摘要:Parallel Tool Call 是 AI Agent 面试的高频丢分点,候选人往往只背过概念,却答不出「触发条件 → 并行执行 → 结果回注」三阶段的内部机制。
面试官问「你们 Agent 里工具调用是怎么并行的」,你张口就来「调用多个工具提升效率」,然后就没有然后了。
这不是个例。
在过去一年整理的 40+ 场 AI Agent 面试复盘里,Parallel Tool Call 相关问题的平均追问深度是所有 Function Calling 子题里最深的——候选人往往死在第三个追问:「那如果两个工具之间有依赖关系,你怎么处理?」
本文专注把一件事打透:Parallel Tool Call 的触发条件、并行执行的状态机建模、以及结果回注的上下文合并机制。
读完你能直接开口讲清三阶段,有项目经验的同学还能顺带学会怎么把这段经历讲出工程深度。
为什么 Parallel Tool Call 是面试高频丢分点
先说一个反直觉的事实:Parallel Tool Call 本身不是难点。
主流 LLM API(OpenAI、Google、Anthropic)都已经原生支持在一次模型输出里返回多个 Tool Call,开发者只需要把结果批量送回上下文就完成了。
从工程实现角度看,这段代码甚至可以用三十行写完。
那为什么面试官还反复问?
因为这个机制暴露了候选人两个关键能力边界。
第一,你是否理解模型「决定并行」的内部条件。不是所有 Tool Call 场景都会并行——模型需要判断这几个调用之间没有数据依赖,且都可以独立完成,才会生成并行调用序列。
如果候选人对这个触发条件说不清楚,说明他只用过 API,没有真正思考过 Agent 的决策层是怎么工作的。
第二,并行之后的「结果合并」才是真正的工程难点。假设模型一次发出了三个并行 Tool Call,分别查数据库、调用外部 API、写缓存——这三个结果回到上下文时,顺序怎么保持?
某个工具超时了怎么办?结果合并的格式不统一怎么处理?
没有踩过这些坑的候选人,会把并行 Tool Call 当成一个「LLM 自己搞定」的黑盒;踩过坑的工程师才知道这背后是一整套状态管理和错误恢复的设计。

三个工具回来结果顺序全乱了,上下文直接炸掉
面试官问这个,本质上是在探测你写没写过真正的 Agent Runtime,而不只是调过几次 invoke 接口。
什么是 Parallel Tool Call:触发、并行与回注三阶段模型
把整个机制拆成三阶段,理解起来就清晰多了。
触发阶段:模型什么时候决定并行
不是所有对话都会触发并行 Tool Call。模型的并行决策取决于两个条件同时成立:
条件一:多个 Tool 定义同时在 Tool Choice 里。 当模型看到系统提示里注册了三个工具(search_db、call_api、write_cache),且用户问题涉及多个子目标时,模型的输出层有机会在一次 assistant 消息里生成多个 tool_call 对象。
条件二:这些调用之间没有数据依赖。 模型的 Tool Calling 输出本质上是一个 JSON 数组,每个对象包含 name(工具名)和 arguments(参数)。
如果第二个工具的 arguments 需要引用第一个工具的返回结果,模型通常会生成顺序调用而非并行调用。
用 OpenAI API 的响应结构举例,一次并行调用长这样:
# OpenAI Responses API 并行 Tool Call 响应示例
{
"id": "resp_abc123",
"model": "gpt-4o",
"choices": [{
"message": {
"role": "assistant",
"tool_calls": [
{
"id": "call_A1",
"type": "function",
"function": {
"name": "search_database",
"arguments": "{\"query\": \"Q1 revenue 2025\"}"
}
},
{
"id": "call_A2",
"type": "function",
"function": {
"name": "fetch_stock_price",
"arguments": "{\"symbol\": \"AAPL\"}"
}
}
]
}
}]
}
注意这里的 tool_calls 是一个数组,包含了两个独立的调用请求。这两个请求可以并行执行,因为 search_database 不需要 fetch_stock_price 的结果作为输入。
并行执行阶段:三个工具同时跑,状态怎么管
拿到这个 tool_calls 数组之后,工程侧要做的事情才是真正的硬骨头。
问题一:并发执行。 三个工具可以同时调用,但必须处理结果返回的时序问题。
最朴素的做法是 asyncio.gather(),把所有调用包装成协程一起跑——这是大多数 Python Agent Runtime 的选择。
问题二:超时与熔断。 三个工具里有一个跑了两分钟还没返回,其他两个已经回来了,怎么办?
实践中通常给每个工具调用设置独立的超时阈值(默认 30s 到 60s),超时后记录错误,继续等待其他结果,而不是让整个 Agent 卡死。
问题三:错误处理。 某个工具返回了 HTTP 500,或者数据库连接超时。这个错误结果怎么处理?
是塞一个错误消息进上下文让模型自己决定下一步,还是直接重试?这两条路的工程成本和使用场景完全不同。
LangGraph 的做法是把每个工具封装成节点(Node),用条件边(Conditional Edge)控制流转。
并行执行在这里对应「三个节点同时激活」的状态,理解这个建模方式对回答面试追问非常关键。
# LangGraph 中的并行 Tool Call 建模示意
from langgraph.graph import StateGraph
from langgraph.prebuilt import ToolNode
# 三个工具节点并行注册
tool_node = ToolNode([search_database, fetch_stock_price, write_cache])
# 构建图结构:LLM 决策节点 -> 并行工具节点 -> 结果聚合节点
graph = StateGraph(AgentState)
graph.add_node("llm_decision", llm_node)
graph.add_node("tools", tool_node)
graph.add_node("aggregate", aggregate_results_node)
# LLM 决定下一步是调用工具还是直接回答
graph.add_edge("llm_decision", "tools")
graph.add_conditional_edges(
"llm_decision",
tools_condition, # 检查 tool_calls 是否为空
)
这里的关键是 tools_condition——它检查 LLM 输出中是否存在 tool_calls。如果模型生成了并行调用,这个条件函数会返回 "tools",图就会同时激活对应的多个节点。

review 时被问「这个条件函数怎么写的」,当场愣住
回注阶段:结果怎么合并进上下文
并行执行完成后,三个结果(或者两个结果加一个超时错误)需要合并回模型上下文,这就是「结果回注」(Result Injection)。
合并策略常见两种:
策略二:并行收集后统一注入。 等所有结果都返回(或者超时截止),按请求 ID(call_id)一一对应组装成 ToolResult 消息,最后批量 append 到 messages。
这个方案更健壮,但需要额外维护一个请求 ID 到结果的映射表。
不管哪种策略,最终送进下一轮 LLM 调用的 messages 列表结构必须和单 Tool Call 场景完全一致——模型不应该感知到「这次是并行回来的」。
这就是为什么回注阶段本质上是序列化工作,它把并发执行的副作用抹平了。
并行调用的状态机建模:LangGraph 的节点与边怎么设计
理解了三个阶段之后,我们需要把视角切到面试官最容易追问的地方:LangGraph 里的状态机建模到底怎么画。
LangGraph 的核心抽象是「图」——节点是处理单元,边是状态流转。一个支持并行 Tool Call 的 Agent 状态机,至少包含以下四个状态:
State 1: idle — 初始状态,等待用户输入。
State 2: llm_deciding — LLM 处理消息,决定下一步动作。此时检查 tool_calls 是否为空:
为空 → 进入
responding状态,直接回复用户非空 → 检查调用之间是否有依赖
State 3: tools_parallel_executing — 并行执行阶段。三个工具节点同时激活,状态机在这里需要维护「哪些工具还在跑」的计数器。
全部返回 → results_aggregating;有超时 → 触发错误处理分支。
State 4: results_aggregating — 汇总结果,回注上下文,然后回到 llm_deciding 进入下一轮循环。
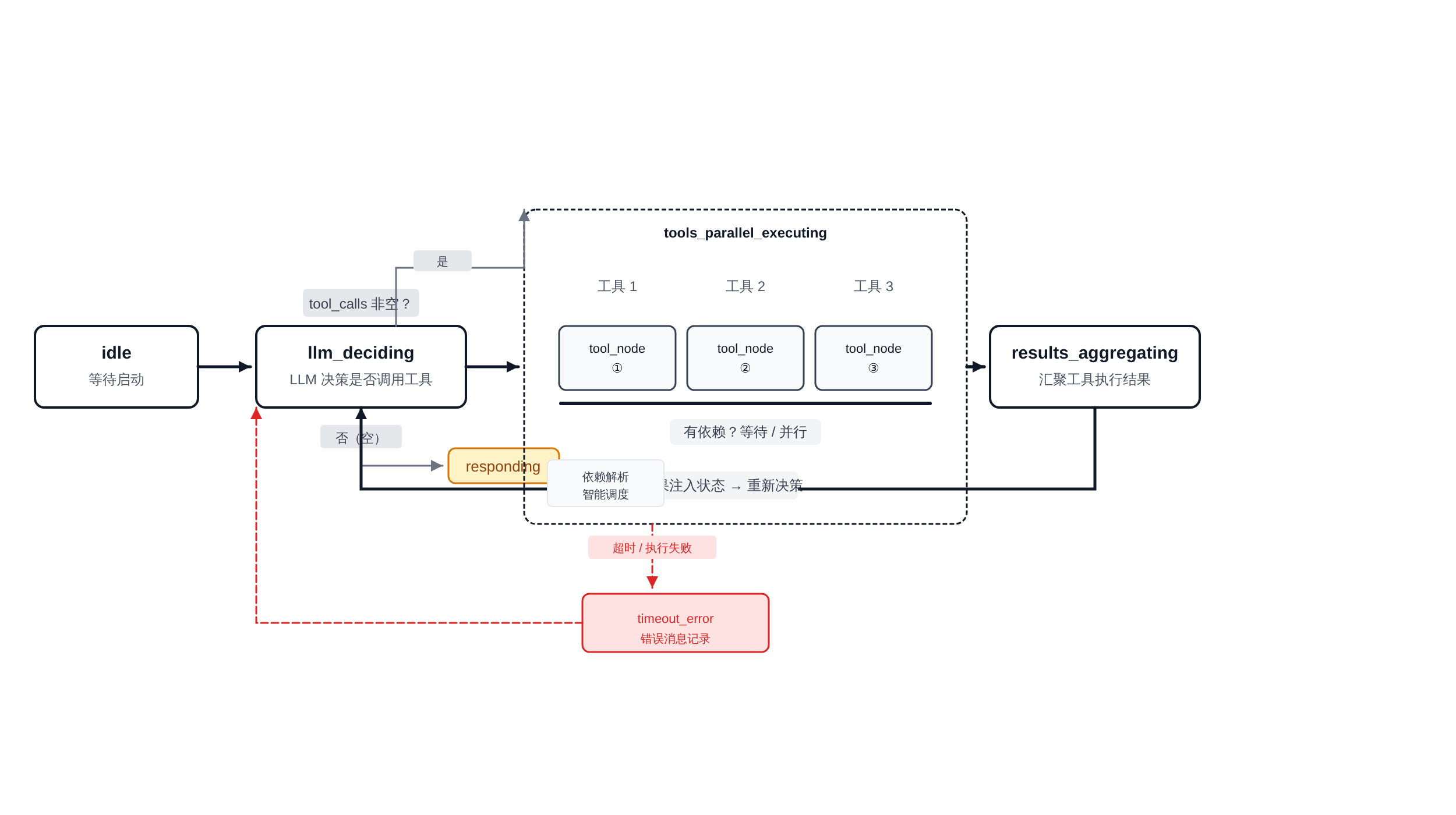
正文图解 1
这个状态机的工程意义在于:它把「并行」从「同时执行」提升到了「有管理的并发」。不是简单扔三个协程就跑,而是把超时、错误、聚合都纳入了状态流转。
如果候选人在项目里用 LangGraph 搭过 Agent,面试官几乎一定会顺着这张图追问实现细节。

PRD 里写「支持并行调用」,实际落地发现错误处理没想清楚
依赖链场景:并行 Tool Call 的约束条件
光讲「并行很美好」是不够的,面试官真正想卡住你的,是依赖链场景。
所谓依赖链,就是下一个工具的输入依赖上一个工具的输出。典型的例子:先查用户 ID,再拿 ID 查用户详情;或者先调用搜索 API,再用搜索结果里的 URL 抓取内容。
在依赖链场景下,模型不会生成并行 Tool Call——它会顺序生成两个 tool_call,第一个的 arguments 里没有第二个需要的数据,所以必须等第一个结果返回之后,才能构造第二个调用的参数。
工程上处理依赖链,有两种主流方案:
方案一:模型层自动处理。 依赖关系通过 Prompt 显式告诉模型:「如果需要用第一个工具的结果,再调用第二个工具」。
模型在收到第一个 Tool Result 后,会自动把结果注入下一个 tool_call 的 arguments 中。
这是最常见的做法,LangGraph 的 create_react_agent 默认就是这个模式。
方案二:工程层显式建模依赖图。 当工具数量多、依赖关系复杂时,靠模型的上下文推理不够可靠。
这时需要工程侧维护一个 DAG(有向无环图),显式定义每个工具的前置依赖,并按拓扑序执行。
OpenAI 在 2025 年底的 Function Calling 文档里已经明确支持在 Tool Call 响应里通过 parsing_instructions 注入依赖提示。
现实项目里,大多数场景用方案一就够了。但如果团队规模大、工具链路长,面试官会倾向于问「如果工具数量超过十个你怎么管依赖」——这个问题在 System Design 面里出现频率很高。
模板答案:30 秒开口版 + 展开版
面试现场最怕的是脑子里有一堆知识点,但开口就是散的。以下两个版本对标不同回答深度。
秒开口版(适合一面基础轮)
Parallel Tool Call 的机制分三阶段:触发、并行执行、结果回注。触发时,模型判断多个工具之间没有数据依赖,就在一次输出里生成多个
tool_call对象。工程侧拿到这个数组后,通过asyncio.gather()或 LangGraph 的并行节点同时调用这些工具,每个工具独立处理自己的超时和错误。最后把结果按调用 ID 一一对应,append 回 messages 列表,让模型感知到的是一次完整的上下文,而不是多次独立调用。
这段话在 30 秒内覆盖了全部三个阶段,没有技术术语堆砌,面试官可以直接接下一个追问。
展开版(适合二面深度轮或 System Design 面)
模型生成并行 Tool Call 的前提是工具之间没有数据依赖——如果有,模型会顺序生成两个调用,第一个结果作为第二个的输入参数。工程侧拿到并行
tool_calls数组后,我们用 LangGraph 把每个工具建模成独立节点,用条件边控制激活。并发执行时,每个节点独立计时,超时走错误处理分支,不影响其他节点。结果聚合有两种策略:严格按原始顺序合并,或者等全部返回后按 ID 对应组装。如果项目里工具数量超过十个,我会额外维护一个 DAG 来显式管理依赖关系,而不是完全依赖模型的上下文推理。
展开版多出来的部分对应了面试官在高年级面里追加的追问:依赖链怎么处理、DAG 怎么维护、错误恢复的策略是什么。
为什么面试官问这个:筛选逻辑与出题动机
Parallel Tool Call 这个问题,本质上在筛三层能力。
第一层:API 使用层。 你有没有用过 Function Calling、会不会调 tool_calls 参数、知道不知道并行和顺序调用的区别在哪。
这层问题比较基础,过不了这层的候选人,要么只调过 LangChain 的高层封装,要么根本没写过 Agent Runtime。
第二层:并发工程层。 你知不知道 tool_calls 返回后怎么管理并发执行、怎么处理超时和错误、结果合并的时候顺序怎么保。
这层开始拉开差距——没踩过坑的工程师会想当然地说「直接并发调就行了」,但真正的问题(时序错乱、超时不处理、上下文顺序错误)他一个都答不上来。
第三层:系统设计层。 当工具数量扩展到十几个、二十个,依赖关系怎么建模、并行度怎么控制、调用失败后的重试策略怎么定。
这层问题对应的是 Senior Engineer 或者 ML Engineer 的职位定位,面试官想看的是你有没有想过这个机制的Scalability。
大多数候选人在第一层就停了——这也是为什么 Parallel Tool Call 问题在 AI Agent 面试里丢分率居高不下。
常见追问与变体:从单 Tool 到多 Tool 的追问链
Parallel Tool Call 的追问链是可以预判的,掌握了规律就知道从哪里补。
追问一:「模型怎么决定并行还是顺序?」
这个问题考察的是你对模型 Tool Calling 决策机制的理解。
核心答案:模型在生成 Tool Call 之前会做一次内部评估——如果发现某个 tool_call 的 arguments 引用了另一个工具的输出(通过变量名或描述暗示),就判断有依赖,生成顺序调用;
反之则并行。
追问二:「超时怎么处理?」
超时处理有三种常见策略:直接抛异常重试(最多三次)、返回错误消息给模型让它决定下一步、设置全局超时取消所有仍在跑的请求。
没有标准答案,但面试官想听的是你有没有意识到这是一个需要设计的问题,而不是「让它跑着就行了」。
追问三:「三个工具返回结果格式不一样怎么合并?」
这是工程实现里最常见也最容易被忽视的问题。
常见做法是在回注前统一做 Schema 归一化:把所有结果转成 {tool_name, status, result, error} 的标准结构,再塞进 messages。
这保证了模型收到的上下文格式是统一的,不管原始返回是 JSON、字符串还是异常对象。
追问四:「如果有二十个工具你怎么设计依赖管理?」
对应系统设计层的追问。答案是 DAG + 拓扑排序。
每个工具声明自己的 dependencies 列表(工具名数组),执行引擎按拓扑序分组执行——同一层没有依赖的工具可以并行,不同层的工具必须等前置层全部完成。
LangGraph 的 create_react_agent 本身不原生支持 DAG 依赖,所以工程侧通常需要自己封装一个执行调度器。

二十个工具里有个隐式依赖,线上才发现工具 A 用了工具 C 还没返回的数据
易错点:高风险误答与概念混淆
以下三点是面试现场最容易翻车的地方,提前知道能救命。
误答一:「并行就是让模型一次调用所有工具。」
这句话在语义上没有大错,但暴露了你对「触发条件」和「回注机制」都不清楚。
模型并不是「一次调用所有工具」——它是「一次输出多个 Tool Call 指令」,这些指令还需要工程侧去实际执行、执行完再把结果合并回去。
混淆「模型输出并行指令」和「系统并行执行工具」,是面试里最常见的概念错误。
误答二:「并行 Tool Call 的结果顺序不重要。」
误答三:「用 Promise.all() 搞定并发就行了。」
Promise.all() 在 Node.js 环境里可以处理并发请求,但如果任何一个 Promise reject,整个数组就会 reject。
在实际的 Agent 场景里,某个工具超时或返回 500 错误是常态,不是异常——用 Promise.all() 会让你的整个 Agent 在单点故障面前毫无容错能力。
正确做法是逐个包装,每个调用独立捕获异常,统一收集结果后送回上下文。
项目里怎么说:没有完整 Agent 项目怎么补
如果你没有真实的 Agent 项目经验,这块是最难补的,但也有几条可以走的路。
路径一:LangGraph 官方教程项目。 LangGraph 文档里有完整的 ReAct Agent 教程,代码量不大(三百行左右),但覆盖了 Tool Calling、状态机、并行调用的核心机制。
你可以在这个基础上加一个自定义工具(比如接入天气 API),在 GitHub 上开源并写清楚你的修改思路。
面试时你可以指着这个项目说:「我在这里遇到的最大挑战是工具超时导致整个 Agent 卡死,解决方法是给每个工具单独设置 30 秒超时并统一处理错误结果。」
路径二:对比实验。 写一个脚本,分别测试单 Tool Call、顺序多 Tool Call、并行多 Tool Call 的耗时和 token 消耗,把数据整理成对比表格。
这个实验本身就能回答「并行调用到底快多少」这个问题,而且面试官一般都会顺着这个表格追问细节。
路径三:复现经典问题。 在 LangGraph 的 issue 区搜「Parallel Tool Call」,能找到不少真实 bug(比如 Tool Call 结果顺序错乱、超时后上下文丢失)。
你可以选一个 bug 做复现和修复,然后在简历上写:「复现并修复了 LangGraph 并行 Tool Call 场景下的结果顺序 bug(issue #45)。」这种写法比「参与过 Agent 开发」要具体十倍。
没有 Agent 项目不可怕,可怕的是简历上写了「了解 Function Calling」但连官方文档都没跑通过一遍。
参考文献与延伸阅读
GitHub - hunyadi/function_tool: Python wrapper for LLM function calling
GitHub - awesome-agent-harness: Agent harness engineering resources
AI Engineering Field Guide - System Design for AI Applications
GitHub - langchain-ai/langgraph: Issue #45 Parallel Tool Calling and LLM Token Streaming
参考文献
GitHub - hunyadi/function_tool: Python wrapper for LLM function calling
GitHub - awesome-agent-harness: Agent harness engineering resources
AI Engineering Field Guide - System Design for AI Applications
GitHub - langchain-ai/langgraph: Issue #45 Parallel Tool Calling and LLM Token Streaming

如果浏览器无法直接唤起微信,可在微信内打开公众号主页:计算机魔术师