摘要:tool_result 是 Agent Runtime 中连接工具执行与模型推理的关键消息节点,但其注入格式、历史消息中的插入位置、以及与 Anthropic API 的兼容性约束,长期是面试高频失分区。
某天下午,面试官抛出一个看似简单的问题:「你的 Agent 在调用工具后,tool_result 怎么注入到消息历史里的?」你张嘴就来:「直接 append 到 messages 数组里就行了。」然后你看到面试官把手指挪到了屏幕上,开始画框——那个框不是「回答得好」的框。
这是 tool_result 相关面试题最容易崩掉的时刻。不是你不懂工具调用,而是在消息序列的上下文里,tool_result 不只是一个返回值,它是一枚必须嵌在精确位置的拼图块。
嵌错了,Anthropic API 拒绝;嵌漏了,LangGraph 状态图断裂;嵌乱了,interrupt 恢复后消息序列彻底乱序。
这篇文章把 tool_result 的注入格式、历史消息结构、常见失败路径、LangGraph 源码视角和面试应答模板一起拆透。
从 tool_call 到 tool_result:消息结构里的两个锚点
理解 tool_result 之前,需要先看清楚它的前置节点——tool_call。
在 AI Agent 的消息序列里,一个完整的工具调用生命周期包含四个阶段:模型输出 tool_use 消息块 → SDK 解析工具名与参数 → 执行工具获得结果 → 将 tool_result 注入消息历史 → 模型继续推理。
这条链路里,tool_call 和 tool_result 是成对出现的两个锚点,中间夹着工具执行过程。
# 一个完整的工具调用消息序列简化示例
messages = [
# 1. 用户消息
{"role": "user", "content": "帮我查一下北京今天的天气"},
# 2. 模型输出 tool_use
{
"role": "assistant",
"content": "好的,我来查询天气。",
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"city\": \"北京\"}"
}
}
]
},
# 3. tool_result 必须紧邻 tool_call 之后注入
{
"role": "tool",
"tool_call_id": "call_abc123", # 必须精确匹配
"name": "get_weather",
"content": "{"temperature": "18°C", "condition": "晴"}"
}
]
这里有两个硬约束:第一,tool_result 的 tool_call_id 必须和前序 tool_use 中的 id 精确一致;
第二,tool_result 必须紧邻 tool_call 之后出现在消息序列中,中间不能插入其他消息。
这两个约束不是风格偏好,而是 Anthropic API 的硬性要求,违反任意一条都会触发 BadRequestError(详见 GitHub Issue #1423)。

这个错误我踩过,第2轮interrupt直接崩
tool_result 的标准注入格式与字段语义
content:返回值还是结构化对象
tool_result 的 content 字段可以承载两种形态:字符串形式的返回值,或者结构化的错误信息。
# 正常返回:字符串
{"role": "tool", "tool_call_id": "call_abc123", "content": "查询结果:18°C,晴"}
# 异常返回:is_error 标记 + 结构化对象
{
"role": "tool",
"tool_call_id": "call_abc123",
"content": json.dumps({"error": "API rate limit exceeded", "retry_after": 60})
}
标准做法是:如果工具正常返回,用字符串或 JSON 字符串填充 content;
如果工具执行出错,建议在 content 里放结构化错误信息,同时通过 is_error: true 向模型明确标记这是一个异常(Anthropic SDK 支持该字段)。
很多候选人面试时只说「把结果返回给模型」,但如果被追问「如果工具超时怎么办」「返回空结果时 content 怎么填」,就容易卡壳。工程实践中,超时场景的 tool_result 通常长这样:
{
"role": "tool",
"tool_call_id": "call_abc123",
"content": "{"error": "Request timeout after 30s", "tool": "get_weather"}",
"is_error": True
}
关键是让模型拿到足够的信息判断下一步行为,而不是丢给它一个无意义的空字符串。
tool_use_id:必须与前序 tool_call 精确对齐
这是 tool_result 最核心的字段,也是面试追问的高发区。
tool_call_id(在 OpenAI 兼容格式中)或 tool_use_id(在 Anthropic 格式中)必须和前序 assistant 消息中 tool_calls 数组里的对应条目 id 完全一致。
字符串层面的哪怕一个字符不匹配,API 就会拒绝请求。
# 错误示例:id 不匹配(常见于并发场景或手动拼接消息时)
{"role": "tool", "tool_call_id": "call_wrong456", ...} # 与前序 call_abc123 不一致
# 正确示例:精确对齐
{"role": "tool", "tool_call_id": "call_abc123", ...}
在 LangGraph 场景里,这个问题通常由框架自己处理,但如果你是手写 ToolNode 或者在并发场景下自己管理消息数组,就需要格外注意 ID 映射的一致性。

review 的时候才发现 tool_use_id 对不上
is_error 与 type:异常标记与 SDK 差异
Anthropic API 格式中支持 is_error 布尔字段,用来明确标记工具执行异常。这在模型决定是否重试或降级时非常重要。
但不同 SDK 对这个字段的支持程度不同:Anthropic Python SDK 的 ToolResult 支持 is_error 参数,而在 LangGraph 的 ToolMessage(基于 BaseMessage)中,这个字段需要通过 additional_kwargs 或自定义状态结构来传递。
如果你用 LangGraph 的 ToolNode,它会自动处理 tool_result 的生成,但如果你在自定义节点里手动构造消息,就需要自己维护这个字段。
历史消息结构:tool_result 必须嵌在哪个位置
插入位置规则:紧邻对应 tool_call
tool_result 不是「append 到消息列表末尾」,而是「紧嵌在对应 tool_call 之后」。这是面试里最容易被误解的一点。
当模型输出了一个包含 tool_calls 的 assistant 消息,下一条消息必须是对应 tool_call_id 的 tool_result,不能先插入其他 assistant 消息、用户消息或 system 消息。
这个规则的本质是:Anthropic API 要求消息序列中 tool_use 和 tool_result 必须相邻,中间没有其他内容块。
✅ 正确序列:
user → assistant(tool_calls) → tool → assistant(推理) → user
❌ 错误序列:
user → assistant(tool_calls) → assistant(另一条) → tool ← 违规
❌ 错误序列:
user → assistant(tool_calls) → user(另一条) → tool ← 违规
消息序列的连续性与 Anthropic API 硬约束
Anthropic API 对 tool_use/tool_result 配对有严格的顺序要求。2025 年底的某次 API 变更加强了对消息块顺序的验证,具体表现为:
BadRequestError: messages.0.content.2: unexpected
tool_use_idfound intool_resultblocks. Eachtool_resultblock must have a correspondingtool_useblock in the previous message.
这条错误信息的意思是:API 要求每个 tool_result 的 tool_use_id 必须在紧邻的前一条 assistant 消息的 tool_calls 数组里找到对应项。
如果你在 checkpoint 恢复场景中手动拼接消息,或者多轮 interrupt 后重新注入消息,就非常容易触发这个错误。
理解这个约束的关键是:Anthropic 的模型推理依赖消息序列的上下文连续性。
如果 tool_result 和 tool_call 之间出现了其他消息块,模型就失去了「工具执行 → 结果返回」的因果链推理上下文。
LangGraph State 中消息拼接的 reducer 策略
LangGraph 通过 Annotation.Root 定义状态时,通常把 messages 字段的 reducer 设为追加策略:
StateAnnotation = Annotation.Root({
"messages": Annotation({
reducer: (x, y) => x.concat(y), # 始终追加,不做去重或重排序
}),
# ...其他状态字段
})
这个设计很简洁,但有一个隐患:如果你在 interrupt 恢复时手动注入 tool_result,或者在多轮工具调用中重排序消息,reducer 的追加逻辑不会自动保证 tool_result 出现在正确位置。
LangGraph 的 ToolNode 会自动把 tool_result 追加到 messages 的末尾,但如果你在 post_tool_review 这类自定义节点里使用 Command({ resume: ... }) 恢复状态,就需要自己确保新注入的 HumanMessage 出现在 tool_result 之后、而不是之前。
常见失败路径:为什么 tool_result 总是在错误的时机出错
场景一:interrupt 恢复后消息序列被打乱
Human-in-the-loop 是 LangGraph 的核心能力之一。面试官喜欢追问这个场景,因为它暴露了消息管理中最复杂的问题。
完整的 interrupt 流程:agent 调用 tool → tool 执行 → interrupt() 暂停图执行 → 人工审核或输入 → Command({ resume: ... }) 恢复 → 消息序列重建 → 继续推理。
问题出在第 5 步:checkpoint 保存的消息序列包含 tool_call,但 Command({ resume: ... }) 注入的新消息会直接 append 到消息列表末尾。
如果你的图逻辑没有正确处理 tool_result 的位置,就会在恢复后出现「tool_result 出现在新注入消息之后」的情况,导致 Anthropic API 认为 tool_result 的 tool_use_id 和当前最新 assistant 消息没有配对关系。
这个问题在 GitHub Issue #1423 中被详细记录,影响版本从 LangGraph.js 0.3.10 到 0.3.24,Python 版本在多轮 interrupt 后也出现过类似现象。
核心解法是在 post_tool_review 节点里用 Command({ goto: "agent", update: { messages: [feedbackMsg] }) 把反馈消息注入到正确位置,而不是让默认 reducer 随意追加。

interrupt 恢复后第2轮直接 BadRequestError
场景二:并发 tool 调用导致 id 错配
当一个 assistant 消息包含多个 tool_calls(并发调用)时,消息序列会变成:
assistant(tool_calls: [call_A, call_B, call_C])
tool(call_A_result) ← 必须紧邻
tool(call_B_result) ← 必须紧邻
tool(call_C_result) ← 必须紧邻
这三个 tool_result 必须紧邻 tool_call 之后按顺序出现,而且每个 tool_call_id 必须和 tool_calls 数组里的对应项精确一致。
如果你在并发执行工具时用 Promise.all 或异步队列,并且消息数组的写入顺序不确定,就容易出现乱序。
实战中常见的坑是:工具 A 先执行完但写入了消息数组,工具 B 后执行完但写入时位置错误,导致 tool_result 顺序和 tool_calls 顺序不一致。这在高频工具调用场景下尤其容易出现。
场景三:多轮 interrupt 产生孤儿 tool_result
极端情况下,如果你在同一轮对话里连续触发多次 interrupt,每次 interrupt 都会向消息序列注入一个待处理的 tool_call,但没有及时注入对应的 tool_result。
多次 interrupt 后,消息序列里可能出现多个「只有 tool_call 没有 tool_result」的消息块。
LangGraph 的 checkpoint 机制会保存当前状态,但如果你的恢复逻辑没有正确识别和补全这些孤儿的 tool_result,重启后的消息序列就会缺少必要的返回节点,模型推理时就会缺少关键上下文。
场景四:SDK 间 tool_use_id 格式差异
OpenAI 兼容格式使用 tool_call_id,Anthropic 原生格式使用 tool_use_id。
如果你同时对接多个模型提供商,或者在迁移代码时没有注意字段名的差异,就会出现「消息格式对不上」的问题。
# OpenAI 兼容格式
{"role": "tool", "tool_call_id": "call_abc123", "content": "..."}
# Anthropic 格式(部分 SDK 变体)
{"role": "tool", "tool_use_id": "toolu_abc123", "content": "..."}
这个差异在 LangGraph 里通常由 ChatAnthropic 的 bind_tools 机制自动处理,但如果你的代码里直接手写了 tool_result 构造逻辑,就需要特别注意字段名的对应关系。
LangGraph 源码视角:tool_result 是怎么被写入状态图的
ToolNode 执行链路:tool_call → tool_result → State.messages
LangGraph 的 ToolNode 是整个 tool_result 注入链路的核心。以下是其执行链路的简化逻辑:
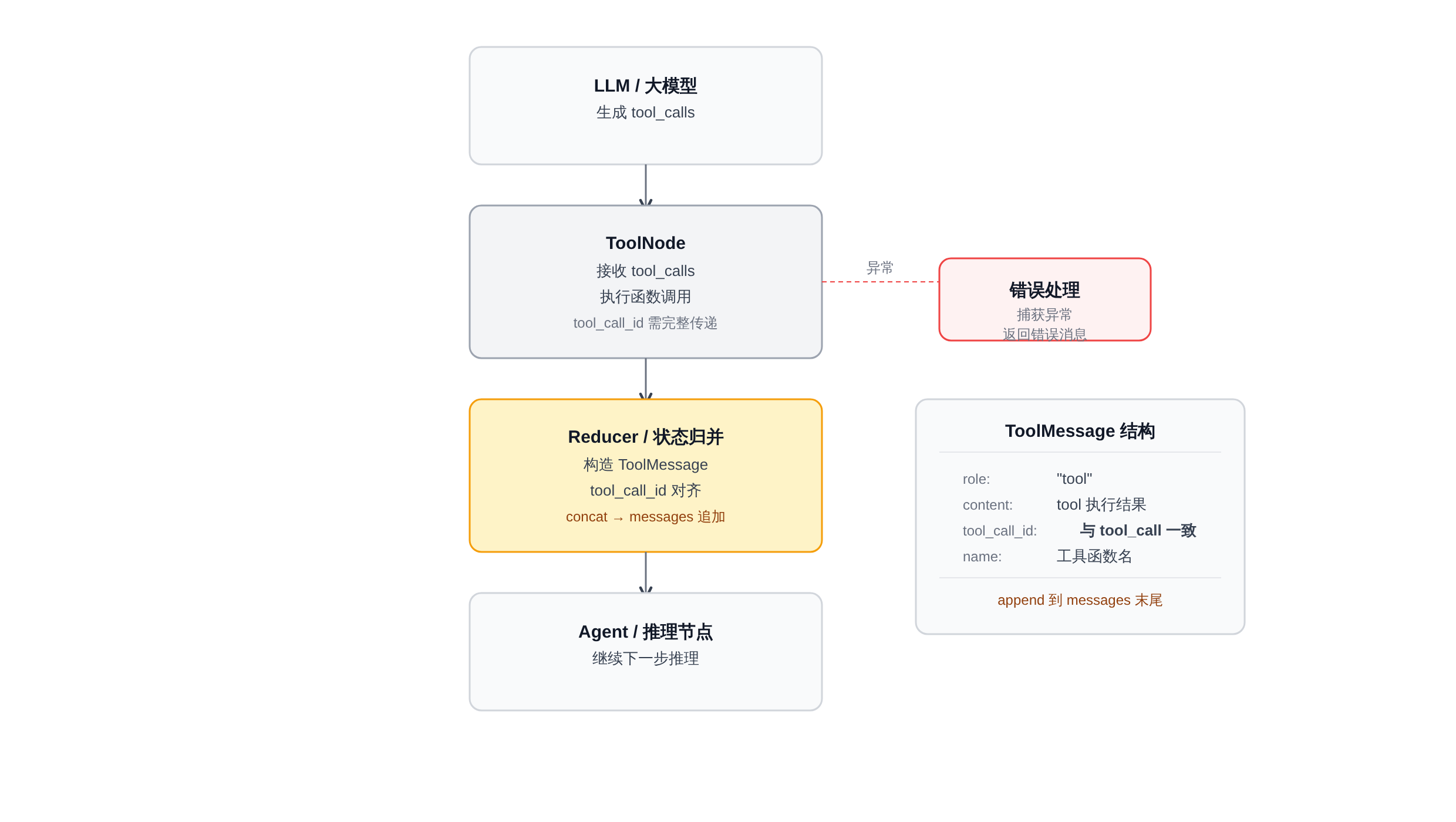
正文图解 1
ToolNode 的核心执行逻辑大约是这样的(基于 LangGraph 源码结构):
class ToolNode:
def __init__(self, tools: list[BaseTool]):
self.tools = {t.name: t for t in tools}
def __call__(self, state: State):
# 从最新 assistant 消息中提取 tool_calls
last_message = get_last_ai_message(state["messages"])
tool_calls = last_message.tool_calls
results = []
for tool_call in tool_calls:
# 根据 tool_call.id 查找并执行工具
tool = self.tools[tool_call.name]
result = tool.invoke(tool_call.arguments)
# 构造 ToolMessage,关键:tool_call_id 必须和 tool_call.id 一致
tool_message = ToolMessage(
content=str(result),
name=tool_call.name,
tool_call_id=tool_call.id # 精确对齐
)
results.append(tool_message)
# 返回结果,自动追加到 State.messages
return {"messages": results}
这里的关键是:tool_call 的 id 在 ToolNode 构造 ToolMessage 时被原封不动地复制为 tool_call_id。
如果你的工具名映射或参数解析出错了,这个 id 链就会断裂。
Checkpoint 与消息序列化:PostgresSaver 的坑
当使用 PostgresSaver 做 checkpoint 时,消息序列会被序列化成 JSON 存入 PostgreSQL。恢复时,LangGraph 从数据库读取序列化的消息并反序列化。
问题在于:PostgreSQL checkpointer 在处理包含 tool_use/tool_result 的消息序列时,可能在序列化/反序列化过程中丢失消息块的精确顺序,或者在多轮 interrupt 后对 tool_result 的位置判断出现偏差。
这在 GitHub Issue #1423 中被明确记录为一个已知兼容性问题。
实战建议:如果你的场景涉及高频 interrupt 且依赖 PostgreSQL checkpointer,需要在 post_tool_review 或等效节点里显式验证 tool_result 的位置是否正确,而不是完全信任 checkpoint 的自动恢复结果。
Human-in-the-loop 场景下的消息完整性保证
在完整的人机协作场景里,消息序列必须在 checkpoint 边界保持语义完整。具体来说:
checkpoint 前:消息序列中每个 tool_call 都必须有对应的 tool_result(或等效的 pending 标记)
resume 后:新注入的消息必须追加在 tool_result 之后,不能插入 tool_call 和 tool_result 之间
模型推理前:LangGraph 会把当前 messages 序列发给 LLM,如果 tool_result 缺失或顺序错误,推理就会失败
LangGraph 官方建议在 post_tool_review 节点使用 Command({ goto: "agent", update: { messages: [feedbackMsg] }}) 而不是简单返回,就是为了让反馈消息出现在正确的语义位置。
面试怎么回答:标准模板 + 追问防御
秒开口版
tool_result 是模型工具调用后的返回消息,它必须通过
tool_call_id和前序 assistant 消息中的 tool_use 精确配对,并且紧嵌在 tool_call 之后注入消息历史。Anthropic API 对这个顺序有硬约束,LangGraph 的 ToolNode 通过把 tool_call 的 id 原样复制到 tool_result 来维护这个配对关系。如果涉及 interrupt 恢复或多轮工具调用,需要特别处理消息位置,避免出现孤儿 tool_result 或乱序。
这个版本覆盖了核心逻辑、API 约束和框架实现,适合一面或二面快速自我介绍。
展开版:tool_result 在 Agent Runtime 中的角色
在多步 Agent 运行时,tool_result 不只是一个返回值,它是模型继续推理的关键上下文锚点。它的
tool_call_id必须和前序 tool_use 的id精确一致,这在并发工具调用时尤其重要——多个 tool_result 必须按 tool_calls 的顺序紧邻出现在消息序列里。
在 LangGraph 里,这个配对关系由 ToolNode 维护,它把 tool_call.id 直接复制为 tool_message.tool_call_id,然后通过状态 reducer 追加到 messages 列表。如果你的场景涉及 human-in-the-loop interrupt,checkpoint 恢复后需要确保新消息追加在 tool_result 之后,而不是随意插入。这是 Anthropic API 的硬约束,违反会导致 BadRequestError。
这个版本适合高级工程师面或系统设计轮,重点讲清楚了状态管理和消息序列约束。
高频追问:消息顺序、异常恢复、项目场景
追问 1:「如果工具超时,tool_result 的 content 怎么填?」
建议答法:填结构化的错误信息,明确标注超时和重试建议,同时设置 is_error: true(如果 SDK 支持)。关键是让模型拿到足够信息决定下一步行为,不是给它一个无意义的空值。
追问 2:「并发调用三个工具,它们的 tool_result 可以打乱顺序吗?」
不建议打乱。tool_result 必须按 tool_calls 的顺序紧邻出现,打乱顺序会导致模型无法正确关联工具名和返回结果。如果需要并发执行,应该在执行层面并发,但写入消息数组时保持顺序。
追问 3:「你们项目里怎么管理 tool_result 的异常?」
开放性问题,考的是工程经验。可以讲:重试逻辑 + 超时兜底 + 错误信息结构化 + 状态图里的降级路径。
实际项目里通常会包装一个工具执行层,统一处理超时、网络错误和返回值校验,而不是让每个工具单独处理异常。
追问 4:「interrupt 恢复时消息序列怎么保证正确?」
核心是:在 post_tool_review 节点用 Command({ goto: "agent", update: { messages: [...] }}) 把反馈消息注入到正确位置,而不是依赖默认的追加逻辑。
如果你用 PostgresSaver 还要额外验证序列化后的顺序是否正确。

参考文献
[1] 原始资料[EB/OL]. https://github.com/MicrosoftDocs/Agent-Skills/blob/main/skills/microsoft-foundry/SKILL.md. (2026-05-08).
如果浏览器无法直接唤起微信,可在微信内打开公众号主页:计算机魔术师