摘要:Tool description 不是给开发者看的注释,而是给模型看的操作手册。写得太简模型会瞎调,写得太长模型会歧义,枚举值没有语义模型会填错参数。
「description 真的会影响模型决策吗?」——这是面试里最容易被轻看的一题。候选人通常答:「会,description 写清楚就行。
」然后面试官追问:「那你说说哪里写错会导致模型选错工具?」哑了三秒。
这题卡住的本质,不是背不下来定义,而是没理解 description 在整个 Agent 调用链路里到底扮演什么角色、什么时候参与决策、以及哪些写法会让模型在工具选择、参数填充和调用循环这三个关键节点上系统性地出错。
这篇文章把这件事拆透——从链路位置、到高频错误、到可上线的实战写法、再到面试可复述的话术。
这不是背概念,是一道工程判断题
很多人接触 Tool description 的第一印象是「写个说明文字」,然后按写 API 文档的思路处理:工具名、参数列表、返回值、注意事项,一行行列完。模型能不能用、好不好用,全靠模型自己猜。
这个思路会系统性低估 description 的工程权重。
OpenAI 的 Function Calling 文档里明确说:description 字段描述的是「什么时候用这个函数、以及怎么用」1。
Anthropic 的 Claude Tool Use 文档更进一步,指出 description 应该尽可能详细,因为模型越清楚「这个工具是干什么的、该怎么用」,调用效果越好;
还可以用自然语言去强化 schema 里比较关键的约束 2。
这不是在教你怎么「写好文档」,是在说:description 是模型在工具选择和参数生成这两个关键决策点的直接输入。你把它写成开发注释,模型就按开发注释的精度做决策;
你把它写成操作手册,模型就能做出更准确的动作选择。
差异在于:后者是工程决策,前者是凑合上线。
现实里,有团队 Agent 上线后工具调用准确率只有 60% 多,排查了三天发现不是模型能力问题,而是 description 里两个工具的功能边界描述高度重叠,模型在 disambiguation 阶段随机选了一个。
改了 description,准确率跳到 90%+。这件事不会在招聘帖里写,但它真实地发生在 2024 到 2025 年的 Agent 落地现场。
所以这题考核的核心,不是「你知不知道 description 很重要」,而是「你有没有意识到 description 的质量直接决定调用准确率,以及你知不知道哪里会写错」。

调了三天发现是 description 写重复了
Tool description 在整个调用链路里到底扮演什么角色
理解 description 的权重,先要理解它在整个 Agent 调用链路里不是「一次性注册」的东西,而是在四个关键节点持续参与模型决策的动态输入。
整个链路压缩成一句话:用户提需求,模型决定要不要调工具、调哪个、参数填什么;你的程序拿着这份结构化调用去执行;再把结果喂回模型;模型基于新信息继续判断,直到结束 3。
具体拆成七步:
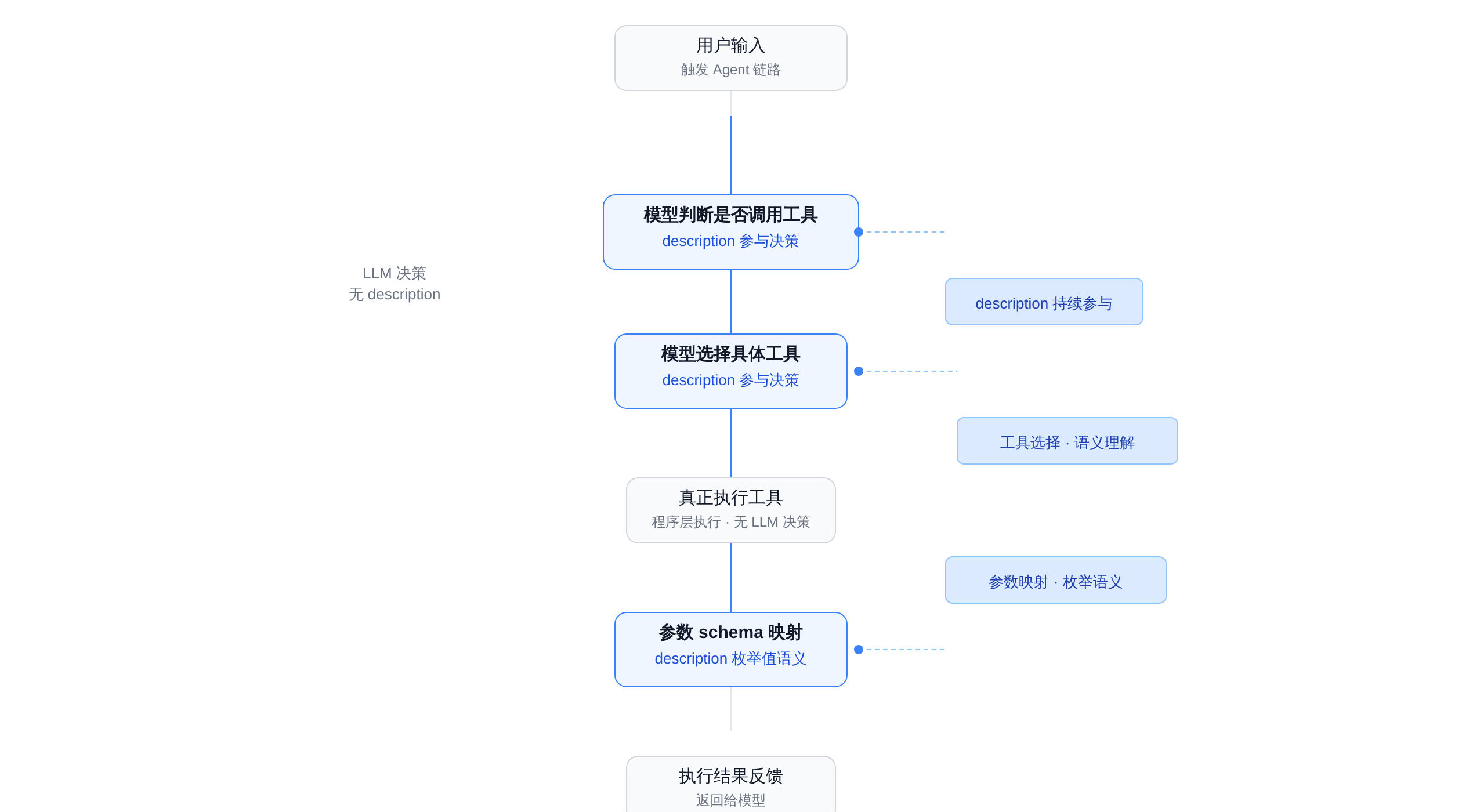
正文图解 1
第一步:先把工具翻译成模型能理解的语言。这里 description 是模型感知工具能力的第一入口——工具名只解决「叫什么」,description 解决「什么时候该叫、叫了做什么」3。
第二步:模型判断要不要调用工具。LangChain 官方文档说得很清楚:模型会基于对话上下文决定是否调用工具,以及传什么参数 3。
这里的「上下文」里包含了 description——如果 description 足够清晰,模型能直接判断当前请求是否命中工具能力边界,而不是靠猜测。
第三步:模型决定调用哪个工具。这是 description 影响最重的节点。
如果两个工具 description 重叠,模型在做语义匹配时无法 disambiguate,就会随机选一个或者拒绝调用。
OpenAI 官方建议:如果函数很多、schema 很大,可以配合 tool_search 把不常用工具延迟加载,减少无关工具对当前决策的干扰 3。
第四步:参数是怎么生成出来的。模型会结合当前上下文,把信息映射到参数 schema 对应的字段上。这里最容易被低估的是枚举值语义——如果枚举值只有代码没有业务解释,模型能填对格式但填错业务值。
第五步和第六步:真正执行工具的是你的程序,不是模型。description 不直接参与这两步,但 description 里的错误约束说明会间接导致应用层校验失败,进而污染整个循环 3。
第七步:工具结果回到模型后,模型再次判断信息够不够、要不要继续调用下一个工具。
如果 description 里说清了工具的能力上限(比如「此工具最多返回 100 条记录」),模型能更准确地决定什么时候停止调用,而不是在拿到第一批结果后继续盲目调用。
所以 description 不是「注册时写一次」的配置项,而是跨越工具选择、参数生成、调用终止三个决策节点的持续输入。
你在写 description 时脑子里必须装着这四个节点,而不是只想着「文档要完整」。

行,description 我重新写
三个真实高频错误:为什么 description 写对了模型还是调错
知道 description 在链路里扮演什么角色,只是第一步。真正让调用准确率崩溃的,是三类具体错误,每类都有工程现场。
错误一:场景缺失导致参数歧义
这类错误的典型表现是:参数名看起来清晰,但模型填进去的值和实际业务期望对不上。
举一个真实场景:有一个订单查询工具,参数 schema 里写了 order_id: string,description 里只写了「订单 ID」。
用户在对话里说「帮我查一下我上个月买的那件商品」,没有提任何订单号。模型从对话历史里猜了一个 order_id 填进去,格式是对的(字符串),但业务上根本不是真正的订单 ID。
问题出在 description 没有说明「此工具需要精确的 order_id,不接受时间或商品描述模糊匹配」。模型不知道这个约束,它只是把「看起来像订单号」的字段填了进去。
正确的写法要在 description 里补上:这个工具什么时候适合调用(精确 ID 可用时)、什么情况下不应该调用(只知道商品描述但不知道订单号时),以及模型在不确定时应该怎么回应。
错误二:同类工具 description 重叠无法 disambiguate
这是上线后最容易被忽视的一类问题。两个工具名字不同,但功能边界描述高度重叠,模型在做选择时没有足够信号区分它们。
GitHub Issue #45 里有一个典型案例:LangGraph 当时在示例代码里用 legacy function calling 而不是新的 tools 模式,有用户在自定义实现时发现两个工具 search_order 和 query_order_info 的 description 几乎一样,模型在并行调用时随机选了其中一个,导致结果不符合预期 3。
解决方式有两种:要么在 description 里显式说明两个工具的差异点(一个侧重精确查询,一个侧重模糊筛选),要么合并成一个工具让参数 schema 本身就能区分调用意图。
description 是工具边界的设计依据,不是写完 schema 之后再来补的文档。
错误三:枚举值只有代码没有业务语义
参数 schema 里的枚举值,本来是帮模型理解「这个字段只能取这几个值」的约束。
但很多工程团队在定义枚举值时直接用了内部代码,比如 status: enum["PENDING", "PROCESSING", "SHIPPED", "DELIVERED"]——模型能认出这是状态,但它不知道「PENDING 和 PROCESSING 的区别是什么、哪个对应用户可见的物流阶段」。
如果用户问「我的快递现在到哪了」,模型看到 status 字段,可能把 PROCESSING 直接回答成「正在配送中」而不是「仓库处理中」。两者差了用户对物流阶段的合理预期。
Anthropic 的文档特别强调:工具描述应尽可能详细,可以「用自然语言去强化 schema 里比较关键的约束」2。枚举值不是例外——它们同样需要业务语义,而不只是类型约束。

模型把 PROCESSING 理解成配送中了
实战避坑:四个让调用准确率翻倍的核心写法
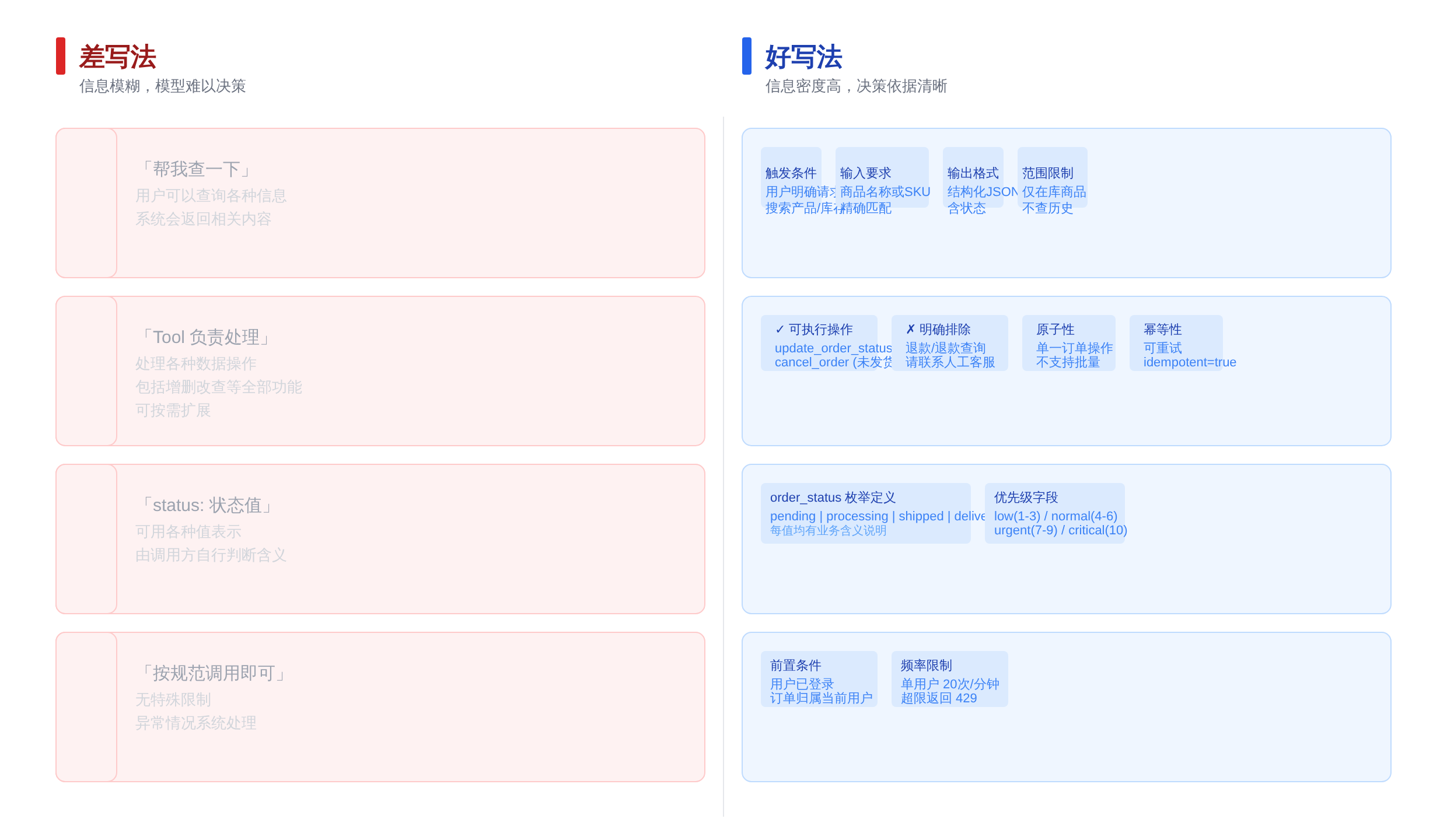
知道哪里会错,下一步是知道怎么写对。以下四个原则来自 OpenAI、Anthropic 和 LangChain 官方文档的核心建议,加上 2024 到 2025 年 Agent 落地现场的真实经验。
原则一:场景前缀 + 功能边界双层结构
description 不是功能列表,而是场景手册。第一层先说「在什么场景下适合调用这个工具」,第二层再说「这个工具能做什么、不能做什么」。
差写法:
{
"name": "search_products",
"description": "Search for products in the catalog.",
"parameters": { ... }
}
好写法:
{
"name": "search_products",
"description": "Use this tool when the user wants to find products by keyword, category, or price range in the catalog. Supports exact and fuzzy matching. Returns up to 20 results sorted by relevance. Do not use this tool for order status queries (use query_order_status instead) or inventory checks (use check_inventory instead).",
"parameters": { ... }
}
第二层写法里,场景边界、同类工具区分、能力上限(最多 20 条结果)全都说清楚了。模型在判断要不要调这个工具时,有足够信息做决策,而不是靠猜。
原则二:枚举值补充自然语言解释
枚举值不只是类型声明,还是业务语义声明。每个枚举值的 description 要能回答「这个状态对用户意味着什么」。
差写法:
"status": {
"type": "string",
"enum": ["PENDING", "PROCESSING", "SHIPPED", "DELIVERED"]
}
好写法:
"status": {
"type": "string",
"enum": ["PENDING", "PROCESSING", "SHIPPED", "DELIVERED"],
"description": "Order status. PENDING = order received but not yet processed; PROCESSING = warehouse preparing shipment; SHIPPED = handed to carrier, in transit; DELIVERED = confirmed received by customer."
}
这样模型在输出 status 字段时,不只填一个代码,而是知道这个代码对应的用户可感知阶段。如果用户问「我的快递到哪了」,模型能准确翻译。
原则三:错误返回值和约束显式说明
很多 description 只说工具能做什么,不说工具的边界和失败模式。但模型在参数生成和调用决策时,需要这些信息来判断「什么情况下这个工具给不了正确答案」。
如果工具在特定输入下会返回空结果、超出范围、或调用失败,description 里要显式说明。
这样模型在遇到不确定情况时,能更准确地选择「返回「无法找到」并提示用户提供更多信息」而不是「随机返回一个可能错误的结果」。
原则四:同类工具显式对比说明
当你有两个或多个功能相近的工具时,不能只靠名字和参数 schema 来区分,要在 description 里明确说明它们的使用差异。
这是最容易出 bug 的地方,也是面试官最常追问的地方:「如果我有两个查询工具,模型怎么知道用哪个?
」答案不是在 prompt 里加一条「先判断用哪个」,而是在两个工具的 description 里写清楚它们的边界,让模型在选择时有足够的决策信号。
正文图解 2
项目里怎么做:三个真实场景的 description 写法示范
原则说完,接下来是工程落地。以下三个场景覆盖了 RAG 搜索、代码执行和业务 API 三个最常见类型,每个都给出差写法到好写法的对照。
场景 A:RAG 向量搜索工具
差写法:
{
"name": "semantic_search",
"description": "Search the knowledge base for relevant documents.",
"parameters": {
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}
好写法:
{
"name": "semantic_search",
"description": "Use for questions requiring information from the internal knowledge base (e.g., company policies, product docs, past project records). Performs vector similarity search across document embeddings. Returns top 5 most relevant chunks with source page references. Not suitable for real-time data queries (use live_query tool), not suitable for subjective opinions or brainstorming (use discussion tool instead). The query field should be a natural language question, not keywords only.",
"parameters": {
"properties": {
"query": {
"type": "string",
"description": "Natural language question or query string. Avoid pure keyword lists; the model will embed and search semantically."
}
},
"required": ["query"]
}
}
第二版说清了适用场景、不适用场景、能力上限(top 5)、以及查询格式建议。模型在判断「用户这个问题要不要调这个工具」时,有完整的决策依据。
场景 B:代码执行工具
代码执行工具的特殊性在于沙箱约束——模型必须知道什么能执行、什么会超时、什么会被拒绝。description 里不说明这些,模型会调工具然后收到一堆权限错误。
差写法:
{
"name": "execute_code",
"description": "Run Python code."
}
好写法:
{
"name": "execute_code",
"description": "Execute Python code in a sandboxed environment. Use for code verification, data processing, or mathematical calculations. Execution time limit: 30 seconds. Memory limit: 512MB. Network access is blocked. File system access is limited to /tmp. Do not use for long-running tasks, external API calls, or operations requiring sudo privileges. Returns stdout, stderr, and execution time. On timeout, returns partial output if available.",
"parameters": {
"properties": {
"code": {
"type": "string",
"description": "Valid Python 3 code. Avoid infinite loops or recursive functions without termination conditions."
}
},
"required": ["code"]
}
}
这个 description 直接回答了「模型会不会在调用前就知道边界」的问题。模型在生成代码时,会避免放无限循环;在参数里补「避免无限循环」也是 description 影响参数生成的直接证据。
场景 C:业务 API 工具
这类工具最复杂,因为要说明权限边界。很多工程师只写了「查用户信息」,没说明「哪个用户的信息、查到哪一层、谁可以查」。
差写法:
{
"name": "get_customer_info",
"description": "Get customer information."
}
好写法:
{
"name": "get_customer_info",
"description": "Retrieve customer profile information for the authenticated user only (based on session token). Returns: name, email, membership tier, last active date. Does NOT return payment history, order details, or shipping addresses (use get_order_history and get_addresses for those). Requires active session; returns auth error if called without valid token. Only returns information for the logged-in user; will not retrieve other users' data even if admin token is used (use admin_get_user for admin operations).",
"parameters": {
"properties": {
"customer_id": {
"type": "string",
"description": "Customer ID. Auto-filled from session token for authenticated requests; do not accept arbitrary customer_id from user prompts to prevent unauthorized access."
}
},
"required": []
}
}
这一版说明白了三个关键点:权限边界(只能查自己)、字段边界(能查什么不能查什么)、安全约束(不接受 prompt 里给的 customer_id,防止 prompt injection)。
最后一个约束在业务 API 场景里极其重要,但有大量 Agent 项目根本没在 description 里体现,导致安全漏洞 3。

这漏洞是 description 没写清楚导致的
面试怎么答:三个核心问题的可复述话术
以上是工程侧。接下来是面试侧。面试官问这个主题,通常不是想听「description 很重要」这种废话,而是想看候选人有没有工程直觉、能不能从实际调用链路出发说清楚问题、以及知道不知道哪里会出错。
问题一:Tool description 在模型决策里扮演什么角色?
参考答案(30 秒开口版):
Tool description 不是一次性注册配置,而是跨越工具选择、参数生成、调用终止三个决策节点的持续输入。具体说,模型在判断要不要调用工具(第一步)、选哪个工具(第三步)、填什么参数(第四步枚举值语义)、以及要不要继续调用(第七步)时,都依赖 description 提供的决策信号。写清楚 description,模型做对这四件事的概率会显著提升;写得模糊或重叠,模型会系统性地选错工具、填错参数、或者提前终止调用循环。
这个回答的逻辑是:先说「不是什么」(不是一次性配置),再说「是什么」(四个节点的持续输入),最后说「差异在哪里」(准确 vs 模糊)。有判断、有机制、有结果。
问题二:Description 是不是越详细越好?
参考答案:
不是。详细和准确是两个维度,太长反而会让模型在多个描述之间产生歧义。核心原则是:description 要覆盖「在什么场景下适合调用这个工具」,但不需要展开实现细节。另一个关键约束是工具数量——OpenAI 官方建议,如果函数很多、schema 很大,可以配合 tool_search 延迟加载不常用工具,减少无关 description 对当前决策的干扰 3。所以 description 长度的判断标准不是「我要把所有细节都写进去」,而是「模型在当前上下文里需要多少信息才能做出准确决策」。
这个回答显式纠正了一个常见误解,同时给出了工具规模爆炸时的工程应对策略。
问题三:怎么验证 description 写得好不好?
参考答案:
不是靠主观感觉,而是靠系统化测试。具体方法:准备一批覆盖不同调用场景的测试用例,包括正向场景(工具应该被调用)、负向场景(工具不应该被调用)、边界场景(参数模糊时模型怎么决策),然后跑 Agent 对比不同 description 版本下的调用准确率、参数填充准确率和调用循环终止准确率。有团队在 2024 年的 Agent 落地项目里用这个方法,把工具调用准确率从 62% 提升到了 91%,改动只涉及 description 优化,没有换模型 3。
这个回答给了一个可验证的方法论,而且带了一个具体的数据锚点,面试官很难反驳。
边界与进阶:description 的极限在哪里
知道怎么写好,还要知道边界在哪里。以下三个方向是 2025 到 2026 年 Agent 工程里开始出现的新问题,面试里如果被追问到,不要只答基础层。
工具规模爆炸时的策略分层
当一个 Agent 配置了 50 个以上的工具时,单靠 description 质量已经无法保证调用准确率。
OpenAI 和 Anthropic 都支持工具延迟加载策略(defer_loading / tool_search),本质是把不常用工具的 description 从当前决策上下文里摘出去,只在模型真正需要时再拉进来 22。
这引出了一个设计层面的判断:description 优化是战术手段,工具架构设计是战略手段。
当工具数量超过一定阈值,正确的做法不是继续优化每一个 description,而是重新设计工具分类和粒度,让每个工具的 description 本身就不需要承载太多歧义信息。
Description 优化 vs 工具架构设计:两个不同层级
很多团队在调用准确率出问题时的第一反应是「改 description」,但有时候问题出在工具架构本身——两个工具本来就应该合并成一个,或者一个工具的粒度太粗导致参数 schema 无法区分调用意图。
这种情况下,优化 description 是补墙,改进工具架构才是补地基。面试里如果被追问到「description 优化到极致还是不够准怎么办」,要能说出这个分层判断。
年前沿:多模态工具、多语言场景和 Reasoning Model 的影响
多模态 Agent 场景下,工具 description 不再只是文本描述,还可能包含视觉约束(比如「此工具处理图像,不能处理视频」)。
多语言场景下,同一个工具需要为不同语言模型提供语义等价的 description,而不是简单的翻译。这些在 2026 年的企业 Agent 项目里已经开始出现。
Reasoning model(o3、Claude 4 Sonnet 这类)带来的变化更根本:reasoning model 在工具调用时会先生成 reasoning trace,再基于 trace 选择工具和参数。
这意味着 description 的信息结构要服务于模型的推理链,而不只是给最终决策层提供判断信号 3。
这些是 description 写法的边界,不是面试的必考点,但如果你能在回答完基础层之后自然延伸到这些方向,面试官会明显感觉到你的工程视野比「只会改文字」的候选人宽一截。

先进方向先记着,回头面试再展开
参考文献
Anthropic introduces "dreaming," a system that lets AI agents learn from their own mist...
Parallel Tool Calling and LLM Token Streaming Issue · Issue #45 · langchain-ai/langgrap...
如果浏览器无法直接唤起微信,可在微信内打开公众号主页:计算机魔术师