你花了两周把 LangGraph 的 StateGraph 用熟了,节点、边、条件路由、checkpointer 全跑通,demo 跑出来效果不错,简历上终于能写「熟悉 LangGraph」。
然后面试官问了一句:「你们的 Agent 是怎么保证输出质量的?Harness 层怎么设计?」
你愣了一下。
你以为 LangGraph 就是终点,其实它只是开始。
Harness Engineering 是当前 AI 工程圈最被低估的能力层——不是框架,是让 Agent 系统「从能跑变成能信」的工程基础设施。
这篇把两者的集成点和扩展边界讲透,目标是让你面试时能画出来、说得清、不被追问打穿。

面试官还没追问,手心已经开始出汗了
一、为什么说 Harness Engineering 是当前 AI 工程圈最被低估的能力层
2025 年到 2026 年,OpenAI 和 Anthropic 的工程师团队几乎在同一时间发现了一个规律:模型能力已经不是瓶颈,Harness 才是。
OpenAI 的内部 field report 记录了一个具体数字——加入结构化 Harness 之后,同样的模型在复杂任务上的成功率从 52.8% 提升到了 66.5% Anthropic Agentic Engineering Patterns。
这不是模型换出来的,而是工程基础设施搭出来的。
Harness 的本质是什么?它是包裹在模型外围的一层工程逻辑,负责治理模型的输入、输出、状态和反馈闭环。
没有 Harness 的 Agent 系统像一个没有质量门的工厂流水线——机器能转,产品能出来,但次品率你控制不了。
Anthropic Labs 的工程负责人 Prithvi Rajasekaran 在介绍三 Agent 架构时说过一句很直接的话:separating the agent doing the work from the agent judging it is a strong lever for improving output quality。
这句话翻译过来就是——让干活的人和打分的人分开,是提升输出质量最有效的杠杆 Anthropic Three-Agent Harness Design。
这句话值得在面试里重复,因为它的反面恰恰是大多数人在项目里会犯的错误:自己写的代码自己 review,自己做的方案自己打分,模型的自我评价偏见直接带进了生产环境。
现在问题来了:Harness Engineering 和 LangGraph 是什么关系?
很多人以为它们是竞争关系——选了 LangGraph 就不用 Harness,或者 Harness 是一种替代方案。这理解完全反了。
LangGraph 是一个流程编排层,它的核心价值是让你用图结构组织节点、状态和路由。
Harness Engineering 是一个质量治理层,它的核心价值是让你的 Agent 系统在长时间运行和多人协作时保持可预测性。
两者的关系不是谁替代谁,而是 Harness 包裹在 LangGraph 外层——Harness 管「做什么、做得对不对」,LangGraph 管「怎么跑、状态怎么流转」。

项目里没有 Harness,线上出问题就只剩下祈祷
举一个真实场景:你在用 LangGraph 搭一个代码审查 Agent,流程是「读取 diff → 分析 → 输出建议 → 写入评论」。
LangGraph 负责让这个图跑起来——节点之间怎么路由、状态怎么传递、多轮对话怎么保持。但如果这个 Agent 在生产环境里跑,你还有几个实际问题没解决:
第一,Agent 在动手之前有没有一个确认过的执行计划?还是想到哪改到哪?第二,如果 Agent 改了错误文件的代码,谁来catch?
这个验证机制在哪?第三,当 Agent 在凌晨两点跑了一个小时的修改,第二天工程师来审计发现改乱了,谁来负责?
这些问题不是 LangGraph 能回答的,它们属于 Harness 的范畴。LangGraph 定义了「怎么跑」,Harness 定义了「跑什么、对不对、出了问题谁管」。
理解这一层之后,面试里你就不会再把两者混为一谈了。
面试官问你「LangGraph 和其他 Agent 框架的区别」,你能说出 StateGraph 的循环能力、持久化支持和并发流式,这些都是具体的技术判断;
面试官再追问「你们怎么保证 Agent 输出质量」,你能直接画出 Harness 层包裹 LangGraph 层的架构图,并解释 Plan/Verify/Context 三个职责怎么和 LangGraph 的节点执行配合——这个回答已经超出了背 API 的层面,进入了工程设计的维度。
二、LangGraph 的核心能力边界:状态、循环与人机交互
在进入 Harness 集成之前,必须先把 LangGraph 本身的边界搞清楚。LangGraph 的核心能力是四件事:循环、状态持久性、人机交互、并发流式。
这四件事让它区别于普通的 DAG 执行器,是面试里能用工程语言讲清楚的关键。
2.1 StateGraph 三要素:节点、边、状态
LangGraph 的核心抽象是 StateGraph,它由三个基本要素组成:
节点(Node):节点是图中执行逻辑的基本单元,每个节点是一个函数,接收当前状态,返回状态更新。
你可以把节点理解为工作流里的一个步骤——比如「调用搜索工具」「生成回复」「写代码文件」。节点的输入输出都是同一个状态对象,这就让状态在整个图中流转时保持连贯。
边(Edge):边定义了节点之间的连接关系。边分两种:普通边(无条件跳转)和条件边(有条件路由)。
条件边是 LangGraph 区别于普通状态机的关键——你可以根据当前状态的内容决定下一步走哪个节点,比如检查 LLM 的 tool_calls 是否为空,如果为空就结束,如果不为空就继续调用工具。
状态(State):状态是贯穿整个图执行上下文的数据结构。
在 MessagesState 这种内置状态类型里,状态就是一个消息列表,每个节点执行后返回的消息会被追加到这个列表里。
你也可以自定义状态类型,只要在 TypedDict 里声明字段就行。状态在节点之间传递,每个节点都可以读取和修改状态,这使得图执行过程中产生的数据都累积在同一个对象里。
这三个要素的组合产生了 LangGraph 最重要的能力:循环。普通 DAG 是无环图,节点只能执行一次。
LangGraph 因为有条件边和状态累积,可以实现节点之间的循环——最典型的场景是 Agent 执行 → 检查是否需要工具调用 → 是则调用工具 → 工具结果回到 Agent → Agent 再次决定 → 直到不需要工具调用才退出循环。
这个循环结构对应了 ReAct 范式的工程实现,也是面试里问到 LangGraph 和 LangChain 的核心区别时最有说服力的答案。

循环这东西,画图谁都懂,线上卡住了才知道痛
2.2 checkpointer 与 thread_id:多轮对话状态的工程实现
LangGraph 的状态持久性靠 checkpointer 实现。
checkpointer 的作用是在图的每次执行之后自动保存状态,这样你可以在任意时间点暂停图的执行,然后在恢复时从断点继续,而不是从头重启整个流程。
这在工程上解决了一个非常具体的问题:长时间运行的 Agent 任务,比如一个持续四小时的代码生成会话,中途如果进程崩溃了,没有 checkpointer 的情况下你只能从头来过,有了 checkpointer,你可以用同一个 thread_id 恢复到崩溃前的状态继续执行。
MemorySaver 是最轻量的 checkpointer 实现,适合本地开发和测试环境。
在生产环境里,Anthropic 的 Claude Managed Agents 之类的平台会提供更robust的持久化层,支持跨进程的状态恢复和并发多线程的状态隔离 Claude Managed Agents Launch。
thread_id 是 checkpointer 的使用方式里的核心概念。每个 thread_id 对应一个独立的对话线程,拥有自己的状态历史。
当用户用同一个 thread_id 再次发起请求时,LangGraph 会从保存的状态继续,而不是创建一个新会话。这个机制使得「旧金山天气怎么样?」和「那纽约呢?
」这两句连续对话能在同一个状态里处理——第一句的状态被保存,第二句进来时消息列表里已经有第一句的上下文,模型能看到完整的对话历史。
# 同一个 thread_id,第一次调用
config = {"configurable": {"thread_id": 42}}
app.invoke({"messages": [HumanMessage(content="旧金山的天气怎么样?")]}, config=config)
# 同一个 thread_id,第二次调用,状态自动延续
app.invoke({"messages": [HumanMessage(content="那纽约呢?")]}, config=config)
这个 API 看起来简单,但它是 LangGraph 在生产环境里最常用的能力之一。
面试时被问到「LangGraph 怎么实现多轮对话」,很多人会讲 MessageHistory,讲对话窗口大小,但真正理解的人会从 checkpointer + thread_id 的机制出发,讲清楚状态是怎么在同一条线程里累积的,以及这和直接操作消息列表有什么区别。
面试官问的不是API签名,是状态恢复的一瞬间发生了什么
三、deep-agent Harness Engineering 的六种工程模式
Harness Engineering 的核心不是某一种具体实现,而是一套应对真实失败场景的工程模式。
Verdent 的 Agentic Engineering Patterns 把这些失败场景分成了三类:方向失败(Direction failure)、上下文失败(Context failure)和输出质量失败(Output quality failure)。
六种 Pattern 分别对应这三类失败的治理方案 Agentic Engineering Patterns。
理解这个分类体系是面试里回答「你们怎么保证 Agent 质量」的基础。方向失败说的是 Agent 做了错误的事——计划模糊、边界不清,Agent 以为在做 A 其实在做 B。
上下文失败说的是 Agent 产生了幻觉——因为没有真实读取代码库,编造了不存在的文件路径或 API 调用。
输出质量失败说的是代码能跑但有 bug——没有结构化的验证机制,Agent 宣布完成但实际上存在回归。
下面逐个拆解六个 Pattern,每个 Pattern 讲清楚:它解决什么问题、和 LangGraph 怎么配合、面试官可能追问什么。
3.1 Pattern 1:计划优先开发(Plan-First Development)——解决方向失败
问题场景:Agent 开始执行之前没有和工程师对齐「做什么」的共识。Agent 自己理解了一个模糊的需求就开始改代码,改到一半发现不对,返工,浪费大量 token 和时间。
核心机制:在 Agent 开始任何代码变更之前,先输出一个结构化计划,等待工程师的 [APPROVED] token 之后再开始执行。
这个计划不是自由文本,而是一个标准格式的文档,必须包含:待修改的文件列表、修改模式(参考哪个已有实现)、验证步骤(通过什么命令确认完成)、假设条件(用了哪些技术栈假设)、不在范围内的变更(明确划清边界)。
计划格式示例:
PLAN: 将 auth 模块从 session 迁移到 JWT
待修改文件:
- src/auth/session.py → 替换 SessionManager 为 JWTManager
- src/auth/middleware.py → 更新 authenticate() 验证 JWT
- src/auth/models.py → 添加 jwt_secret 字段,从环境变量读取
参考模式:src/api_keys/jwt_util.py(PyJWT 2.x,HS256)——请严格按照此实现
验证步骤:
1. pytest tests/auth/ -v 退出 0
2. grep -r "from auth.session import" ./src 返回为空
假设条件:
[ASSUMPTION] 使用 PyJWT,仓库中无其他 JWT 库
[ASSUMPTION] JWT_SECRET 环境变量已在 .env.example 中定义
不在范围内:Refresh token 轮换、前端变更
这个格式的精髓是「标注」——每个假设条件和边界都用 [ASSUMPTION] 和不在范围内的声明标出来。标注的作用是让审查者能在 60 秒内扫完计划,找到关键决策点,而不是读完全文再自己总结。
和 LangGraph 的配合:在 LangGraph 里,计划审批可以作为一个前置节点(Plan Gate Node)。
图从 START 跳入 Plan 节点,Plan 节点输出结构化计划,工程师审批后通过条件边决定是继续执行还是打回重新规划。
LangGraph 的条件路由天然支持这种「审批 + 跳转」模式,不需要额外的外部状态管理。
# LangGraph 中的计划审批节点
def should_continue(state: TaskState) -> Literal["execute", "plan"]:
if state.get("approval_token") == "[APPROVED]":
return "execute"
return "plan"
workflow.add_conditional_edges(
"plan_node",
should_continue,
{"execute": "execute_node", "plan": "plan_node"}
)
面试追问方向:
如果需求非常小,比如只是改一行代码,还要走计划审批吗?
如果 Agent 输出了一个计划但假设条件里有明显错误,你怎么 catch?
计划审批在团队协作场景里怎么做到异步?Agent 等待的时候在干什么?
对于第一个问题,答案是明确的——单文件 bug 修复、探索性会话、30 行以内的变更不需要计划 Gate,这是 Harness 的成本收益判断,不是铁律。
对于第二个问题,计划本身的假设条件可以被 LLM 自己 review,也可以通过对比已有的 impact map 判断是否越界。
对于第三个问题,LangGraph 的 interrupt() API 可以让节点暂停等待外部信号,不需要 Agent 占用内存空转。
3.2 Pattern 2:并行工作树隔离(Parallel Worktree Isolation)——解决冲突写入
问题场景:两个 Agent 同时在同一个仓库里工作,改了同一个文件的不同部分。
因为没有隔离,它们的工作目录互相覆盖,最终产生不可预测的合并状态,或者更常见的——其中一个 Agent 的修改直接被另一个覆盖,没有任何报错。
核心机制:用 Git Worktree 为每个并行 Agent 创建独立的文件系统视图。
Agent 在各自的 detached branch 上工作,主分支(main workspace)保持干净,直到 Agent 完成工作后显式合并。
# 为每个并行 Agent 创建隔离的工作树
git worktree add .worktrees/agent-auth-jwt -b agent/auth-jwt-migration
git worktree add .worktrees/agent-test-gen -b agent/test-generation
# Agent 1 在自己的目录里工作
cd .worktrees/agent-auth-jwt
# Agent 2 在自己的目录里工作
cd .worktrees/agent-test-gen
# 两个 Agent 都完成后,从 main 分支合并
git merge agent/auth-jwt-migration --no-ff -m "integrate: JWT migration"
git merge agent/test-generation --no-ff -m "integrate: test generation"
# 清理
git worktree remove .worktrees/agent-auth-jwt
git worktree remove .worktrees/agent-test-gen
git branch -d agent/auth-jwt-migration agent/test-generation
这个方案看起来像是 DevOps 范畴,但它的核心价值是在多 Agent 场景下消除「写入冲突」这个最常见的并行失败模式。
两个 Agent 互相看不到对方的文件系统,因此不可能产生覆盖;
合并时由工程师(或者更进一步的 merge agent)负责解决冲突,而不是让两个自主 Agent 在同一个沙盒里互相 overwite。
和 LangGraph 的配合:在 LangGraph 的多 Agent 架构里,worktree 隔离对应的是「执行器 Agent」和「审查者 Agent」的资源隔离。
如果你在 LangGraph 里实现 Role-Separated Agents 架构(下面会讲),Executor 和 Reviewer 应该在不同的 worktree 里运行,否则 Reviewer 读取的代码版本可能已经被 Executor 修改了但还没落盘。
面试追问方向:
如果两个 Agent 的修改在合并时产生冲突,谁来解决?
工作树隔离能支持多少个并行 Agent?
如果 Agent A 依赖 Agent B 的输出(比如 A 需要 B 先生成的 schema),还能用工作树隔离吗?
第三个问题是关键——工作树隔离只适用于「独立任务」,如果任务之间有依赖关系,需要用 DAG 顺序调度而不是并行隔离。面试里能主动指出这个边界条件,是加分项。

并行一时爽,合并火葬场
3.3 Pattern 3:角色分离 Agent(Role-Separated Agents)——解决自我评审偏差
问题场景:同一个 Agent 写了代码又自己 review,模型对自己的输出有系统性的高估,review 变成走过场,bug 被漏放。
Anthropic 的 Rajasekaran 直接指出了这个问题的本质:separating the agent doing the work from the agent judging it proves to be a strong lever to address this issue Anthropic Three-Agent Harness Design。
核心机制:将原来一个 Agent 承担的「计划-执行-评审」职责拆成三个独立角色:
| 角色 | 职责 | 模型选择 |
|---|---|---|
| Planner | 拆解任务,识别文件,指定验收标准 | 强模型(Claude Opus 4.7 / GPT-5.4 xhigh) |
| Executor | 实施计划,写代码,跑命令 | 中等模型(成本敏感) |
| Reviewer/Verifier | 检查 diff 是否符合原始 spec,运行验收标准 | 独立模型(与 Executor 不同) |
用 LangGraph 实现这个架构:
from langgraph.graph import StateGraph, END, START
def build_review_pipeline():
graph = StateGraph(TaskState)
# 三个独立节点
graph.add_node("plan", run_planner) # 强模型,只读
graph.add_node("execute", run_executor) # 实施,写代码
graph.add_node("review", run_reviewer) # 独立上下文,不同模型
# 流程边
graph.add_edge(START, "plan")
graph.add_edge("plan", "execute") # 计划审批 Gate 在这里
graph.add_edge("execute", "review")
# 审查路由:pass → 结束,revise → 回 Executor,reject → 回 Planner
graph.add_conditional_edges(
"review",
route_on_review_result,
{
"pass": END,
"revise": "execute", # 带 reviewer 反馈回滚
"reject": "plan" # 计划本身错误,打回重新规划
}
)
return graph.compile()
关键设计:Reviewer 运行在一个「新鲜的上下文」里——它没有被 Executor 的思维过程污染,直接用评估标准检查输出物。
如果用同一个模型做 Executor 和 Reviewer,需要确保 Reviewer 的 prompt 里完全不包含 Executor 的思考过程,否则模型的自我保护机制会让它倾向于放过自己的代码。
和 LangGraph 的配合:LangGraph 的 add_conditional_edges 是实现这个三角路由的核心 API。
条件边的返回值决定下一步跳入哪个节点,这使得「review 通过就结束、review 打回就回滚」变成一个声明式的图结构,而不是 if-else 分支逻辑。
面试追问方向:
角色分离的 cost 比单一 Agent 高多少?什么时候值得这样做?
如果 Reviewer 打回了一个改动,Executor 需要重新理解前一次的结果吗?
三角色架构在 LangGraph 里怎么初始化状态?Planner 的输出格式谁来约束?
第二个问题涉及 Reviewer feedback 的注入方式。
最简单的方案是把 Reviewer 的输出追加到 Executor 的消息列表里,Executor 下一次调用时直接看到「上一次哪里不对」。
这个方案不需要改变 Executor 的模型,只需要改变消息内容。

Reviewer 打回的锅,到底算 Executor 的还是 Planner 的
3.4 Pattern 4:验证循环(Verification Loops)——解决「完成即宣布」的幻觉
问题场景:Agent 宣布「任务完成」,但实际上测试没跑通、有回归 bug、代码根本没有被测试覆盖。Agent 的完成声明是一个主观判断,不是可验证的事实。
核心机制:把测试当成验收条件,而不是事后检查项。Agent 完成任务之前必须运行验收命令,且命令必须退出 0。
这个转变听起来简单,但它把「Done」的判断从「Agent 自己说」变成了「一个外部命令的退出码」。
验证循环的完整模式:
#!/bin/bash
# verification-loop.sh — 在 Agent 每次修改后自动运行
MAX_RETRIES=3
RETRY=0
while [ $RETRY -lt $MAX_RETRIES ]; do
pytest tests/auth/ -v --tb=short > /tmp/test_output.txt 2>&1
EXIT_CODE=$?
if [ $EXIT_CODE -eq 0 ]; then
echo "✅ All tests pass. Task complete."
exit 0
fi
echo "❌ Tests failed (attempt $((RETRY+1))/$MAX_RETRIES)"
cat /tmp/test_output.txt
# 把失败输出反馈给 Agent,它会读取并尝试修复
RETRY=$((RETRY+1))
done
echo "🛑 Verification failed after $MAX_RETRIES attempts. Needs human review."
exit 1
验证命令必须具体到可执行。
pytest tests/auth/ -v 比「跑一下测试」具体,grep -r "from auth.session" ./src # must return empty 比「检查没有遗留引用」具体。
越具体的验证命令,越能被自动化执行,Agent 修复时的目标也越明确。
和 LangGraph 的配合:在 LangGraph 里,验证循环可以建模为一个自环节点。
Executor 完成后进入 Verify 节点,Verify 节点运行验收命令,如果失败就返回 Execute 重新执行,如果通过就走向 END。
这个自环对应了「生成→验证→修复→再验证」的自动循环,不需要人工介入。
面试追问方向:
什么样的任务不适合验证循环?
验证命令本身可能有 bug 吗?如果验证命令本身是错的怎么办?
retry 次数怎么定?无限重试会不会烧 token?
第一个问题的答案很关键:验证循环只适用于「有客观验收标准」的任务。创意写作、研究探索这类没有 binary 退出码的任务,不适合强制验证循环。
如果一个任务你写不出「退出 0 代表完成、退出非零代表没完成」的判断,验证循环就不适用。
每次上线前最怕的不是代码有 bug,是测试集本身就没跑通
3.5 Pattern 5:上下文打包(Context Packaging)——解决上下文失效导致的幻觉
问题场景:Agent 在规划阶段就开始猜测代码结构,而不是读取真实文件。
上下文窗口里有大量「我认为」「我记得」「大概是这样」——这些猜测最终变成幻觉文件路径、错误 API 调用和凭空生成的函数签名。
根本原因是:Agent 没有拿到真实仓库的符号地图,只靠 prompt 里几行模糊描述来「脑补」代码结构。
核心机制:在 Agent 规划之前,先运行符号分析,生成 impact map,再把 impact map 注入到 Agent 的上下文里。
Agent 现在知道「仓库里实际存在哪些文件、哪些函数、哪些依赖关系」,而不是凭直觉猜测。
符号分析与 impact map 的生成方式:
# 生成 auth 模块的符号文件
ctags -R --fields=+n --languages=Python ./src/auth/ > .harness/auth_symbols.txt
# 查找所有依赖 auth 模块的文件
grep -r "from auth" ./src --include="*.py" -l > .harness/auth_dependents.txt
# 将两个文件注入 Agent 上下文
cat .harness/auth_symbols.txt
cat .harness/auth_dependents.txt
AGENTS.md 是持久层——它不针对单一任务,而是对所有 session 生效的规则集合:
# AGENTS.md
## Architectural boundaries(不可跨越)
- src/payments/ 不得 import src/auth/ 下的任何模块
- 所有数据库访问必须经过 src/db/repository.py,禁止直接写 SQL
- 新增依赖必须作为 [ASSUMPTION] 列在 plan 里,而不是直接使用
## Existing patterns(遵循这些)
- JWT 处理:src/api_keys/jwt_util.py(PyJWT 2.x,HS256)
- 错误响应:src/core/errors.py 的 ErrorResponse 类
- 环境变量:通过 src/config.py 的 Config 类读取,禁止直接 os.environ
## Pre-task(任务开始前必须执行)
1. 读取 .harness/impact_map.md
2. 输出 plan,格式:files / pattern / verification / [ASSUMPTION]
3. 等待 [APPROVED] 后再执行
上下文打包的 include/exclude 原则:
包含:约束决策的上下文。文件路径(Agent 只能修改这些文件)、现有模式(Agent 必须遵循这些实现方式)、验收标准(精确的命令而非模糊描述)。
不包含:描述其他事物的上下文。历史 Slack 讨论、推测性的未来需求、之前失败尝试的详细记录(会混淆而非帮助)。
Verdent 的工程实践总结了这个原则:200 行高密度 AGENTS.md 优于 2000 行大而全的文档。
密度和相关性胜过全面性——Agent 不需要知道整个仓库,它只需要知道这次任务的相关边界 Agentic Engineering Patterns。
和 LangGraph 的配合:LangGraph 的状态是局部的——每次节点执行时,Agent 只能看到当前消息列表里的内容。
Context Packaging 解决的问题是:在 Agent 看到消息之前,先确保它的上下文里已经有了真实的仓库地图。
一个常见的失误是:把完整源代码塞进 Agent 上下文。超过 500 行的原始代码会让 Agent 注意力分散到无关的细节上。正确的做法是塞入「符号+关系+边界」,而不是源代码本身。
面试追问方向:
如果 impact map 本身不完整,谁来维护它的准确性?
AGENTS.md 和 CLAUDE.md 有什么区别?
上下文打包和 RAG(检索增强生成)在目的上有什么本质区别?
第三个问题是进阶追问。Context Packaging 的本质是「注入代码结构的静态知识」,RAG 的本质是「从文档集合里检索动态答案」。
前者解决的是「Agent 不知道仓库长什么样」,后者解决的是「Agent 不知道外部知识库里有什么」。两者解决的问题集不同,不能互相替代。

每次 Agent 说「我已经在 xxx.py 里添加了方法」,我都得先确认那个文件到底在不在
3.6 Pattern 6:反馈循环工程(Feedback Loop Engineering)——解决 Harness 本身的演进问题
问题场景:团队修了一个 Agent 的错误输出,但同一个错误类在下一周又出现了。问题不是「那次输出错了」,而是「Harness 条件允许那次错误发生」。
单独修输出,不修 Harness,等于每次下雨都去擦墙而不是修屋顶。
核心机制:把 Harness 当成软件来维护,而不是当成提示词来调。
每一个 Agent 失败案例,都应该追溯到根因分类,而不是直接修改 prompt:
| 失败表现 | 根因分类 | Harness 修复方案 |
|---|---|---|
| Agent 修改了错误文件 | CONTEXT | impact map 不完整 → 扩大 ctags 范围 |
| Agent 用错了 JWT 库 | PATTERN | 缺少模式引用 → 在 AGENTS.md 添加显式模式文件 |
| Agent 没跑测试就宣布完成 | VERIFICATION | 验收命令未写入 spec → 加入 task template 默认字段 |
| Agent 改动了范围外文件 | BOUNDARY | 边界未显式声明 → 在 spec 里添加 not-in-scope 章节 |
IMPROVEMENTS.md 是这个反馈循环的持久化载体:
# .harness/IMPROVEMENTS.md
## 2026-04-18:在 AGENTS.md 添加 JWT 模式引用
**触发**:Agent 在 auth migration 任务里使用了 python-jose(应为 PyJWT)
**根因**:PATTERN — 没有现有模式参考
**修复**:在 AGENTS.md patterns 章节添加 `JWT: src/api_keys/jwt_util.py`
**结果**:后续 3 个 session 未再出现此问题
## 2026-04-15:扩展 auth impact map 包含 tests/auth/
**触发**:Agent 分析 auth 依赖时漏掉了测试文件
**根因**:CONTEXT — ctags 命令排除了 tests 目录
**修复**:更新 ctags 命令包含 ./tests/auth/
**结果**:impact map 现在包含 23 个测试文件
这个日志的价值被严重低估了。三条真实改进记录的作用大于 30 次零散的 prompt 修复——因为它让每次修复都变成了一次可积累的工程改进,而不是一次性的临时补丁。
和 LangGraph 的配合:LangChain 团队用这个方法把 Terminal-Bench 的准确率从 52.8% 提升到 66.5% Agentic Engineering Patterns。
这个 13.7 个百分点的提升不是靠换模型实现的,而是靠系统性修复 Harness 根因实现的。
LangGraph 项目里,这个循环可以简化为一个四步流程:记录失败 → 分类根因 → 修改 Harness 构件(AGENTS.md / impact map / verification template) → 验证修复在后续 session 里生效。
面试追问方向:
如果一个错误只出现了一次,还需要加到 IMPROVEMENTS.md 吗?
如何区分「模型能力不足」和「Harness 设计不足」?
Harness 改进的 ROI 怎么衡量?
第二个问题是面试里最难回答的,但它揭示了一个重要判断力:大部分团队把模型能力不足当成了 Harness 设计不足的借口,反过来也有。
区分方法是:如果是同一条 prompt 换模型后好了,说明是模型能力问题;如果是模型换了还是同样失败,说明是 Harness 边界没画清楚。

每次修完 bug 就发版,从来不想为什么会产生这个 bug——这就是 Harness 进不了 sprint planning 的原因
四、集成架构图解:Harness 层与 LangGraph 层的职责边界
前面六节把 Harness 的六种工程模式拆得很细,这一节把它们放回全局视图。
两层的关系不是并列,而是包裹:Harness 层在外圈,负责「上下文准备-规划审批-验收验证」的工程闭环;LangGraph 层在内圈,负责「状态管理-节点执行-条件路由」的图结构运行。
Harness 决定了「Agent 在什么时候、以什么上下文、带着什么约束、去做什么」,LangGraph 决定了「这些任务在图里怎么流转、状态怎么传递」。
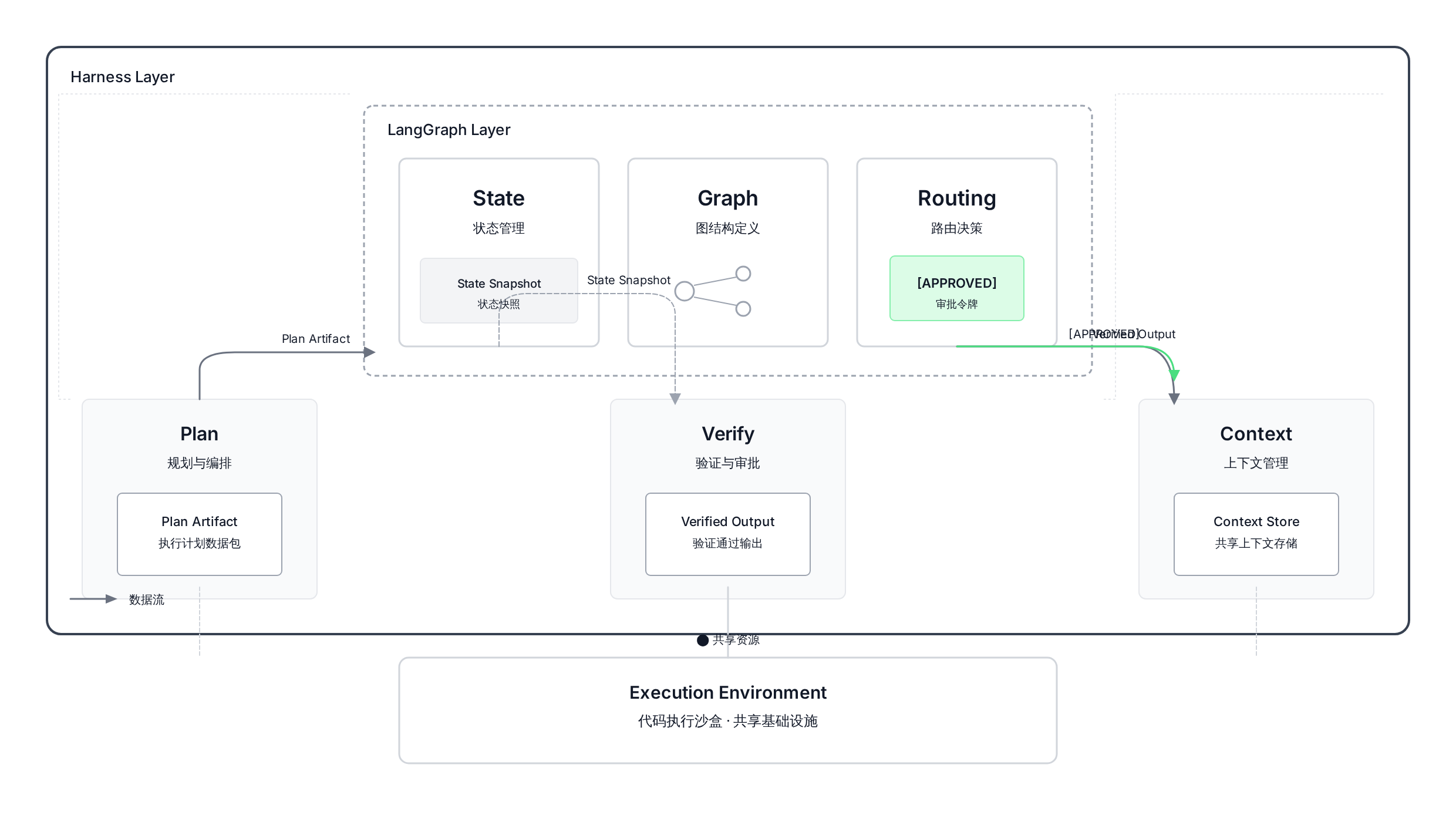
正文图解 1
数据流向的具体含义:
Plan Artifact 是 Harness 层的 Planner 生成的产物——一份结构化的任务计划,包含「需要修改的文件列表、遵循的模式引用、验收命令、假设条件」。
这份 Artifact 被注入到 LangGraph 的状态里,作为 Executor 节点的执行依据。
[APPROVED] Token 是工程师(或自动化审批节点)发出的信号——在 Harness 层这通常是 AGENTS.md 里的一个固定字符串,在 LangGraph 层这触发条件边的路由决定。
Agent 不会自己跳到下一个节点,必须等到 [APPROVED] 才能执行。
State Snapshot 是 LangGraph 层在每个节点执行后的状态快照(由 checkpointer 持久化)。
这份快照被 Harness 层用来做「历史上下文注入」——当一个任务中断后重新启动,Agent 看到的是完整的 State Snapshot,而不是从头开始。
Verified Output 是 Harness 层的验证循环跑完后产生的输出——测试通过、lint 通过、grep 验证通过。这份输出是「任务完成」的客观证据,而不是 Agent 的主观声明。
这个分层架构解释了为什么 LangChain 能在 Agent 场景里显著提升效果:Harness 提供了「让对的事情发生」的机制,LangGraph 提供了「让这些事情有序发生」的结构。
两者各司其职,而不是互相竞争。
面试里画这个图的技巧:
面试官让你画架构图时,不要试图在白板上把六个 Pattern 全画出来。
先画这个两层同心圆的结构,解释清楚包裹关系,再说「这六个 Pattern 是在 Harness 层里解决不同失败场景的具体手段」。
这样面试官知道你不仅会用这些工具,还理解它们在系统里的位置。
面试官最怕的不是你不会画图,是你画了一个平行架构然后解释说「这两层互相配合」
五、面试应答模板:从「讲概念」到「讲工程判断」的跨越
这一节把前四节的内容翻译成三个真实面试问题的高质量回答。每个回答都是「开口版」——候选人可以直接拿这个口径去说,不需要临场组织语言。
5.1 问题:你在项目里怎么保证 Agent 的输出质量?
错误示范:我会加 prompt 让它仔细检查,或者让另一个 Agent 再 review 一遍。
这个回答的致命弱点是:把「质量保证」当成了一个 prompt 问题,而不是一个工程系统问题。面试官追问「如果 prompt 还是不能保证质量怎么办」,这个回答就直接哑火了。
高质量回答(约 180 字,可直接开口):
我在项目里是从三个层面保证输出质量的,不只是 prompt。
第一层是 Context Packaging——在 Agent 开始规划之前,我会先生成 impact map,确保它看到的是真实仓库结构而不是猜测。这解决的是「因为上下文不完整导致的幻觉」。
第二层是 Verification Loop——Agent 完成任务后,必须运行验收命令,命令退出 0 才算完成。
我不会相信 Agent 自己的「完成声明」,而是看测试是否通过、grep 是否返回空、lint 是否 clean。这把「完成」从一个主观判断变成了一个客观退出码。
第三层是 Feedback Loop Engineering——每一次失败,我都会追溯根因,然后修改 Harness 构件(AGENTS.md、impact map 或 verification template),而不是只修当次 prompt。
这个习惯让 Harness 本身在迭代中越来越可靠。
我理解这三层对应了不同的失败模式:Context 层解决「不知道仓库什么样」,Verification 层解决「Agent 高估自己」,Feedback 层解决「同类错误反复出现」。
5.2 问题:LangGraph 和其他 Agent 框架的区别是什么?
错误示范:LangGraph 支持循环,其他框架不支持。
这个回答太浅了。几乎所有主流 Agent 框架都支持循环——ReAct、AutoGPT、 CrewAI 都有循环。单纯说「支持循环」等于没说。
高质量回答(约 220 字,可直接开口):
LangGraph 的核心差异是把「状态」当成一等公民,而不是把「prompt」当成一等公民。
大多数 Agent 框架的运行模型是:一次 prompt 进、一次 response 出,下一步是完全独立的新请求。
LangGraph 的 StateGraph 模型是:状态在节点之间传递,每个节点执行后用返回值更新状态,状态可以持久化、中断恢复、跨线程复用。
这带来三个实际区别。第一,多轮对话的状态管理不需要自己写内存层——checkpointer 已经内置了,支持 thread_id 维度的状态隔离。
第二,人机交互(HITL)可以建模为图里的条件边:Agent 在某个节点暂停,等待人类批准,然后继续执行。
第三,循环控制是声明式的——用 add_conditional_edges 决定「满足什么条件就重新执行」,而不是用 while 循环硬编码。
但 LangGraph 不解决「Agent 在图里做什么是对的」这个问题——那是 Harness 层要解决的。
LangGraph 管「怎么跑」,Harness 管「跑什么、跑对没有」。这两个层是包裹关系,不是竞争关系。
5.3 问题:如果让 Agent 自主运行 4 小时不出错,你会怎么设计 Harness?
错误示范:我会加很多 prompt 强调要仔细,不能出错。
这个回答完全是 prompt 思维,在工程层面没有意义。4 小时的自主运行意味着大量的上下文切换、状态保持、错误恢复——这不是 prompt 能解决的。
高质量回答(约 260 字,可直接开口):
我会从失败模式分类入手,再针对每类设计 Harness 手段,而不是靠加强 prompt。
4 小时自主运行里,最可能出现的失败有三类。
第一类是 Context 失效——Agent 运行 2 小时后,因为上下文窗口接近上限,之前的仓库知识被挤压掉了,开始产生幻觉文件路径。
我会设计 Context Packaging + 定期 impact map 刷新机制:每完成一个任务块,就重新注入一次仓库符号地图。
第二类是 Direction 漂移——Agent 跑了 1 小时后开始做范围蔓延,不自觉地进入了 spec 之外的功能。
我会设计 Plan-First + [APPROVED] Gate:每个子任务块开始前,Agent 必须输出一份 plan 并等待批准,范围边界在 plan 里显式声明,未声明的改动在 review 阶段会被打回。
第三类是 Output 质量衰减——Agent 写代码的前 30 分钟质量高,后面因为疲劳或者上下文混乱开始产出带 bug 的代码。
我会设计 Verification Loop:在每个功能块完成后自动跑测试,测试不通过就触发 retry(最多 3 次),3 次之后人工介入。
另外我会用 Role-Separated Agents 把 Executor 和 Reviewer 分开,避免自己写代码自己 review 的系统性偏差。
整体架构是 Harness 层在外圈包住 LangGraph 的状态机,Harness 负责「什么时候让 Agent 继续」,LangGraph 负责「Agent 之间状态怎么传递」。
六、项目落地指南:在 LangGraph 项目里引入 Harness 思维
从面试回到工程实操。这一节给出一个最小可行的 Harness 引入路径,适用于已经有 LangGraph 基础、想把项目工程化水平提升一个台阶的工程师。
第一步:建立 AGENTS.md
不要一开始就写 2000 行的 AGENTS.md。从一份 50 行的最小可行版本开始:
# AGENTS.md
## Architectural boundaries
- [ ] 列出 3 条最常被突破的边界
- 示例:所有数据库操作必须经过 src/db/repository.py
## Existing patterns
- [ ] 列出 3 个最重要的现有模式文件路径
- 示例:JWT 处理 → src/api_keys/jwt_util.py
## Pre-task
1. 运行 `bash .harness/gen_impact.sh` 生成 impact map
2. 读取 .harness/impact_map.md
3. 输出 plan,格式:FILES / PATTERN / VERIFICATION / [ASSUMPTION]
4. 等待 [APPROVED] 后再执行
## Verification
- 每个任务必须有至少一条可执行的验证命令
- 示例:`pytest tests/ -v --tb=short`
这份文件不需要完美,重要的是它存在——有了它,Harness 才有持续改进的锚点。
第二步:生成 impact map
#!/bin/bash
# .harness/gen_impact.sh
TASK=$1
OUTPUT=.harness/impact_map.md
echo "# Impact Map — $TASK" > $OUTPUT
echo "Generated: $(date)" >> $OUTPUT
echo "" >> $OUTPUT
# 按模块生成符号文件
ctags -R --fields=+n --languages=Python ./src/ > .harness/symbols.txt
# 查找与任务相关的文件
echo "## Related Files" >> $OUTPUT
grep -r "$TASK" ./src --include="*.py" -l >> $OUTPUT
echo "## Dependencies" >> $OUTPUT
grep -r "from.*$TASK\|import.*$TASK" ./src --include="*.py" -l >> $OUTPUT
echo "✅ Impact map generated at $OUTPUT"
第三步:维护 IMPROVEMENTS.md
每次 Agent 运行结束后,快速过一遍日志,记录失败案例:
## 2026-04-29:添加 auth impact map 包含 middleware 层
触发:Agent 在 auth migration 里漏改了 src/auth/middleware.py
根因:CONTEXT — impact map 只覆盖了 src/auth/ 直接子目录
修复:ctags 命令改为 `ctags -R --fields=+n ./src/`(递归全部)
验证:未复现于后续 2 个 session
工程成本估算:
建立这套 Harness 基础设施的初始成本大约是 1 到 2 个 sprint(约 2 到 4 周工程师时间),主要是写 AGENTS.md 的前几个版本、调试 impact map 脚本、维护最初的 5 到 10 条 IMPROVEMENTS.md 记录。
长期收益是:Agent 输出的可靠性从「时好时坏」变成「可量化的准确率」,调试成本从「每次都去修 prompt」变成「系统性改 Harness」。
对于日均 Agent 调用超过 50 次的团队,这个 ROI 非常清晰。

看完这篇去配环境,不如先打开你的 LangGraph 项目,把 AGENTS.md 先建起来再说