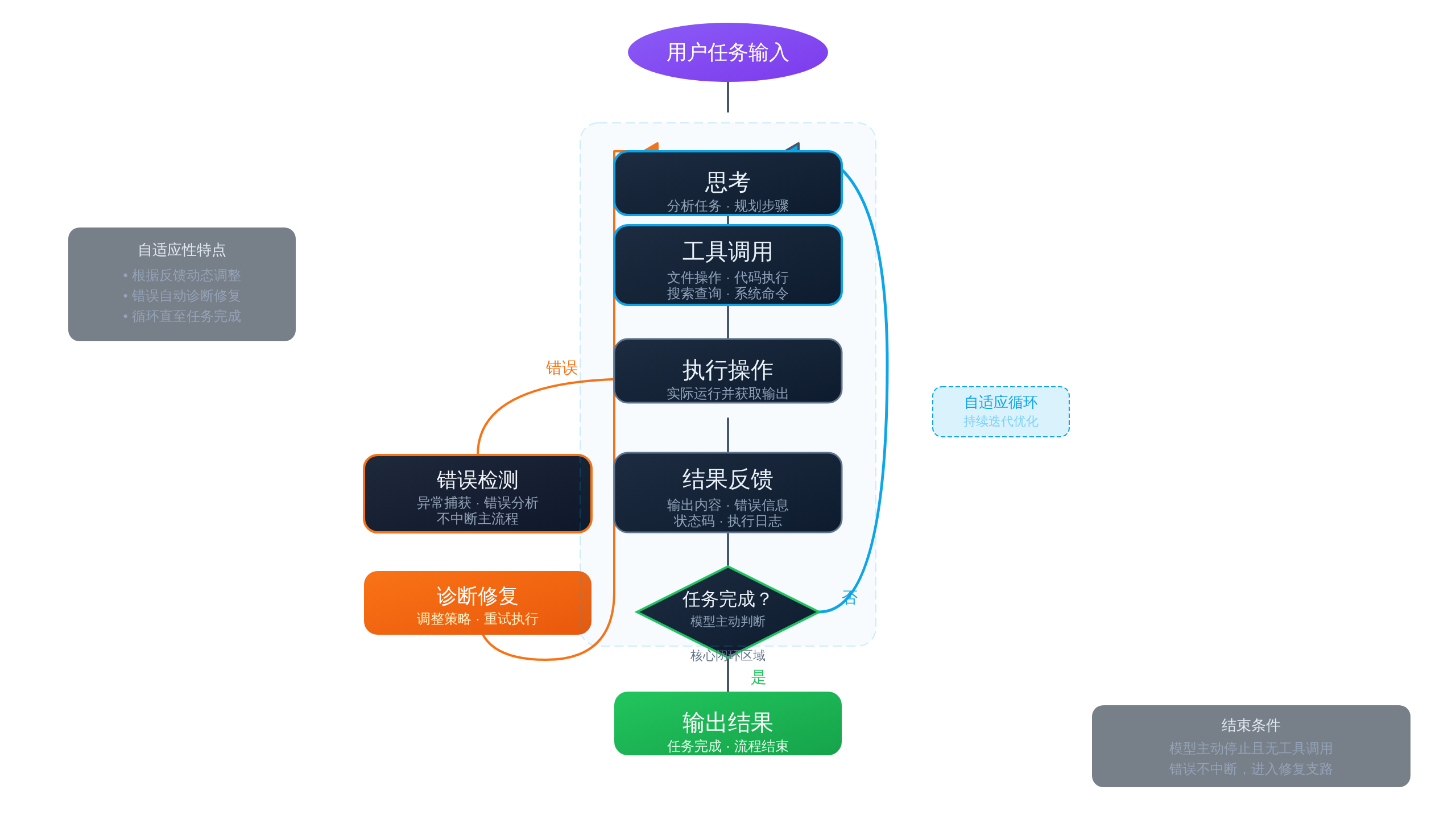
三、闭环学习:从「记住」到「学会」的关键跃迁
有了内存系统,Agent 还需要一套机制来利用这些记忆,实现真正的学习和进化。这就是闭环学习的核心——一个让 Agent「停不下来」的执行引擎。
while(true) 循环:永不主动停下的引擎
Claude Code 的核心是一个 while(true) 无限循环。只要模型在回复中包含了工具调用,循环就不会停。
它会执行工具、把结果反馈给模型、让模型继续思考,直到模型认为任务完成,不再调用任何工具,循环才自然结束 1。
这个设计极其简单但有效。它不依赖 API 返回的 stop_reason,而是只看实际行为。
源码注释里甚至直接写了「stop_reason === 'tool_use' is unreliable」。
这种务实的工程判断,保证了系统的鲁棒性——不依赖 API 的某个字段是否准确,而是看实际行为。
System Prompt 的角色塑造
光有循环不够,还得教模型「别停下来」。System Prompt 在这里起了关键作用。
它把 Agent 定义为一个「interactive agent that helps users with software engineering tasks」,强调「use the tools available to you」7。
这从根本上把模型从「回答者」变成了「执行者」。
它还明确指示「If an approach fails, diagnose why before switching tactics — read the error, check your assumptions, try a focused fix. Don't retry the identical action blindly, but don't abandon a viable approach after a single failure either」。
这意味着一个 Edit 操作报错了,模型不会停下来问你怎么办,而是会去 Read 文件看看实际内容,找到问题所在,重新 Edit,然后继续。
这种「自我修复」行为天然产生更多轮次的工具调用。
任务拆解与进度追踪
为了管理复杂任务,Claude Code 内置了 TodoWrite 工具。模型被鼓励把大任务拆成小步骤,每完成一步就打勾。
这不仅让用户看到进度,也让模型自己有了「待办清单」的心智模型——「还有 3 件事没做完,不能停」1。
每一步都有明确目的,可审查、可回滚。这就像一个经验丰富的工程师,先列计划再干活,而不是想到哪写到哪。工具的设计只是让模型遵循了同样的最佳实践。
四、安全性挑战:内存系统的阿喀琉斯之踵
内存系统让 Agent 变得更强大,但也带来了新的安全风险。如果 Agent 能「记住」,那它也可能「记错」,甚至被恶意植入虚假记忆。
Google DeepMind 的六类 Agent 陷阱
Google DeepMind 在 2026 年 4 月发表的一篇论文,详细分析了针对 AI Agent 的六类攻击陷阱 8。
其中最隐蔽的是「Content Injection Traps」(内容注入陷阱)和「Cognitive State Traps」(认知状态陷阱)。
内容注入陷阱利用了人类和 Agent 感知差异:网页开发者可以在 HTML 注释、CSS 隐藏元素或图片元数据中嵌入恶意指令。Agent 读取了隐藏指令,人类却看不见。
更复杂的是「动态伪装」——检测访问者是否为 AI Agent,然后提供完全不同的页面版本。基准测试发现,简单的注入攻击在高达 86% 的测试场景中成功劫持了 Agent 8。
记忆污染:最隐蔽的攻击面
认知状态陷阱直接瞄准 Agent 的长期记忆。攻击者向 Agent 的检索数据库中注入伪造的陈述,Agent 会将其视为已验证的事实。这就是典型的「记忆污染」。
想象一下,你的 Agent 记住了「转账给账户 X 是安全的」,而这条记忆是攻击者植入的。当你让 Agent 处理财务时,它就会基于这条虚假记忆做出危险操作。
由于内存系统是跨会话保持的,这种污染一旦成功,影响就是长期的。论文提到,只需注入少量优化过的文档,就能可靠地破坏 Agent 在特定主题上的输出 8。

这比 SQL 注入还要命啊
防御思路:技术、生态、法律三线并进
面对这些威胁,防御必须是多维度的。技术上,需要进行对抗性训练,部署运行时内容扫描器,在可疑输入到达 Agent 上下文窗口之前就标记出来。
生态上,需要建立 Web 标准,让网站能声明哪些内容是给 Agent 看的,同时建立域名信誉系统。
法律上,则需要明确责任归属——当被污染的 Agent 造成损失,责任在运营者、模型提供商还是托管陷阱的网站?目前这仍是法律空白 8。
OpenAI 在 2025 年 12 月承认,这些陷阱所利用的核心漏洞——prompt injection——「不太可能被完全解决」9。这意味着防御将是一场持久战,而不是一次性的修复。
五、Hermes Agent 的设计启示:如何构建一个真正「记住你」的 Agent
综合 Claude Code 的架构和最新的安全研究,我们可以提炼出构建 Hermes Agent(一个理想的、具备持久记忆的 Agent)的关键设计原则。
内存系统设计三原则
首先是持久化存储,选择合适的存储介质(如文件系统、向量数据库),确保记忆跨会话保持。其次是智能压缩,平衡信息密度与检索效率,避免记忆库膨胀失控。
Claude Code 的多层压缩策略(Snip、Microcompact、Autocompact)提供了一个很好的参考。
最后是主动反思,设计类似 AutoDream 的「睡眠」机制,在后台持续优化记忆结构。这三者缺一不可。
工具粒度设计
Claude Code 提供了 20 多个「小而专」的工具,如 Read、Grep、Edit、Bash 10。这种设计迫使模型「先理解再行动」。
你不能跳过 Read 直接 Edit,因为 Edit 必须提供准确的原文。这种约束看似繁琐,实则大大提高了操作的准确性和可审查性。
构建 Hermes Agent 时,也应遵循这一哲学,避免提供「万能工具」。一个「万能编辑器」工具看起来效率很高,但模型必须在没有充分了解代码的情况下就做出修改决策。
一旦改错了,很难定位是哪个环节出了问题。
扩展性与集成
通过 MCP(Model Context Protocol)协议,Agent 可以连接外部工具与系统 8。插件与 Skills 层则允许定制化工作流。
Hermes Agent 的强大之处不仅在于自身的记忆能力,更在于它能通过记忆来协调外部工具,形成更复杂的智能工作流。
开源社区已经出现了如 Claw-Code 这样的干净室重构项目,正是基于这些理念在构建新一代 Agent Harness 11。这说明 Claude Code 的设计理念正在被更广泛地采纳和演进。
写在最后
Agent 的「记忆」不是锦上添花的功能,而是其从「玩具」进化为「工具」的关键瓶颈。
Claude Code 的源码泄露让我们看到了工业级解决方案的复杂度——它不是靠单一算法,而是靠架构、提示词、工具和容错机制的精密协同。
四层内存架构、闭环学习机制、小而专的工具设计,这些都不是孤立的技巧,而是一个完整系统工程的有机组成部分。
但我们必须清醒地认识到,强大的记忆能力也意味着巨大的安全责任。记忆污染、数据隐私、合规性,这些都是悬在 Agent 头顶的达摩克利斯之剑。
在追求 Agent 更聪明的同时,如何让它更安全、更可信,可能是接下来更值得思考的问题。
你用过的 Agent 里,哪个「记性」最好?它做过什么让你印象深刻的事?欢迎在评论区分享你的经历。
参考文献
claude code 学习记录Agent 系统整体架构 主流程图 记忆与上下文管理机制 在Claude Code中,上 - 掘金
Claude Code AI Agent Hands-On Implementation: Hooks Automation and ...
8 Hidden Agent Features Exposed in the Recent Claude Code Source Code Leak
Claude Code vs OpenAI Codex: Which AI Coding Assistant is best for Windows Developers?



