
你在实习第一个月fork了LangGraph,改了两行状态机逻辑,mentor说「没问题,先这么跑着」。
第三个月上游发了v0.3.0,你的分支跑不起来了,merge conflict堆了47个文件,测试从绿变红,mentor路过问了一句「怎么还在调这个」,然后走了。

这一把,终于像样了
这不是小概率事件。这是每一个没有建立fork管理纪律的团队必然会经历的宿命——只不过有人踩过一次就学会了,有人踩过三次还在用「重新fork一份」这种原始手段凑合。

这一段,懂的都懂
二次魔改不是技术难题。真正的门槛是:当fork不再是一次性操作,而是需要持续维护的生命周期工程时,你的团队有没有一套纪律把它撑起来?
本文从三个维度拆这套方法论:fork管理怎么从「顺手fork」升级为「生命周期设计」;upstream同步怎么从手动凑合升级为「策略化取舍」;
diff维护怎么从「改完就跑」升级为「语义化可追溯」。
每个维度都会给出面试专项应答结构,因为这个专题在2026年的AI框架面试里已经不是边缘题——它正在成为判断工程师是否真正在生产环境里跑过LangGraph、Claude Agent SDK、Microsoft Agent Framework这些框架的核心筛选题。

上游发版,我的魔改代码全红了
一、fork管理:从一次性操作到生命周期工程
1.1 fork的命名规范与仓库拓扑设计
大多数工程师fork一个仓库,只需要三秒:点按钮,改个本地文件夹名字,然后git clone到本地。没有任何命名规范,没有任何拓扑设计,仓库之间的关系全靠「我记得这个是改过的」来维护。
这是个人项目没问题。
但当你同时fork了三个框架,每个框架改了三个不同模块,三条分支各自跑在不同项目里,到第四个月你连「我那个改了工具节点的langgraph是从哪个fork拉的」都答不上来的时候,fork就已经从节省时间变成了制造混乱的源头。
一个可维护的fork命名规范,通常包含三层信息:原始仓库标识、改动目的、版本锚点。
举例来说,如果你fork了langchain-ai/langgraph做状态持久化改造,规范的本地分支命名应该是feature/langgraph-stateful-checkpoint-v0.2.x——原始仓库名标清楚了是langgraph,改动目的是stateful-checkpoint,对应的上游版本是v0.2.x。
这个命名逻辑的好处是:当你在六个月后回看这条分支,你能立刻知道这个改动依赖的是哪个上游版本,升级时需要优先检查哪些兼容性问题。
仓库拓扑设计是另一个被严重低估的决策点。当你fork一个框架做二次魔改,仓库之间的关系不是一条直线——它是一张网。
原始上游仓库(upstream)不断发版,你的fork(origin)持续承载魔改代码,origin可能还有多个feature分支各自对应不同的项目需求,更复杂的场景下还有团队共享的内部fork作为中转层。
如果这套拓扑关系没有显式文档化,新人接手时只能靠读代码猜关系,猜错的代价就是破坏性合并(destructive merge)和难以追溯的回归故障。
工程上推荐的拓扑文档模板其实很轻量,不需要复杂的图表工具:一张 mermaid 格式的仓库关系图,加上每个仓库节点对应哪个上游版本范围、一句话说明改动范围、一个维护责任人。
这个文档放在仓库根目录的FORKS.md里,每次做同步合入前更新版本锚点。维护成本极低,但能在六个月后救你一命。
面试里被问到fork管理的命名规范,很多候选人会回答「用有意义的名字」——这个答案没错,但信息量约等于没说。
真正有竞争力的回答是:你知道这个规范要同时服务两个读者——一个是当下的你,需要快速定位哪个fork对应哪个需求;一个是六个月后接手的人,需要在没有你的情况下理解这套拓扑关系。
前者考验的是经验,后者考验的是工程意识。很多候选人只有前者,面试官一听就知道这是野生经验,没有被工程纪律训练过。

你这fork命名……我猜是langgraph的某个版本?
1.2 实验性fork vs.生产性fork的工程边界
fork仓库在工程里有两种截然不同的用途,它们的维护策略完全不同,但大多数团队把它们混为一谈,结果是哪边都没管好。
实验性fork的特点是:探索性强、存活周期短、接受高风险。
一个实习生想试试把LangGraph的状态机换成自定义的Redux风格实现,她fork了仓库,花三天做了一个PoC,跑通了就合并回主线,跑不通就删掉重来。
这个场景下fork的维护成本应该是零——不需要建立upstream同步,不需要写测试,不需要持续集成,因为它本质上是一个一次性实验环境。给它建立严格的工程流程反而是过度工程化。
生产性fork的特点是:改动需要在多个版本周期内与上游保持兼容、跑在真实业务流量里、不能因为上游发版就随时崩溃。
LangChain团队自己在内部维护的那些深度定制分支就属于这一类:他们fork了langgraph-core,改了状态流转逻辑,这个改动需要持续跟随上游的核心API更新,否则业务代码每隔几周就要做一次灾难性重构。
这类fork的维护成本是正向投资,不是负担——省掉这套纪律,生产阶段必然会用更多的排障时间买单。
区分这两种fork是很多工程师面试时答不好的地方。常见误判是把所有fork都当成「临时实验」,或者反过来把任何改动都当成「生产级需求」来管理。
前者的代价是生产代码在版本升级时集体爆炸,后者的代价是大量过度工程化的基础设施消耗在根本活不过一个月的PoC上。
判断一个fork应该走哪种工程路径,有一个简洁的决策标准:这条改动在fork里存续的时间预期是多久?
如果超过两个月,或者这个项目已经进入排期而非探索阶段,它就应该走生产性fork的管理流程——建立upstream remote、配置CI、补充测试、编写CHANGELOG条目。
如果只是一个周末的PoC,就让它保持轻量,不要把工程纪律的重量压在它身上。
在面试里,面试官问「你如何管理fork」,真正想知道的是你能否区分这两种场景。
很多候选人能说出「要建upstream」,但说不清楚「什么时候该建,什么时候不需要」——这暴露的是工程判断力不足,而不是git命令不熟。
面试官更想听到的是:你知道哪些场景值得投入维护成本,哪些不值得,以及你用什么标准做这个判断。

行,这个fork我当成生产级来管
1.3 fork废弃与归档的工程纪律
被废弃的fork是技术债里最安静、最容易被忽略的一种。
它不会像代码异味那样每次读都刺眼,也不会像循环依赖那样在编译时报错——它只是躺在那里,每隔三个月弹出一次「此仓库有安全漏洞」的邮件通知,然后继续躺在那里。
直到某一天,有人把这个废弃fork的URL写进了某个基础设施配置里,然后上游发了一个CVE(Common Vulnerabilities and Exposures),你的CI开始报警,安全扫描开始报错,运维开始追是谁把这个废弃仓库配进了生产路径。
整个事件链的起点,是一个三个月前就已经不再使用的fork,没有人归档,没有人清理,也没有人把它的引用关系做一次断连。
fork废弃的工程纪律包含三个强制动作:第一个是引用清理,所有指向这个fork的CI配置、依赖声明、镜像引用必须在废弃前完成断连,不能留活口;
第二个是归档标记,废弃的fork不要直接删除(除非确认没有任何外部依赖),而是转移到归档命名空间,改README第一行为[ARCHIVED] This fork is no longer maintained,写清楚废弃日期和替代路径;
第三个是文档同步,所有引用了这个fork的系统设计文档、团队知识库、工程规范,必须在废弃操作完成后同步更新,不能出现文档里指向一个已经不存在的仓库的情况。
这个环节在面试里被问到的频率相对低,但它的回答质量往往能区分一个「做过但没想过」和「做过并且有体系」的工程师。
面试官如果追问「你们团队fork了哪些仓库,有多少是活跃维护的」,能立刻说出「活跃3个,废弃归档4个,每个都记录了废弃原因和时间」的人,显然比「呃……没统计过」有说服力得多。
二、upstream同步:不是技术问题,是工程纪律问题
2.1 upstream remote的建立与验证机制
把upstream同步做好的第一步,是把remote配置做对。
但凡在GitHub上fork过一个仓库然后手动添加过upstream remote的工程师,大概都知道这个操作本身没有技术门槛。
真正出问题的地方在于:建立了upstream remote,然后再也没有验证过它是否还能用。
upstream remote失效的原因比大多数人以为的更常见。上游仓库改名了——LangChain v0.2到v0.3的过渡期就经历过一次仓库重组;
上游仓库迁移了组织——微软把Semantic Kernel从Azure SDK组织迁移到独立仓库时,很多团队的upstream remote配置直接失效;
上游网络访问路径变了——内网环境里直接访问GitHub的URL被墙掉,需要走代理,但remote配置里没更新。
这些都是纯运维层面的变更,不影响你的代码逻辑,但会让git fetch upstream永远返回空的更新记录。
一个可靠的upstream配置验证机制,至少应该包含两个自动检查点。
第一个是fetch验证:CI在每次运行前执行git fetch upstream --tags --verbose,验证remote可访问且返回非空结果,失败则报警;
第二个是版本锚点校验:定期检查upstream/main的最新tag是否与本地记录的锚点版本存在合理差值——如果差值超过预期(比如超过5个版本),说明这个fork的同步已经严重滞后,应该触发人工介入提醒。
面试时说到upstream配置,很多人会直接写git命令:
git remote add upstream https://github.com/langchain-ai/langgraph.git
git remote -v
git fetch upstream
git merge upstream/main
这组命令本身没问题,但只回答了「怎么做」,没有回答「怎么保证它持续有效」。
面试官追问「如果upstream的仓库改名了,你的配置会怎么样」,答不上来的候选人占大多数——而这个问题在实际生产环境里几乎每个人都会遇到一到两次。
能回答出来的工程师,说明他对代码库的生命周期维护有过真实经历,而不是只在个人项目里跑过fork流程。
upstream改名了,fetch了一年的记录全空了
2.2 三种同步策略的本质取舍:merge / rebase / cherry-pick
upstream同步在技术实现上有三条路:merge、rebase、cherry-pick。
大多数工程师知道这三种方式,但分不清在什么场景下该选哪个——结果就是永远用merge,因为最省事,然后被merge commit噪音折磨得苦不堪言。
merge策略的本质是「保留历史」。
当你执行git merge upstream/main,上游的所有commit历史原封不动地进入你的分支,每一条merge commit忠实地记录了「哪个时间点同步了上游哪个版本」。
这套历史记录对审计友好,对回滚友好,但对长期维护的分支来说,merge commit噪音会让git log变成一份难以阅读的考古文献。
更关键的是,如果你的fork分支存活周期超过三个月,merge策略会产生大量「顺带合入的非目标commit」,你在回溯问题时需要花大量精力过滤无关历史。
rebase策略的本质是「重写线性历史」。
当你执行git rebase upstream/main,你的每一条commit被重新应用到上游最新代码之上,历史变成一条干净的直线,没有merge commit噪音。
它的代价是rebase会改写commit hash,如果你已经把这个分支push到了任何共享远程分支,强制push(git push --force)是必须的操作——而强制push在团队协作环境里是高风险动作,需要所有人知道你这么做了,否则别人的本地提交会在下一次pull时产生难以预料的冲突。
rebase适合的场景是:你有若干条commit是你自己的实验性改动,需要干净地应用在新的上游基准上,而且你确认没有别人依赖这个分支的历史。
cherry-pick策略的本质是「选择性移植」。它不是全量同步,而是从上游挑选特定的commit应用到你自己的分支。
这在二次魔改场景里有独特的价值:你的框架改动只依赖上游v0.2.5里的两个bugfix,不需要把整个v0.3.0合进来造成大规模API迁移压力。
cherry-pick让你精确控制合入范围,把升级成本从「全量同步」压缩到「按需移植」。
但cherry-pick的代价是容易遗漏上游的隐式依赖——两个commit可能看起来独立,但背后共享了同一个基础模块的改动,单独cherry-pick一个会导致运行时行为异常。
在LangGraph这类框架的二次魔改场景里,我见过最常见的组合策略是:日常维护用rebase保持分支干净,在需要同步特定上游修复时用cherry-pick精确控制合入范围,只在需要完整跟随上游大版本升级时才动用merge——而且会配合squash把噪音降到最低。
这个组合不是唯一的正确答案,但它展示了「策略选择」背后的工程判断逻辑,而这种逻辑才是面试官真正想听的。

你这merge commit比我改的代码还多
2.3 同步频率与自动化方案
upstream同步的频率本身不是技术问题,而是工程纪律问题。一个每年同步一次上游的fork,和一个每周同步一次的fork,面临的风险结构完全不同。
前者积累了三到五个breaking change的迁移工作量,需要一次性处理;后者只面对相邻版本间的差异,单次处理成本低,但总的操作次数多。
两种策略各有优劣,取决于你改动范围的深度和上游发版节奏。
对于LangChain、LangGraph这类处于高速迭代期的AI框架,上游发版频率大概是每月一个minor版本、每季度一个major版本。
如果你维护的fork有生产级改动需要跟随上游,自动化方案是必要的——否则工程师会不断被「要不要同步」这个决策消耗注意力,直到某天积压到无法同步。
成熟的自动化同步方案通常包含两个组件:定时任务和PR/MR生成机器人。
定时任务可以是GitHub Actions的schedule触发器,以周为单位执行git fetch upstream,检测是否有新的commit或tag,如果检测到更新则自动生成一个SYNC-PR描述同步范围、涉及的API变更和预估测试成本。
这个PR不是自动合并,而是触发人工审查——因为自动合并不总是安全的,上游新版本的API变更可能和你魔改代码的内部调用产生不兼容,自动合并会把这个问题直接推进生产环境。
有些团队更进一步,把自动化做到了「先跑测试再通知」的程度:定时任务在fetch到上游更新后,先在隔离环境里把自己的魔改分支rebase到新上游,跑一套冒烟测试,测试通过才生成通知提醒维护者「本周上游有N个commit,测试已通过,建议合并」。
这套流程把同步决策从「我什么时候想起来手动同步」变成「系统告诉我该同步了,而且已经帮我验证过了」。
面试里被问到「你们团队如何决定同步频率」,最见功力的回答不是给一个固定数字,而是讲清楚:你们怎么判断一个fork是否已经处于同步滞后状态,用什么指标来量化「滞后」,以及自动化方案是否覆盖了检测到通知到审查的全链路。
给数字容易,「为什么要给这个数字」才是工程判断力的体现。

又到同步日了,这个conflict我先看着
2.4 同步冲突的处理流程与决策树
upstream同步里最让人血压升高的环节,不是写代码,是处理conflict。但conflict本身不是问题——conflict处理流程不规范才是。
当你的fork分支和上游产生了conflict,标准处理路径不是立刻埋头解决conflict,而是先评估conflict的范围和性质。
这个决策树的第一个节点是:conflict发生在哪个文件?
如果conflict集中在你魔改的核心文件(比如state.py、graph.py这类你自己改过的模块),这是高风险conflict,处理时需要同时理解上游的改动意图和你的改动意图,盲目保留任何一方都可能引入语义错误。
如果conflict集中在上游新增的功能文件(比如上游新增了一个experimental/目录),这是低风险conflict,可以优先保留上游版本。
第二个节点是conflict数量。如果conflict文件超过10个,通常说明你的fork分支已经严重滞后于上游,继续做rebase或merge的边际成本会急剧上升。
这种情况下更经济的做法是:先把你的核心魔改逻辑抽取为独立的patch文件(或git stash save保存为一个commit),然后用git rebase --abort放弃当前同步尝试,重新fork一份干净的仓库,从零应用patch,最后用新的fork作为后续维护基准。
这套操作听起来很重,但比在一个积压了几十个小版本差异的conflict地狱里挣扎要快得多。
第三个节点是冲突是否涉及测试文件。很多工程师在conflict解决后只跑主逻辑测试,忽略测试文件——这是经典的回归引入路径。
上游在API改动的同时更新了对应的测试用例,如果你保留了旧的测试代码,测试会静默失败,你的CI在下一轮回归里才会报出来。
正确的做法是:conflict解决后,先把上游的测试文件完整同步过来,然后在你的魔改代码上跑完整测试套件,确保没有行为回归。
面试里说到conflict处理,很多人会说「看代码解决」。这个答案正确但没用,因为没有解决「怎么看」和「谁决定保留哪边」。
面试官真正想听到的是:你有没有一套判断框架来评估conflict的风险等级,你有没有在解决conflict后跑完整测试套件而不是只跑主逻辑,以及当你判断conflict范围已经超出可维护阈值时,你知不知道应该回退到patch抽取方案而不是硬着头皮merge下去。
这三个问题分别对应了conflict处理的风险评估能力、测试纪律和工程决策能力——后两者比「会看diff」更难伪装。
三、diff维护:让二次魔改保持可读、可升级、可贡献
3.1 diff的语义化组织原则
diff是二次魔改的核心交付物。一个健康的二次魔改diff,应该满足三个标准:语义可读——reviewer能在不读上下文的情况下理解这条改动在做什么;
版本可升级——当上游发版时,这个diff能以最小成本重新应用在新的上游基准上;贡献可回流——如果你的魔改对上游有价值,它能被整理成PR贡献回原始项目。
语义可读的关键在于commit粒度的控制。一个包含200个文件改动的巨型commit,即使内容再正确,reviewer也无法有效审核。
我见过最糟糕的二次魔改commit历史是这样的:一条commit叫「更新」,另一条叫「更新2」,第三条叫「final更新」,全部混在一起改了几十个模块。
这种commit历史对维护者来说是噩梦——当你需要回滚一个特定的bugfix时,你根本分不清该回退哪条commit。
语义化commit的实践标准可以参考Conventional Commits规范,核心要求是每条commit对应一个完整的语义改动:feat、fix、refactor、test、docs、chore——每个类型对应一种改动性质,每条commit的描述要回答「改了什么、为什么改」,而不是「更新了什么」。
在二次魔改场景里,我建议额外增加两个commit类型前缀:upstream-sync:标记从上游同步的改动,patch:标记从其他分支cherry-pick过来的修复。
这两个前缀能让你在git log里快速区分哪些是你自己的改动,哪些是外部引入的同步内容。
版本可升级是diff维护里最容易被忽视的要求。二次魔改的代码在写的时候,通常是针对当前上游版本写的,没有人会预装「六个月后上游会新增一个参数导致我的调用方式不兼容」这种感知。
但如果你在写diff的时候就考虑可升级性,很多后续迁移成本可以前置消解。
具体做法是:给所有涉及上游API调用的地方写清楚版本锚点注释——# Called against langgraph==0.2.8 StateGraph API, depends on 'input_schema' field,这个注释在六个月后升级到v0.3.5时能立刻告诉你需要检查哪个文件,而不需要靠代码考古来推断当时的依赖关系。
贡献可回流是最高层次的要求,但不是每个二次魔改都需要走到这一步。只有当你确认你的改动足够通用、不依赖特定的业务上下文、且上游社区有相关议题讨论时,回流贡献才有意义。
大多数团队内部fork的魔改都绑定了业务逻辑,不适合贡献回上游——这没关系,知道「这个diff我选择不贡献」和不知道「贡献这个概念」是两件完全不同的事。
面试里能主动区分「可贡献」和「不可贡献」的二次魔改,说明候选人对开源生态的运作方式有过实际观察,而不只是埋头fork。

你这个commit叫'更新',我review个什么
3.2 二次魔改的版本注释与变更日志维护
版本注释不是给现在的自己看的,是给六个月后接手这个fork的工程师看的——而那个人大概率就是你自己,只是你忘了当时为什么要这么改。
二次魔改场景下的版本注释有三种必填字段:上游版本锚点、被修改的API范围、以及改动意图。这三个字段组合在一起,才能在看到一条古老的commit时快速重建当时的上下文。
先说上游版本锚点。每次从上游同步或cherry-pick一个commit后,commit message里应该强制记录:同步自哪个上游tag或commit hash。
比如upstream-sync: cherry-pick langgraph@v0.2.8 #a3f5c12 fix: StateGraph edge case handling。
这样当未来遇到兼容性问题时,你可以在本地快速验证「当时上游的哪个版本有这个修复」。
被修改的API范围要具体到方法级别,不只是文件名。
比如你修改了StateGraph.add_node的行为,不仅要记录文件名,还要说明修改的是哪个参数的处理逻辑、是否改变了方法的签名、是否影响了返回值结构。
三个月后你看到这条注释,立刻知道需要检查的是哪个接口的向后兼容性。
改动意图是三种字段里最重要的,也是最容易被省略的。
很多工程师觉得「代码本身就是意图」,但二次魔改场景下这句话不成立——你改的代码依赖的是上游某个特定版本的内部实现,这个内部实现可能是bugfix、可能是未公开的行为、可能是某个特定场景下的临时hack。
代码本身不会告诉你「为什么要在这个版本上改」,而改动意图可以。
变更日志维护在二次魔改里有一个特殊要求:区分「上游引入」和「我们引入」。所有从上游同步过来的改动,在CHANGELOG里用[upstream]前缀标记;
所有我们自己魔改的改动,用[patch]前缀标记。这个简单区分在审计时价值巨大——它能让你在看到一个问题时立刻判断这是上游引入的、还是自己改出来的。
如果你的团队使用monorepo管理多个fork的魔改,建议维护一个共享的FORK_META.json文件,每个fork的记录包含当前基准版本、最近同步时间、活跃魔改数量和负责人。
这个文件放在repo根目录,每次同步后更新时间戳,不更新这个文件的PR应该被CI拒绝。

注释我都写了,CHANGELOG还要单独维护?
3.3 从二次魔改到上游贡献的路径设计
不是每个二次魔改都值得贡献回上游,但每个值得贡献的二次魔改都必须从一开始就按可贡献的方式组织。这是二次魔改里最具工程师判断力的分叉口。
判断一个二次魔改是否值得贡献回上游,有三个前置条件:第一,改动必须足够通用,不能依赖特定的业务上下文;第二,上游社区得有对应的议题讨论或已知的需求缺口;
第三,贡献路径不能比你维护这个fork的成本还高。三个条件同时满足,才值得走贡献路径。
如果判断值得贡献,贡献路径从fork创建阶段就已经开始了。
具体来说,你的commit history必须在整个生命周期里保持语义化——因为上游维护者review你的PR时,第一件事就是看你的commit结构是否清晰。
如果你的commit history是一堆「update」「fix」「more fixes」,上游reviewer会直接要求你squash,这时候你就得在本地重新组织commit,这个重组织的成本有时候比写代码还高。
贡献回上游的标准PR结构应该是这样的:PR描述里首先说明「这个改动解决了什么问题,这个问题在哪些版本上存在」,而不是先讲「我们做了这些改动」。
上游维护者关心的是问题,不是你的实现细节。然后在正文中给出最小化的复现代码、现有的测试用例、以及你对这个改动的边界条件理解。
有一点需要特别提醒:从二次魔改贡献到上游,不等于把整个fork的改动打包成一个巨大的PR。贡献应该是一次一个小改动,每条PR对应一个完整的语义改动。
如果你的fork积累了几十个相关改动,应该把它们拆成若干独立的PR逐条贡献,而不是一次性塞给上游维护者一份「你猜这里面都是啥」的大礼包。
贡献路径还有一个常被忽视的价值:它是对你代码质量的外部验证。如果你的改动通过了上游的review,说明它的设计思路和代码质量至少达到了上游维护者的标准。
这个信号在面试里比你自己说「我的代码质量很高」可信得多。
四、工程方法论:二次魔改的闭环质量保障
4.1 CI/CD在fork管理中的角色
CI/CD在二次魔改里的作用比在普通仓库里更关键,因为二次魔改天然处于一个「上下游同时变化」的双重风险环境中:上游发版可能破坏你的魔改逻辑,你的魔改改动可能在新上游版本上出现兼容性问题。
没有CI护着,这个双向风险全靠人工盯,盯不住。
Fork管理的CI至少要覆盖三个流水线节点。第一个是同步检测节点:定时任务检测上游是否有新版本发布,如果有,自动触发构建。
这个节点不需要等人工确认,它的作用是把「不知道上游发版了」变成「知道上游发版了」。
第二个是回归验证节点:当fork的代码有新的本地改动时,在多个上游历史版本上跑完整测试套件。
这里的「多个上游历史版本」指的是从你fork时的基准版本到当前上游最新版本之间的每个minor版本。
这个矩阵式测试能提前暴露「你的改动在新上游版本上是否还work」的问题,而不是等生产环境里撞上。
第三个是发布质量门禁节点:在真正发布一个新版本前,CI需要跑完所有冒烟用例、lint检查、以及上游兼容性检测。这三个检查有一个失败,CI就应该卡住,不允许发布。
二次魔改的发布频率通常不高,但每次发布的影响面可能很大——因为下游可能有其他团队在依赖你的fork版本。
GitHub Actions是二次魔改CI的首选工具,它的schedule trigger可以精确控制定时任务的执行时间,matrix strategy可以并行跑多个版本的环境,artifact功能可以保存每次构建的中间产物供问题追溯。
对于团队级fork,建议把CI配置抽成共享的workflow模板,多个fork仓库引用同一个模板,CI规则升级时只需要改一个地方。
有一点值得注意:CI不只是技术工具,还是工程纪律的载体。
当你知道每次PR都会被CI卡住「需要所有测试通过才能合并」,团队成员就会更自觉地在本地跑完测试再提PR,而不是抱着「CI会帮我catch」的心态随便提交。
这个心理效应比CI本身的技术价值更重要。

CI又红了,这周第几次了
4.2 测试覆盖与回归验证标准
二次魔改的测试覆盖有一个和普通项目不同的核心挑战:你的测试既要验证你自己的改动没有引入bug,又要验证你的改动在各种上游版本上仍然行为正确。这个双重验证目标决定了测试组织方式必须做区分。
建议把测试套件分成三层。第一层是核心逻辑测试:这部分测试验证你魔改代码的业务逻辑是否正确,与上游版本无关。这些测试应该针对你的patch逻辑编写,覆盖正常路径和边界条件。
第二层是API兼容性测试:这部分测试验证你的魔改代码对上游API的调用方式是否在各个上游版本上都兼容。
具体做法是:针对你魔改代码里涉及的每个上游API调用,编写一个专门的测试用例,这个用例在不同上游版本的环境里都跑一遍。
如果某个上游版本的API参数变了,兼容性测试立刻失败,而不是等到生产环境才发现。
第三层是集成冒烟测试:这部分测试验证整个fork在真实场景下是否能正常启动和运行。
对于LangGraph这类框架,集成测试通常涉及构造一个简单的图、跑一遍完整的执行流程、验证输出是否符合预期。集成测试不需要覆盖所有边界条件,它的作用是快速判断「整体是否还活着」。
回归验证的标准是什么?至少三条:你的核心逻辑测试全部通过,API兼容性测试在当前上游版本和最近两个历史版本上全部通过,集成冒烟测试在当前上游版本上全部通过。三条有一条不满足,不做合入。
对于生产级fork,建议维护一个测试覆盖率基线。fork刚创建时跑一次覆盖率,作为基准线;每次有新的魔改合入时,测试覆盖率不能低于基准线。这个指标可以防止「魔改越来越复杂但测试越来越水」的慢性退化。
面试时被问到「你们fork的测试覆盖率达到多少」,真正有价值的回答不是给一个数字,而是解释清楚你的三层测试结构和各自覆盖的目标。
没有分层结构的覆盖率数字没有意义——覆盖率90%但全集中在核心逻辑测试、API兼容性测试为零,和覆盖率70%但三层都有覆盖,后者才是更健康的测试策略。
4.3 文档与代码一致性维护
二次魔改里最常见的工程债务之一,是文档和代码渐行渐远。代码改了三次,文档还停在第一次fork时的状态;API签名变了,README里的示例代码还是旧版本。
这种不一致在团队内部会造成沟通成本,在对外发布时会造成用户信任损失。
文档与代码一致性维护的第一原则是:文档变更必须和代码变更一起提交。
Git的pre-commit hook可以强制执行这个规则——如果有人尝试提交代码变更但没有同时更新相关文档,hook直接拒绝这次提交,并给出提示「请同时更新相关文档后再提交」。
这个hook的实现在GitHub Actions里可以这样写:
#!/bin/bash
# pre-commit hook: 检查是否有代码变更但缺少文档变更
CHANGED_FILES=$(git diff --cached --name-only)
CODE_FILES=$(echo "$CHANGED_FILES" | grep -E '\.(py|ts|js|go)$')
DOC_FILES=$(echo "$CHANGED_FILES" | grep -E '\.(md|txt|rst|doc)$')
if [ -n "$CODE_FILES" ] && [ -z "$DOC_FILES" ]; then
echo "代码变更检测到,但未发现相关文档更新。"
echo "请同时更新相关文档后再提交。"
exit 1
fi
exit 0
对于LangGraph这类框架的二次魔改,文档至少要包含三个核心部分:魔改说明(覆盖了哪些上游API、改了什么、为什么改)、版本兼容性说明(当前fork基于哪个上游版本、已知兼容哪些上游版本、不兼容哪些)、以及迁移指南(从旧fork版本升级到新版本需要做什么改动)。
版本兼容性说明是最容易被忽略的部分,但它恰恰是下游用户最关心的。
用户想知道「我当前的上游版本能不能用你的fork」,如果你的文档里没有这个信息,用户只能自己试错,试错成本最终会变成对你的项目的不信任。
五、面试专项:从fork管理能力到面试应答结构
5.1 高频追问一:「你如何保持fork与上游的兼容性?」
这道题的本质不是在问Git命令,是在问「你对这个fork的长期可维护性有没有预期和规划」。
一个只在fork创建时想过兼容性问题、之后就没管过的工程师,和一个从fork创建阶段就设计了兼容性保障方案的工程师,在这个问题上的回答质量差距巨大。
标准应答结构分三层。第一层是预防层:说明你在fork创建阶段的兼容性设计——所有涉及上游API调用的地方都写了版本锚点注释,建立了定期同步机制来保证不会积累太大的版本差。
预防层回答的是「你从一开始就考虑了这个问题」。
第二层是检测层:说明你如何检测兼容性问题——CI流水线里包含多版本兼容性测试,在上游发版后自动触发回归验证,用自动化手段而不是人工巡检来发现兼容性问题。检测层回答的是「你有一个系统来提前发现问题」。
第三层是修复层:说明当兼容性问题出现时你如何处理——优先用最小化影响的cherry-pick而不是全量merge,核心逻辑用接口抽象层隔离上游API依赖,必要时回退到patch抽取重新应用。
修复层回答的是「你知道问题出现后怎么收场」。
三层都答到的候选人,说明他对fork管理的理解不只是「会用git fetch upstream」,而是有一套完整的生命周期视角。这种视角是面试官真正在筛的。

三层都答到,这位候选人是真干过的
5.2 高频追问二:「你魔改过哪些框架,改了什么,为什么?」
这道题是经典的STAR法则(Situation-Task-Action-Result)考察题,但二次魔改场景下有一个额外的筛选维度:你的回答能否体现出「我的魔改是有边界的」,而不是「我fork了一个框架然后改了一堆东西」。
STAR法则的标准用法在这里仍然有效,但每个环节的侧重点需要调整。
Situation里要说明白「上游哪个版本、哪个具体的限制或bug触发了我要做魔改」,不能只说「因为业务需要」——面试官想看到你对上游框架的限制有过具体观察,而不是一个模糊的需求描述。
Task要聚焦在「我需要解决什么问题,这个问题为什么必须通过魔改而不是其他方式解决」。
这里要给一个排除性推理——为什么不能等上游修复、为什么不能换框架、为什么不能在上游提issue等待官方支持。三个替代方案的排除才让魔改的必要性站得住。
Action要讲清楚「我的魔改涉及哪几个文件、改了什么逻辑、怎么保证不引入新问题」。具体到文件名、方法名和改动思路,不要只说「我优化了核心模块」——这种泛泛而谈的回答说明你没有真正动手做过。
Result部分有两个必答题:魔改上线后的效果如何,以及这个魔改在后来跟随上游升级时是否遇到了兼容性问题。
第一个问题回答的是「你的魔改解决了问题」,第二个问题回答的是「你的魔改没有制造新问题」。两个答案都具体,面试官才会相信你的魔改是经过工程化管理的,不是野路子。
一个常见的失分点是:候选人会花大量篇幅描述自己魔改了多少东西,但当面试官追问「这个魔改后来有没有跟随上游升级」时,答案往往是「没有,因为升级成本太高了」或者「后来就没管了」。
这个答案直接暴露了一个事实:你的fork管理没有闭环。魔改不是终点,升级和归档才是。
5.3 高频追问三:「如果上游发布了Breaking Change你怎么办?」
这道题是压力测试题,考察的是你在「情况变坏」时的工程判断力和决策路径。
Breaking Change是二次魔改里最典型的风险场景,一个好的应答要展示的不是「我会随机应变」,而是「我有一套事先想好的应对方案」。
Breaking Change的处理分为四个步骤,每个步骤对应一个决策判断。
第一步是影响范围评估。Breaking Change发布后,第一件事不是立刻动手迁移,而是评估你的fork里有多少代码会被这个变化影响。
具体做法是:先把上游的CHANGELOG和Breaking Changes说明过一遍,然后grep搜索你fork代码里涉及被修改API的所有调用点,统计影响文件数量和改动规模。
第二步是迁移策略选择。如果影响范围小(改动点集中在1到3个文件),可以考虑直接迁移,迁移后跑完整测试套件验证。
如果影响范围中等(4到10个文件),建议先把核心魔改逻辑抽取为独立的patch文件,用新上游版本新建一个干净的fork基准,先验证patch能否在新基准上应用,再决定是否值得迁移。
如果影响范围大(超过10个文件),这时候要做成本收益分析——迁移成本可能已经接近重新实现一个简化版fork的成本了。
第三步是灰度发布验证。即使迁移通过了本地测试,也不能直接全量上线。
正确的做法是:先在staging环境跑一轮完整的业务回归,验证时间至少覆盖一个完整的业务周期(比如如果你的系统有日报任务,就跑满一天)。灰度发布没有问题后,再逐步放量到生产环境。
第四步是回滚方案准备。任何涉及Breaking Change迁移的发布,都必须同时准备好回滚方案。回滚方案可能是保留旧版本fork的tag、或者准备好旧版本镜像的快速部署脚本。
准备回滚的时间成本通常只占迁移总时间的10%到15%,但它能在出问题的时候把损失从「线上故障」降到「回滚一次部署」。
面试回答这道题,最见功力的部分不是步骤本身——步骤任何一个用过Git的工程师都能说出来——而是每个步骤背后的判断标准:影响范围小中大的阈值是什么、什么时候选择迁移而不是重写、回滚方案的准备标准是什么。
这些判断标准才是区分「执行者」和「设计者」的关键。

Breaking Change发了三版,我的fork跟了三次
六、参考文献与延伸学习路径
官方文档与源码
LangGraph StateGraph Architecture langchain-ai.github.io
LangChain Agent Executor Evolution docs.langchain.com
Anthropic Claude Agent SDK Documentation docs.anthropic.com
OpenAI Agents SDK Tool Calling platform.openai.com
Microsoft Agent Framework GitHub Repository 1(https://github.com/microsoft/agent-framework)
工程实践与方法论
Conventional Commits Specification conventionalcommits.org
GitHub Actions Workflow Syntax docs.github.com
Beren Millidge, "Scaffolded LLMs as Natural Language Computers" (2023) [arXiv/博客引用]
AgentHarness: 让AI从聊天机器人变成真正的智能体 乔木博客
DeerFlow: Super-agent framework from ByteDance heise.dev
社区讨论与面试资源
牛客网 AI Agent终结者LangGraph讨论帖 nowcoder.com
AgentHarness学习之Harness Engineering 牛客网
蚂蚁集团智能体与大模型应用工程面试复盘 nowcoder.com
AI Engineering Field Guide System Design GitHub
延伸学习路径建议
如果你读完这篇专题还想继续深入,推荐按这个顺序推进:
第一阶段,先把本专题的工程实践落地:用Conventional Commits规范改造你现有fork的commit history,在GitHub Actions里配置一个多版本兼容性测试矩阵,把这篇里的三层测试结构跑起来。
这个阶段的目标是把「知道」变成「做到」。
第二阶段,进入LangGraph的源码层:去LangChain GitHub仓库里找到AgentExecutor到LangGraph的演进路径,理解StateGraph的设计取舍和状态管理机制。
这个阶段的目标是建立对框架内部设计的系统认知,而不是只会调API。
第三阶段,尝试贡献一个小型PR回上游:不需要是什么大feature,哪怕是一个文档修正、一个typo修复都行。
这个阶段的目标是体验开源协作的工作流,理解上游维护者的review视角,这会反过来提升你自己维护fork时的代码质量标准。
三个阶段走完,你对AI框架二次魔改的理解就从「会用」升级到了「会管」。这个跨越,才是工程竞争力的真正分水岭。

行了,我去把commit history重写一遍
附录A:fork管理速查命令清单
Fork创建与初始化
# 克隆上游仓库
git clone https://github.com/langchain-ai/langgraph.git
# 进入仓库目录
cd langgraph
# 添加上游远程仓库
git remote add upstream https://github.com/langchain-ai/langgraph.git
# 验证远程仓库配置
git remote -v
# 输出应该同时显示 origin(你的fork)和 upstream(上游)
同步策略操作
# 获取上游最新代码(不合并)
git fetch upstream
# 查看上游所有分支
git fetch --all
# 查看上游标签列表
git tag -r upstream
# 策略一:rebase同步(保持干净线性历史)
git checkout your-feature-branch
git rebase upstream/main
# 策略二:merge同步(保留完整历史,但有merge commit)
git checkout your-feature-branch
git merge upstream/main
# 策略三:cherry-pick精确移植
# 先找到需要移植的commit hash
git log upstream/main --oneline
# 然后cherry-pick指定commit
git cherry-pick <commit-hash>
Conflict处理
# 查看conflict文件列表
git diff --name-only --diff-filter=U
# 进入conflict解决界面
git mergetool
# 标记conflict已解决
git add <resolved-file>
# 完成rebase或merge
git rebase --continue
# 或
git merge --continue
# 中止rebase/merge回退到原始状态
git rebase --abort
# 或
git merge --abort
# 紧急回退:把当前未提交的改动保存为patch
git stash
# 或保存为一个独立的commit
# git add -A && git commit -m "emergency stash before sync"
版本锚定与追踪
# 在commit message里记录上游版本锚点
git commit -m "patch: fix StateGraph edge case
upstream-ref: langgraph@v0.2.8 #a3f5c12
reason: upstream bugfix needed for production stability"
# 查看两个版本之间的差异
git diff upstream/v0.2.0..upstream/v0.3.0 --stat
# 查看某个特定文件的版本历史
git log --follow -p upstream/main -- path/to/state.py
Fork归档与清理
# 查看所有分支
git branch -a
# 删除已合并的分支
git branch -d <branch-name>
# 强制删除未合并的分支
git branch -D <branch-name>
# 清理已失效的远程追踪分支
git fetch --prune
# 创建归档标签
git tag -a v1.2.3-maintenance -m "Maintenance fork based on langgraph@v0.2.8, archived 2026-04"
CI/CD集成
# .github/workflows/compatibility-test.yml
name: Multi-Version Compatibility Test
on:
schedule:
- cron: '0 2 * * 0' # 每周日凌晨2点执行
push:
branches: [main]
workflow_dispatch:
jobs:
test:
strategy:
matrix:
upstream-version: ['v0.2.6', 'v0.2.7', 'v0.2.8', 'v0.3.0']
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install dependencies
run: |
pip install langgraph==${{ matrix.upstream-version }}
pip install -e .
- name: Run test suite
run: |
pytest tests/ --tb=short -q
- name: Report results
if: always()
run: |
echo "Test results for langgraph==${{ matrix.upstream-version }}"
附录B:二次魔改决策流程图
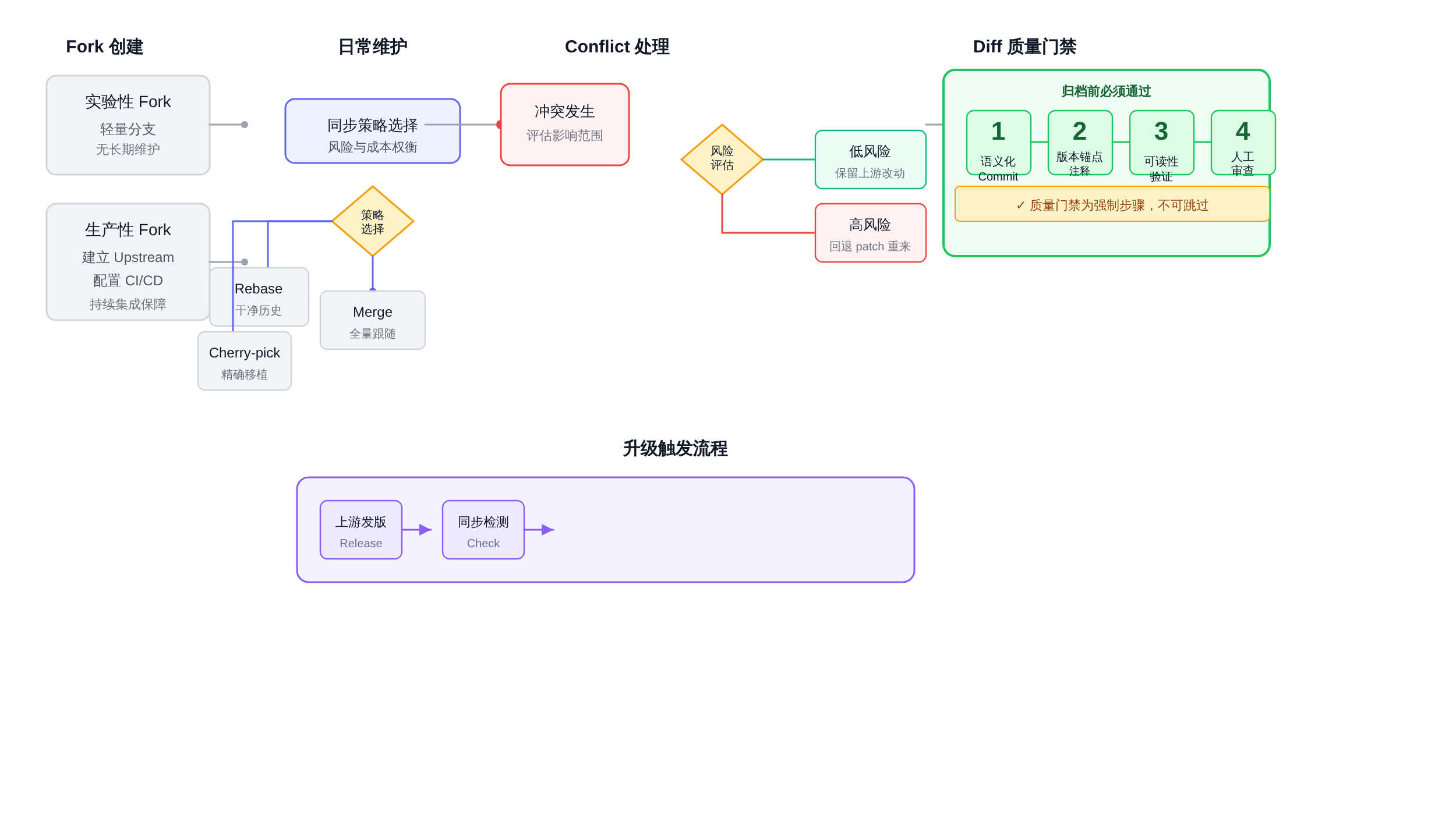
正文图解 1
决策流程说明:
第一步,从Fork创建节点分流:如果改动是一次性探索且预期存活周期小于两周,走实验性fork路径,直接fork使用,不建立任何维护基础设施;
如果改动需要存活两个月以上,或者项目已经进入排期而非探索阶段,必须走生产性fork路径——建立upstream remote、配置CI、补充测试。
第二步,日常维护节点根据同步需求分流:需要干净线性历史且分支未共享给团队其他成员时,用rebase;只需要上游特定修复不需全量同步时,用cherry-pick;
需要完整跟随上游大版本升级时,用merge配合squash。
第三步,conflict处理进入决策树:低风险conflict(集中在上游新增文件)保留上游版本,高风险conflict(集中在魔改核心文件)评估范围,如果文件数超过10个,回退到patch抽取重来的方案。
第四步,diff质量门禁在归档前必须依次通过:commit是否语义化(每条commit对应一个完整改动)、版本锚点注释是否完整、diff可读性是否达到review标准。
任意一项未通过,不归档,继续整理。

流程图我画好了,谁来填后面的内容


