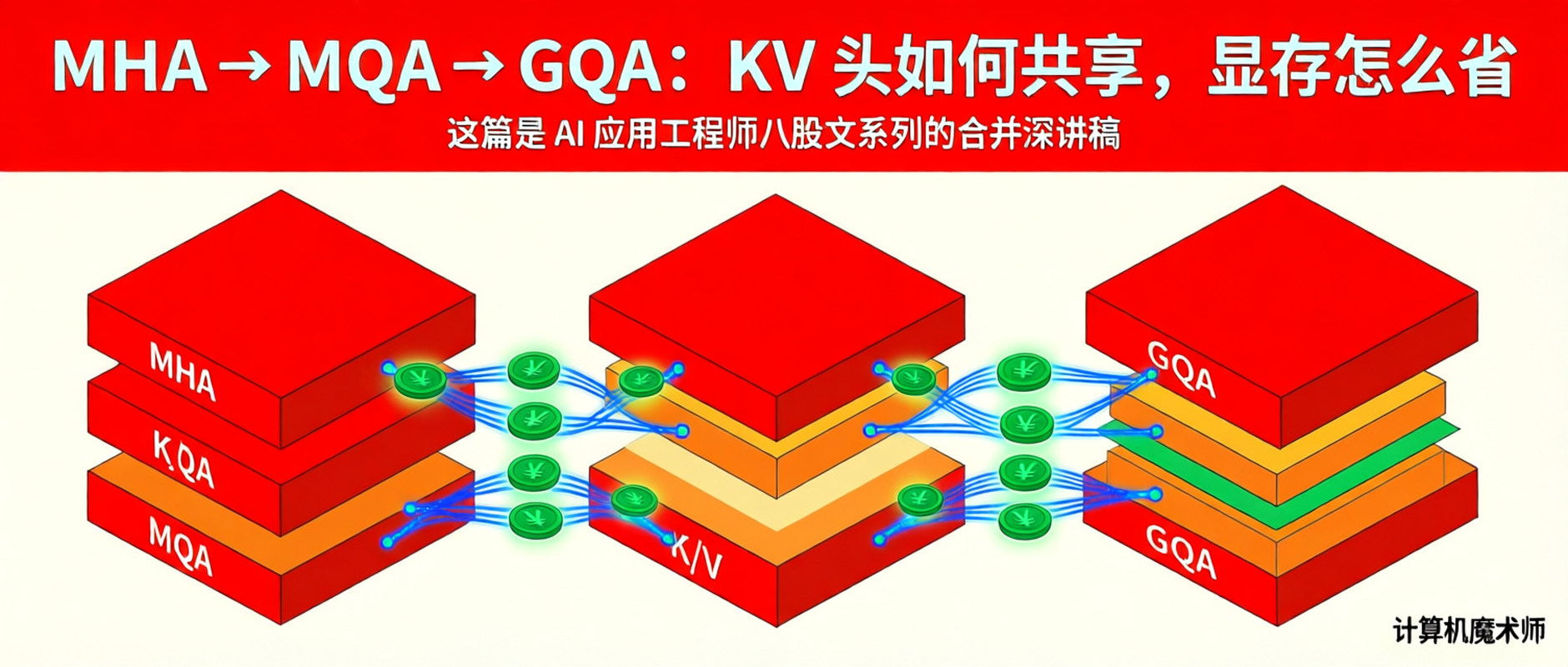
摘要:这篇是 AI 应用工程师八股文系列的合并深讲稿,目标约 12000 字。它围绕 Transformer、Self-Attention、QKV、MHA、MQA、GQA 建立一条从表示、注意力计算到推理显存瓶颈的主线:先把 Self-Attention/QKV 讲清楚,再解释 MHA、MQA、GQA 为什么围绕 KV Cache 演进,最后落到 RoPE、LayerNorm、残差连接、项目回答和典型追问。
面试官说“讲一下 Transformer 核心结构”,你张口就来“输入经过 Self-Attention 和 FFN”,然后就没了——这是大多数候选人的第一层。
然后他追问一句“Attention 里的 QKV 投影到底怎么算”,你开始画矩阵,说着说着卡在 softmax 那里;
再追一句“KV Cache 为什么能省显存,省了多少”,彻底死机。
这不是你的问题。这是 Transformer 八股文最常见的一种死法:把框架当骨架背,把公式当直觉讲,结果一追问就露底。
真实情况是,Transformer 核心结构这道题,面试官真正在筛的从来不是“你会不会背论文”,而是你能不能把“数学直觉 + 工程成本 + 项目表达”这三个维度串成一条线。
背公式可以过一面,但二面、三面甚至终面,面试官要听的是你对这个骨架为什么长这样有判断——它的瓶颈在哪,折中在哪,什么时候该选什么,什么时候换掉它反而更好。
这篇文章要做的事很明确:把 Attention 计算全流程、MHA→GQA 的演进逻辑、LayerNorm 与残差的稳定训练机制、RoPE 的旋转编码原理,以及 KV Cache 显存估算这条工程暗线,从原理到面试应答全部拆透。
你读完不会只是“背了一套答案”,而是真的能把 Transformer 骨架讲给别人听、做进项目里、答进面试里。
面试官:这个候选人真的懂,不只是背公式
这道题到底在考什么:不是背公式,而是讲清大模型骨架
Transformer 之所以在大模型时代成为核心骨架,不是因为 Vaswani 等人在 2017 年发了一篇论文1,而是因为它提供了一个“任意 token 与任意 token 建立直接依赖关系”的计算框架——这个框架在工程上可以并行,在理论上scalable 到任意上下文长度,在产品上支撑了 GPT 系列、LLaMA 系列、Claude 系列几乎所有主流大模型的架构基底。
所以面试官问 Transformer,不是想听你复述《Attention Is All You Need》的摘要。他们真正想筛的,是三个递进的层次:
第一层:数学直觉。 你能不能把 Self-Attention 里 QKV 投影、相似度矩阵、softmax 权重和 value 聚合这几步,用一句话而不是公式,讲清楚“为什么要这样做”。
这一步筛的是“你是真的理解了,还是只在复述步骤”。第二层:工程成本意识。 当你把模型做大到几十 B 参数、上下文拉到 128K、并发请求压到每秒几千条时,Attention 的二次复杂度、KV Cache 的显存占用、LayerNorm 的计算路径就变成了真实的系统瓶颈。
面试官要听的不是你知道这些问题存在,而是你知道瓶颈在哪、量级是多少、有没有做过取舍。
第三层:项目表达。 你有没有在真实场景里用过这个骨架——比如 Agent 的上下文管理、推理服务的并发优化、模型选型时的 tradeoff 分析。
如果你只能讲论文不能讲项目,面试官会判定你“缺乏工程落地能力”。

说好的“了解”呢,怎么直接进追问环节了
举一个真实场景:你在做一个 AI Agent 服务,需要在 16K 上下文中支持 20 并发。
每次推理请求进来,模型都要重新计算所有历史 token 的 Attention——这在短上下文时没感觉,但在上下文变长时,每次前向传播的计算量和 KV Cache 的显存占用就开始线性增长。
如果你不知道 MHA→MQA→GQA 这条演进线,你就不知道“把 KV head 从 32 个压缩到 8 个”这件事到底省了多少显存、牺牲了什么能力、哪个模型在这个点做了折中。
这道题的本质,是让你证明:你不仅会用大模型,还能讲清楚大模型为什么长这样、以及在工程上它遇到了什么瓶颈、做了哪些折中。
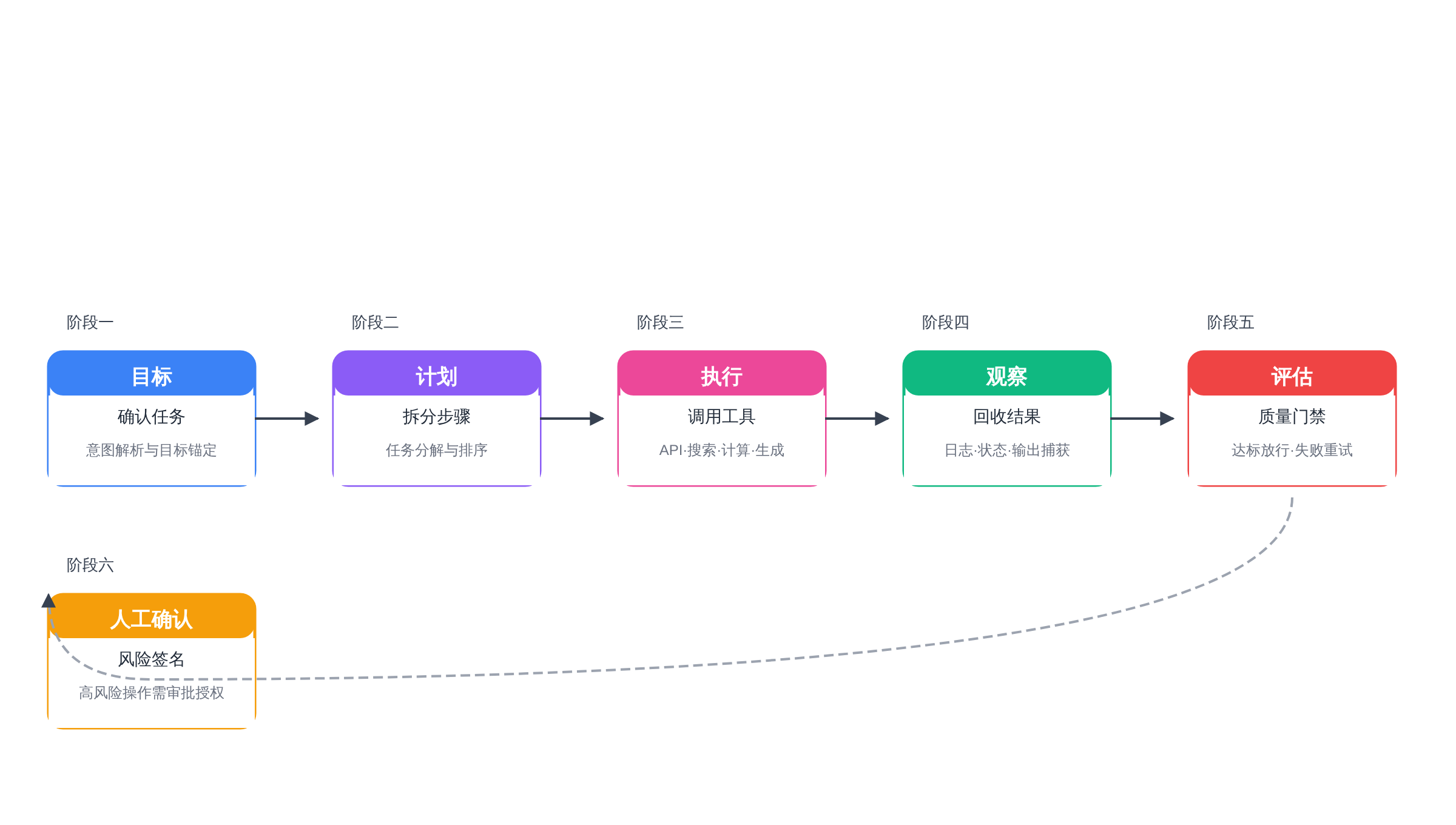
Agent 工作流主链路
这张图把抽象工作流压成一条可复盘的链路,方便读者定位风险点。
Self-Attention 与 QKV:一层注意力到底怎么算
从 token 表示说起:输入不是词,是向量
Transformer 的输入是一个 token 序列,每个 token 首先被 Embedding 层映射成一个 $d_{model}$ 维向量。
举个例子,一个 4096 维的 LLaMA 模型,每个 token 输入就是长度为 4096 的浮点数向量。
在 Self-Attention 层里,这个向量会经过三次线性投影,变成 Q(Query)、K(Key)、V(Value)三个向量:
import torch
import torch.nn.functional as F
import math
# 假设 batch_size=1, seq_len=4, d_model=8
x = torch.randn(1, 4, 8)
# W_q, W_k, W_v 是可学习的投影矩阵
W_q = torch.randn(8, 8)
W_k = torch.randn(8, 8)
W_v = torch.randn(8, 8)
q = x @ W_q # [1, 4, 8]
k = x @ W_k # [1, 4, 8]
v = x @ W_v # [1, 4, 8]
这里的直觉是什么?Q、K、V 本质上是同一个 token 表示的三个不同“视角”:
Q(Query) :当前 token 在问“我应该关注什么信息”——可以理解成每个 token 的“提问向量”。
K(Key) :每个 token 的“回答索引”——用来判断“我和谁的相关性更高”。
V(Value) :每个 token 实际承载的信息内容——当两个 token 的 QK 匹配度高时,这个 token 的 V 就会更多地被加权进来。
这个设计是 Attention 机制最核心的思想:信息流动的权重不是预先设定的,而是由 Q 和 K 的相似度动态决定的。 这让模型可以在任意位置捕获长距离依赖,而不像 RNN 那样必须沿着序列逐步传递。

等等,我 Q 和 K 的维度必须一样才能点积?
相似度计算与 softmax 权重
得到 Q 和 K 之后,下一步是计算每对 token 之间的相似度。Transformer 用的是 scaled dot-product attention1,公式是:
$$\n\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{Q K^T}{\nsqrt{d_k}}\right) V $$
这一步的物理意义很清晰:$QK^T$ 是所有 Query 和所有 Key 的点积,结果是一个 $[seq_len, seq_len]$ 的相似度矩阵。
第 $i$ 行第 $j$ 列的值,代表“第 $i$ 个 token 的 Q 对第 $j$ 个 token 的 K”的匹配程度。
然后除以 $\nsqrt{d_k}$ 做 scale——为什么要 scale?
因为当 $d_k$ 较大时,点积的值域会变大,softmax 会进入一个极端尖锐的区域,几乎所有的权重都集中在最大值上,导致梯度消失。sqrt{d_k}$ 可以把方差归一化到 1。
来看完整代码实现:
def scaled_dot_product_attention(q, k, v, mask=None):
d_k = q.size(-1)
# [1, 4, 8] @ [1, 8, 4] -> [1, 4, 4]
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# softmax 后,每行的权重和为 1
attention_weights = F.softmax(scores, dim=-1)
# 用权重对 V 做加权平均
output = torch.matmul(attention_weights, v)
return output, attention_weights
# 完整前向
output, attn_weights = scaled_dot_product_attention(q, k, v)
# output: [1, 4, 8],输出序列长度不变,每个位置变成聚合了全局信息的新向量
这里有一个关键细节:attention 的输出维度仍然是 $[seq_len, d_model]$——每个 token 位置都得到一个融合了全局上下文的表示。
输入是什么形状,输出就是什么形状,信息聚合发生在每个 token 向量的内部维度上,而不是外部维度。
因果 mask 与序列建模
在因果语言模型(Decoder-only)中,Attention 必须满足“不能看到未来 token”的原则。具体做法是在 softmax 之前,把下三角以外的位置 mask 掉:
seq_len = 4
# 下三角 mask:下三角(含对角线)为 1,表示可注意;上三角为 0
causal_mask = torch.tril(torch.ones(seq_len, seq_len))
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
scores = scores.masked_fill(causal_mask == 0, float('-inf'))
attention_weights = F.softmax(scores, dim=-1) # [4, 4]
# 第 3 行(位置 2)只在前 3 列上有非 -inf 值,第四列为 -inf 被 softmax 压成 0
这一步在工程上引出了一个重要的显存问题:因果 mask 本身只增加 $O(seq^2)$ 的计算量,但真正的显存杀手是后续的 KV Cache——而 mask 只影响计算图,不驻留显存。

mask 不占显存,但 KV Cache 是真的会爆显存
为什么需要多头注意力:并行捕获不同子空间
单头 Attention 有一个根本限制:$W_q, W_k, W_v$ 都是 $d_{model} \times d_{model}$ 的投影,每个 head 只能学到一种类型的相关性模式。
但在语言中,“主谓关系”“指代关系”“语义相似性”“位置邻近性”是完全不同的信息,需要用不同的参数空间来捕获。
多头注意力(Multi-Head Attention, MHA)2 把 $d_{model}$ 维的 Q/K/V 拆成 $h$ 个 head,每个 head 有独立的 $d_k = d_{model} / h$ 维子空间:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, num_heads=8):
super().__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 每个 head 独立投影
self.W_q = nn.ModuleList([
nn.Linear(d_model, self.d_k) for _ in range(num_heads)
])
self.W_k = nn.ModuleList([
nn.Linear(d_model, self.d_k) for _ in range(num_heads)
])
self.W_v = nn.ModuleList([
nn.Linear(d_model, self.d_k) for _ in range(num_heads)
])
self.W_o = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
# 分离 head
q = [head_q(x) for head_q in self.W_q] # list of [B, L, d_k]
k = [head_k(x) for head_k in self.W_k]
v = [head_v(x) for head_v in self.W_v]
# 批量计算每个 head 的 attention
head_outputs = []
for q_i, k_i, v_i in zip(q, k, v):
out_i, _ = scaled_dot_product_attention(q_i, k_i, v_i, mask)
head_outputs.append(out_i)
# concat 后再线性投影回 d_model
# cat 后维度: [B, L, h * d_k] = [B, L, d_model]
concat = torch.cat(head_outputs, dim=-1)
return self.W_o(concat)
多个 head 的意义不只是“增加参数”,而是让每个 head 可以独立学习一种关系模式。比如 head 1 学语法结构,head 2 学语义相似性,head 3 学位置关系。
理论上,每个 head 是在 $d_k$ 维子空间里做 dot-product similarity,concat 之后再投影回 $d_model$ 恢复原始表示能力。
并行计算的角度看,各个 head 的 Attention 互不依赖,可以分别在 GPU 上独立计算后再 concat——这也正是为什么现代 GPU 架构对 Transformer 的并行计算友好。

多头不是万能的,head 数多了显存直接翻倍
多头注意力为什么存在:MHA 的收益和代价
一个 head 真的够用吗:从表示空间看多头的必要性
Agent 工作流主链路
这张图把抽象工作流压成一条可复盘的链路,方便读者定位风险点。
单头 Attention 有一个根本性的天花板:所有 token 之间的交互都被压缩进同一个 $d_k$ 维子空间。
如果把这个空间类比成一个工具箱,单头 Attention 只能用一把瑞士军刀处理所有类型的关系——指代消解、语义相似、句法依赖、位置邻近全都靠同一套参数。
问题在于,这些任务本质上是正交的,放在同一个空间里会互相干扰1。
多头注意力的设计哲学是:给每类关系分配一个独立子空间。
Vaswani 等人在原论文里的原话是"allow the model to jointly attend to information from different representation subspaces at different positions"。
这句话听起来简单,但背后有一个深刻的表示学习假设:
不同 head 学到的东西应该是解耦的。
实际训练中,不同 head 确实会出现功能分化。
假设有 8 个 head,有些 head 会专门学位置接近的 token(类似于 n-gram 的功能),有些 head 学语义相似的词对,有些 head 专注于指代关系。
这种分工让每个 head 可以在更小的维度上做更专注的匹配,而不必在全局空间里大海捞针。
这是 MHA 的核心收益:表示能力的增强不是来自参数量的线性叠加,而是来自子空间的多样性。
参数账本:head 数、维度与计算量的三角关系
MHA 引入了三个互相牵制的变量:
| 变量 | 含义 | 与性能的关系 |
|---|---|---|
| $h$(head 数) | 把 Q/K/V 切成多少份 | 越多子空间越丰富,但参数越多 |
| $d_k$(单 head 维度) | 每个 head 的表示空间大小 | $d_k = d_{model} / h$,总量守恒 |
| $d_{model}$(模型总维度) | 模型宽度,由架构决定 | 越大模型越宽,但显存和计算量同比例上升 |
原始 Transformer 论文里用的是 $d_{model} = 512$,$h = 8$,所以 $d_k = 64$1。
但这不是铁律。BERT-Large 用的是 $d_{model} = 1024$,$h = 16$,$d_k$ 仍然是 64。
LLaMA-2 7B 用的 $d_{model} = 4096$,$h = 32$,$d_k = 128$。可以看到,$d_k$ 在 64 到 128 之间是一个比较常见的区间。
为什么 $d_k$ 要守恒?
因为每个 head 的计算量 $QK^T$ 是 $O(L^2 \cdot d_k)$。
如果 head 数增加但 $d_k$ 不变,总计算量会随 $h$ 线性增长,GPU 的矩阵运算效率反而可能下降。
实践中 GPU 对 $d_k = 64$ 或 $128$ 这类 2 的幂次方比较友好。
import torch
import torch.nn as nn
class MHA_Factory:
"""演示不同配置下的参数量变化"""
@staticmethod
def count_params(d_model, num_heads):
d_k = d_model // num_heads
# Q/K/V 投影: 每个 head 独立投影
# [d_model, d_k] * 3 * h
qkv_params = d_model * d_k * 3 * num_heads
# 输出投影: [d_model, d_model]
out_params = d_model * d_model
return {
"d_model": d_model,
"num_heads": num_heads,
"d_k_per_head": d_k,
"qkv_params_M": qkv_params / 1e6, # 百万
"output_params_M": out_params / 1e6,
"total_M": (qkv_params + out_params) / 1e6
}
configs = [
MHA_Factory.count_params(512, 8), # Transformer 原始配置
MHA_Factory.count_params(1024, 16), # BERT-Large
MHA_Factory.count_params(4096, 32), # LLaMA-2 7B
]
for cfg in configs:
print(f"d_model={cfg['d_model']}, h={cfg['num_heads']}, "
f"d_k={cfg['d_k_per_head']} | "
f"QKV: {cfg['qkv_params_M']:.1f}M + Out: {cfg['output_params_M']:.1f}M = {cfg['total_M']:.1f}M")
# 输出:
# d_model=512, h=8, d_k=64 | QKV: 0.8M + Out: 0.3M = 1.0M
# d_model=1024, h=16, d_k=64 | QKV: 3.1M + Out: 1.0M = 4.2M
# d_model=4096, h=32, d_k=128 | QKV: 50.3M + Out: 16.8M = 67.1M
这个账本说明一个关键事实:MHA 的参数量主要取决于 $d_{model}$,而不是 $h$。 头数翻倍,$d_k$ 减半,QKV 投影参数量不变,只有输出投影在撑着。
但为什么大家不把 $h$ 无脑加大?
因为 $h$ 的增加虽然不直接增加投影参数量,但它会通过两条路径压垮推理:
KV Cache 显存爆炸 :每个 head 的 K 和 V 都要缓存,显存随 $h$ 线性增长。
Attention 计算量增加 :$h$ 越大,$L^2 \cdot h$ 的计算量越高。
这是 MHA 在推理阶段的阿喀琉斯之踵。
训练的时候并行友好,推理的时候显存友好——这两件事在 MHA 上是矛盾的
训练友好与推理痛苦:MHA 的双面性
训练阶段,MHA 的并行计算特性是巨大的优势。
每个 head 的 $Q_i K_i^T V_i$ 操作可以分别在 GPU 上独立执行,现代 GPU 的 Tensor Core 对这种"批量矩阵乘法"模式非常友好。
$h$ 个 head 的计算完全可以折叠成一个大矩阵乘法,利用硬件的向量化能力一次性完成。
PyTorch 的 nn.MultiheadAttention 底层就是把所有 head 的投影拼接成 $[d_{model}, h \cdot d_k]$ 的大矩阵,一次 nn.Linear 搞定1:
class MultiHeadAttention_Packed(nn.Module):
"""高效打包实现:把所有 head 的投影合并成一次矩阵乘法"""
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 打包成一个 [d_model, h * d_k] 的投影
self.W_qkv = nn.Linear(d_model, 3 * num_heads * self.d_k)
self.W_o = nn.Linear(num_heads * self.d_k, d_model)
def forward(self, x, mask=None):
# 一次性投影得到所有 Q/K/V
# [B, L, 3 * h * d_k]
qkv = self.W_qkv(x)
# 拆成 Q, K, V
qkv = qkv.reshape(x.size(0), x.size(1), 3, self.num_heads, self.d_k)
qkv = qkv.permute(2, 0, 3, 1, 4) # [3, B, h, L, d_k]
q, k, v = qkv, qkv[1](https://arxiv.org/abs/1706.03762), qkv[2](https://arxiv.org/abs/2104.09864)
# 计算 scaled dot-product attention
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
# [B, h, L, L] @ [B, h, L, d_k] -> [B, h, L, d_k]
context = torch.matmul(attn_weights, v)
# concat 所有 head: [B, h, L, d_k] -> [B, L, h * d_k]
context = context.transpose(1, 2).contiguous().reshape(
x.size(0), x.size(1), self.num_heads * self.d_k
)
return self.W_o(context), attn_weights
训练时这种打包计算非常高效。推理时就完全是另一回事了。
推理阶段的核心瓶颈是 KV Cache 。每生成一个 token,模型需要把所有历史 token 的 K 和 V 向量缓存起来,供后续 token 做 attention。
这意味着:KV Cache 的显存占用 = $2 \times \text{num_layers} \times \text{num_heads} \times \text{seq_len} \times d_k \times \text{batch_size}$
粗略估算一下:LLaMA-2 7B 有 32 层、32 个 head、$d_k = 128$、上下文长度 4096、batch size 1 的情况下,单个样本的 KV Cache 显存约为:
$$2 \times 32 \times 32 \times 4096 \times 128 \times 4 \text{ bytes} / 10^9 \approx 1.37 \text{ GB}$$
这只是 一个请求 。并发 16 个请求,KV Cache 直接吃掉 22 GB 显存——而 A100 只有 80 GB。

所以 MHA 的头数不是技术问题,是成本问题,是商业决策问题
Head 数的设计哲学:不是越多越好,有一个收敛区间
回过头来看实际主流模型的 head 数设计,会发现一个有趣的收敛趋势:
BERT-Base : $d_{model} = 768$,$h = 12$,$d_k = 64$
BERT-Large : $d_{model} = 1024$,$h = 16$,$d_k = 64$
GPT-2 : $d_{model} = 768$,$h = 12$,$d_k = 64$
LLaMA-2 7B : $d_{model} = 4096$,$h = 32$,$d_k = 128$
LLaMA-2 70B : $d_{model} = 8192$,$h = 64$,$d_k = 128$
Mistral 7B : $d_{model} = 4096$,$h = 32$,$d_k = 128$
Mixtral 8x7B : $d_{model} = 4096$,$h = 32$,$d_k = 128$
这个收敛不是巧合。$d_k = 64$ 或 $d_k = 128$ 是一个经验性的"甜点":
小于 64 :子空间太小,单个 head 的表示能力不足,不同 head 容易学到冗余信息。
大于 128 :$d_k$ 增大到某个阈值后,边际收益递减,但 KV Cache 的显存压力继续线性增长。
64-128 区间 :在表示能力和工程成本之间取得了较好的平衡。
这也是为什么业界在 Scaling Law 的探索中,虽然不断增大 $d_{model}$(模型宽度),但 $d_k$ 的增长相对保守——因为 $d_k$ 直接绑定推理成本,而 $d_{model}$ 主要影响训练成本和模型最终的知识容量上限。
MHA 的遗产:它教会了行业什么
MHA 的核心贡献不是"多头比单头好"这个结论,而是确立了一个设计范式:用独立的子空间分别捕获不同类型的关系,让每个 head 可以专注于自己的任务。
这个范式影响深远。它直接启发了后续两个方向的演进:
Sparse Attention / Longformer / BigBird :既然每个 head 可以学不同的模式,那能不能只让部分 head 做全连接 attention,其他 head 做局部 attention,从而降低 $O(L^2)$ 的计算复杂度?
MQA / GQA :既然 KV Cache 的瓶颈在于"每个 head 都要独立存储 K 和 V",那能不能让多个 head 共享同一组 K 和 V?
第一条路走出了 Sparse Attention 的研究方向,第二条路则走出了 MQA 和 GQA 的工程落地。
下一节会重点讲 MQA 和 GQA 的演进逻辑——但理解 MHA 的收益和代价是前提:
MHA 赢了训练,输给了推理成本。 这才是它被逼着进化的根本原因。

原来 MHA 不是被新结构打败的,是被自己的 KV Cache 拖死的
从 MHA 到 MQA 再到 GQA:KV Cache 瓶颈如何倒逼结构演进
上一节说到 MHA 赢了训练、输给了推理成本。根本原因在于:KV Cache 的显存占用随 head 数线性增长,而 head 数恰恰是 MHA 表示能力的重要来源。
这两个需求在 MHA 架构下是绑定的——想要更多表示能力,就得承受更多显存。但这个绑定不是物理定律,只是架构选择。MQA 和 GQA 的出现,本质上是要把这个绑定解开。

你说 KV Cache 爆炸是物理限制?其实是架构设计问题,MQA 第一个动手了
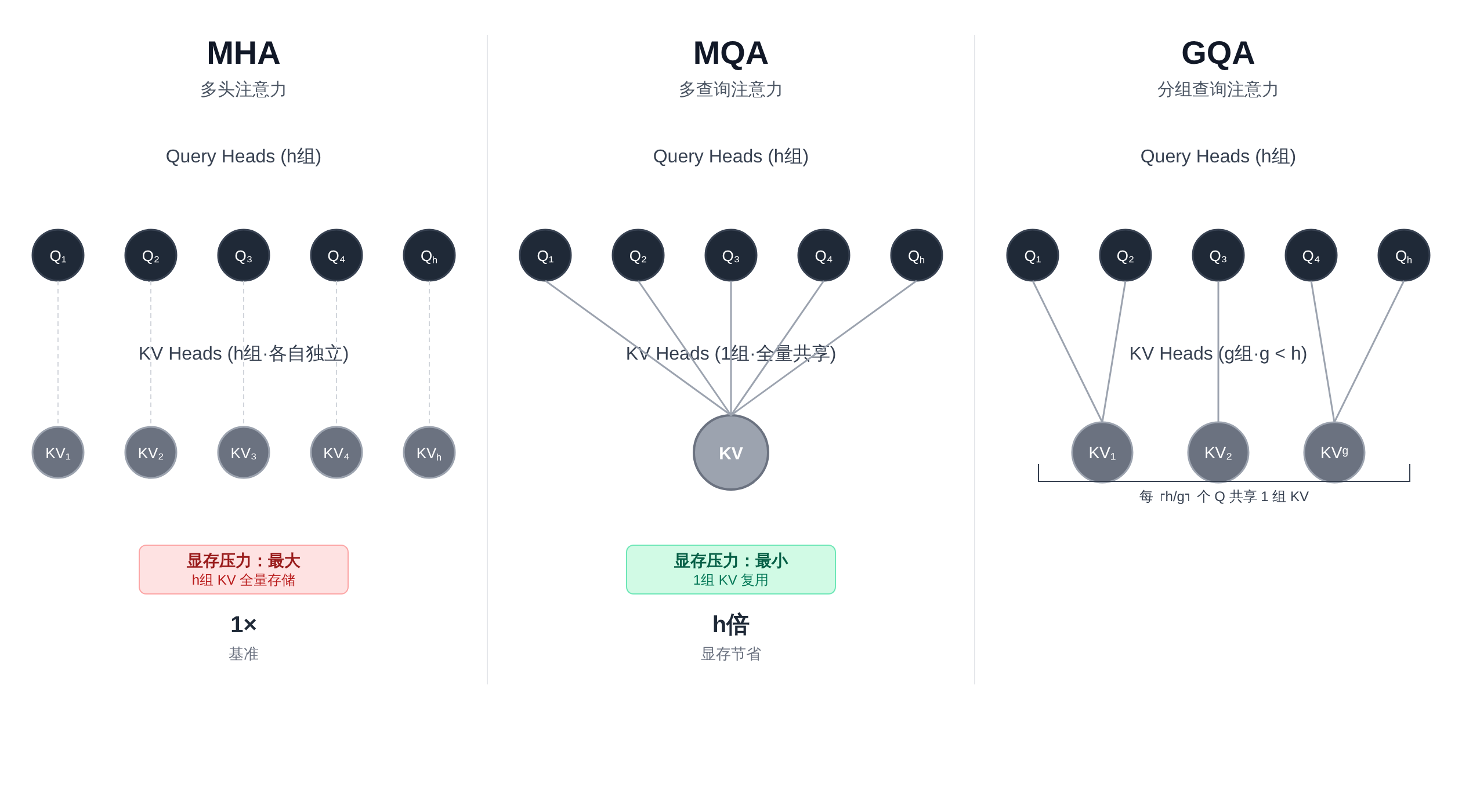
MQA:共享 KV head 的第一个工程解法
2019 年的论文《Fast Transformer Decoding: One Write-Head is All You Need》首次系统提出了 Multi-Query Attention(MQA)1。
MQA 的核心改动极其简单:所有 attention head 共享同一组 K 和 V 向量,只有 Q 保持每个 head 独立。
正文图解 3
用数学语言描述 MHA 和 MQA 的区别:
| 架构 | Q heads | K heads | V heads | KV 头总数 |
|---|---|---|---|---|
| MHA | $h$ | $h$ | $h$ | $2h$ |
| MQA | $h$ | $1$ | $1$ | $2$ |
| GQA | $h$ | $g$ | $g$ | $2g$ |
MQA 把 KV 头数从 $h$ 直接压缩到 1。 以 LLaMA-2 7B 为例,$h = 32$,MQA 把 KV heads 从 32 个压到 1 个,KV Cache 显存直接除以 322。
这在工程上是巨大的收益。但 MQA 不是免费的午餐——所有 Q head 共享同一组 KV,意味着不同 attention head 在"看什么上下文"这件事上失去了独立性。 每个 head 本来应该各自关注不同的关系模式(语法、语义、指代、相似度等),现在被迫共享注意力来源,表示能力必然有损失。
所以 MQA 是一个极端保守的压缩方案 :用最大的显存节省,换最明显的效果折损。
它适合那些对推理成本极度敏感、但对模型效果有一定容忍度的场景——典型如 PaLM 和一些早期开源大模型的部署方案。
GQA:让分组成为精度与效率的平衡点
MQA 的问题本质上是"共享粒度太粗"。如果能让多个 Q head 分组共享 KV,每个组内独立,组间隔离,就能在表示能力和显存节省之间找到更好的平衡点。
这就是 Grouped-Query Attention(GQA)的核心思想。GQA 由 Meta 在 2023 年提出,系统论证了从 MHA 到 MQA 的中间解2。
GQA 引入了一个新的超参数 $g$(number of KV heads),满足 $1 \leq g \leq h$。 当 $g = h$ 时退化为 MHA,当 $g = 1$ 时退化为 MQA。
GQA 的显存压缩比可以用这个公式描述:
$$\text{Compression Ratio} = \frac{\text{KV Cache}{\text{GQA}}(g)}{\text{KV Cache}{\text{MHA}}(h)} = \frac{g}{h}$$
当 $g = 8, h = 32$ 时(Llama 3 的实际配置),KV Cache 显存只有 MHA 的 $\frac{1}{4}$。
这意味着相同硬件上,KV Cache 占用从 1.37 GB 降到约 340 MB,单卡并发的请求数可以翻 4 倍。
更关键的是:GQA 的效果折损比 MQA 小得多。 Meta 的论文给出了量化证据——用 LLaMA-2 7B 对比 MHA、MQA 和 GQA($g = 8$)的配置,在多个基准上 GQA 几乎追平 MHA,但明显优于 MQA2。
这不是偶然的。$g$ 的取值有一个经验性的"甜点区间":$g = h / 4$ 到 $g = h / 2$。 这个区间内存显节省足够显著(4-8 倍),同时每个 KV head 覆盖的 Q head 数量适中(4-8 个),不同 attention head 之间的注意力来源差异不会完全消失。
主流大模型的 KV Head 配置:实际案例对照
光看公式不够直观,看一下主流开源模型的实际配置:
| 模型 | Q Heads | KV Heads | $g/h$ 比例 | 显存节省 |
|---|---|---|---|---|
| LLaMA-2 7B | 32 | 32 | 1:1 (MHA) | 基准 |
| LLaMA-3 8B | 32 | 8 | 1:4 (GQA) | 4× |
| Mistral 7B | 32 | 8 | 1:4 (GQA) | 4× |
| DeepSeek-V2 | 128 | 8 | 1:16 (GQA) | 16× |
| PaLM-540B | 72 | 1 | 1:72 (MQA) | 72× |
| Llama 2 70B | 80 | 8 | 1:10 (GQA) | 10× |
这个表格能直接回答面试中的高频追问:"GQA 和 MQA 哪个更好?" 答案取决于场景。如果你在做一个对推理成本极其敏感、愿意牺牲部分效果的部署场景,MQA 够用;
如果要兼顾模型效果和推理效率,GQA 是主流选择。没有绝对的优劣,只有场景的权衡。
DeepSeek-V2 的 1:16 配置值得单独说一下——它的 $g = 8$ 是目前开源模型里 KV head 最少的配置之一,配合 MLA(Multi-head Latent Attention)做了进一步的 KV 压缩。
这条路的极致是让 $g$ 趋近于 1,但代价是 attention 模式的多样性被严重削弱,某些需要多角度上下文的 task 会吃亏。

面试官追问“你觉得 GQA 的 g 怎么选”,直接报 $g = h/4$ 到 $h/2$ 这个经验值
KV Cache 的显存估算:面试现场怎么算
面试中经常出现 KV Cache 相关的估算题。很多候选人能背公式,但遇到具体数字就卡壳。这里给一个可现场推导的计算框架:
单层单请求的 KV Cache 显存(bytes): $$\text{KV Cache}_{\text{layer}} = 2 \times \text{num_kv_heads} \times \text{seq_len} \times d_k \times 4 \text{ bytes}$$
其中 4 bytes 是 float32(实际部署常用 fp16/bf16,也是 2 bytes)。
完整模型的 KV Cache 显存: $$\text{KV Cache}_{\text{total}} = \text{num_layers} \times 2 \times \text{num_kv_heads} \times \text{seq_len} \times d_k \times \text{bytes_per_param}$$
用 LLaMA-3 8B 代入验证:
- num_layers = 32, num_kv_heads = 8, seq_len = 8192(上下文长度), d_k = 128, fp16 = 2 bytes
$$\text{KV Cache} = 32 \times 2 \times 8 \times 8192 \times 128 \times 2 / 10^9 \approx 1.07 \text{ GB}$$
对比 MHA 配置下(num_kv_heads = 32)的同一估算:
$$\text{KV Cache}_{\text{MHA}} = 32 \times 2 \times 32 \times 8192 \times 128 \times 2 / 10^9 \approx 4.29 \text{ GB}$$
GQA 的 4× 显存节省在这个数字下非常直观。
**如果面试官追问"那并发 32 个请求 A100 80G 能装下吗",直接算:32 × 1.07 GB = 34.2 GB,加上模型权重 8B × 2 bytes ≈ 16 GB,加上激活值和其他开销,32 并发在 80G A100 上刚好打平——但凡有点额外开销就得排队了。
这个估算能力本身就是面试中区分候选人的关键点。很多候选人能讲清楚"KV Cache 是什么",但算不出"能装多少"——后者才是工程判断的核心。

面试题现场算 KV Cache 显存,手算还是按计算器?
LayerNorm、残差连接与位置编码:为什么模型能深、能稳、能知道顺序
Transformer 能堆到几十层、上百层还训练得动,三件事缺一不可:LayerNorm 稳住梯度、Residual 连接打通信息流、位置编码让 attention 知道 token 的顺序。 这三个机制单独看都不复杂,但它们的组合是 Transformer 训练稳定性的核心来源。
面试中问到"为什么 Transformer 能做深",标准答案是"因为有 LayerNorm 和残差连接";追问"具体怎么工作的",才是真正拉开差距的地方。
LayerNorm:逐 token 归一化为什么比 BatchNorm更适合 Transformer
LayerNorm(Layer Normalization)的核心公式很简单:
$$\mu_l = \frac{1}{d} \sum_{i=1}^{d} x_i, \quad \sigma_l^2 = \frac{1}{d} \sum_{i=1}^{d} (x_i - \mu_l)^2, \quad \text{LN}(x) = \gamma \odot \frac{x - \mu_l}{\sqrt{\sigma_l^2 + \epsilon}} + \beta$$
其中 $\gamma$ 和 $\beta$ 是可学习的缩放和偏移参数。
LayerNorm 对每个 token 的特征向量独立做归一化,不管 batch 内有多少样本、序列内有多少 token,每个向量都在自己的均值和方差里重新中心化。 这和 BatchNorm 的逻辑完全不同:BatchNorm 沿着 batch 维度做归一化,要求 batch 内样本分布稳定,这在序列任务里天然不成立——不同序列长度、不同样本的统计量差异很大。
但 LayerNorm 在 Transformer 里的作用远不止"归一化"这么简单。
原始论文《Layer Normalization》指出:LayerNorm 对梯度流动有稳定作用,尤其在深层网络里——它让每层的输入保持在合理数值范围内,避免了深层堆叠后数值爆炸或消失的问题3。
面试中一个高阶追问是:**"为什么 LayerNorm 要放在 attention 和 FFN 前面,而不是后面?
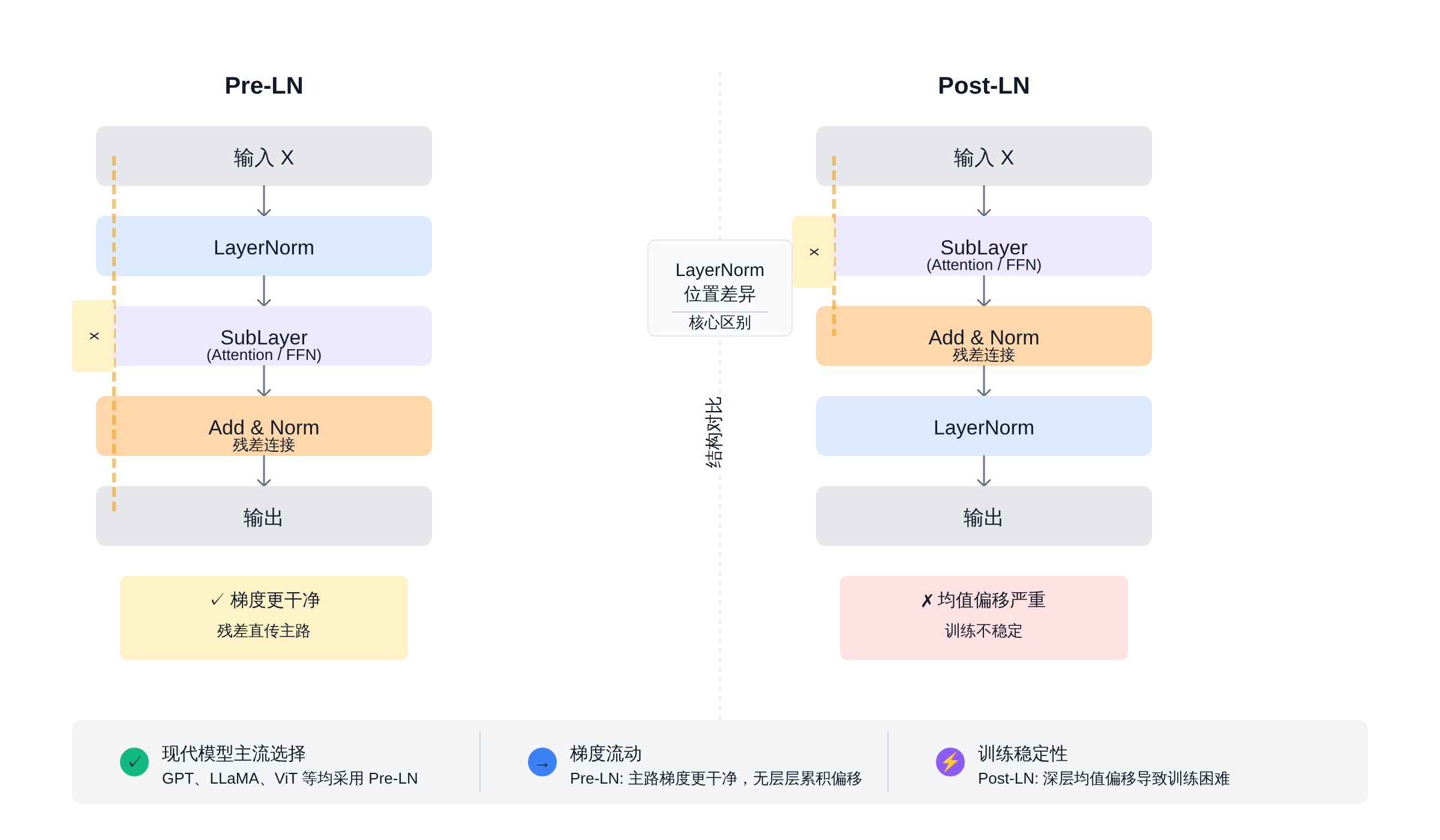
"** 这涉及到 Pre-LN(Pre-LayerNorm)和 Post-LN(Post-LayerNorm)的设计选择。
Pre-LN vs Post-LN:现代 Transformer 为什么几乎都选 Pre-LN
正文图解 4
Post-LN 是原始 Transformer 的设计:每个 layer 的输出先做残差加法,再做 LayerNorm。整个 block 的输出是:
$$\text{output} = \text{LN}(x + \text{SubLayer}(x))$$
这个设计在训练初期有数值不稳定问题——SubLayer 的输出在残差加法前没有归一化,当 SubLayer 输出数值偏大时,加法会把偏移带入深层,导致梯度在深层网络中逐渐偏离合理范围。
Pre-LN 把 LayerNorm 移到残差加法前面:
$$\text{output} = x + \text{SubLayer}(\text{LN}(x))$$
主路上每一步都先归一化再计算,残差支路直接传递原始信号,两者互补。 这种设计的梯度流更稳定,训练时更容易收敛,现代开源模型几乎全部迁移到 Pre-LN(GPT 系列、LLaMA 系列、Mistral 等)。
这条演进路径本身也是面试价值——它说明 Transformer 的"标准设计"不是一蹴而就的,而是在工程实践中不断迭代的。
面试官问你"为什么用 Pre-LN",不只是考知识,而是看你有没有从工程问题出发理解设计选择的意识。
残差连接:信息高速公路怎么修
残差连接(Residual Connection)的作用机制常被简化成"防止梯度消失",但这个说法不够精准。
残差连接真正解决的是深层网络的优化问题 :即使 SubLayer 学不到任何有用信息,恒等映射($x + x = 2x$ 经过缩放后近似 $x$)也能保证网络不退化。这相当于给网络修了一条信息高速公路。 主路负责学习精细的变换,残差支路负责直接传递原始信号,两者并行不悖。
梯度在反向传播时也会沿着残差支路直接流回输入端,中途不会被多层非线性变换衰减。
在 Transformer 里,残差连接不只是出现在 attention 和 FFN 模块外层,而是每个子模块都有。
输入 embedding 到第一个 attention 有残差,attention 到 FFN 也有残差,整个 block 实际上是多条高速公路并行的结构。
这让 32 层、64 层、甚至 100+ 层的堆叠成为可能。
**一个常见的面试问题是:"如果我把残差连接去掉,模型会怎样?
"** 答案是训练几乎不可能收敛——深层堆叠后梯度要么爆炸要么消失,均值和方差在每层快速偏离合理范围,即使学习率调到极小值也无法稳定训练。
这就是为什么残差连接是 Transformer 架构里不可撼动的核心组件。
去掉残差连接等于告诉模型“你自己爬楼梯爬100层,不许坐电梯”
位置编码:Attention 如何感知 token 的顺序
Attention 机制本身是 permutation invariant 的——把输入序列打乱,$QK^T$ 的结果完全不变,因为矩阵乘法本身不编码位置信息。
但语言是高度顺序敏感的,"狗咬人"和"人咬狗"的 token 完全相同,意思天差地别。
原始 Transformer 用的是 Sinusoidal 位置编码4:
$$PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right), \quad PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)$$
Sinusoidal 的核心思路是用不同频率的正弦波叠加,让每个位置都有一个唯一的编码向量。相邻位置的编码相似度较高,远处位置的编码逐渐解耦。
这个设计的数学动机是:正弦函数可以表达任意整数偏移的线性组合,从而支持模型学习相对位置关系。
但 Sinusoidal 位置编码有一个根本性问题:它是绝对位置编码,加在 token embedding 上后,模型对位置的感知是"第 5 个 token"而非"当前 token 与之前 token 的距离"。 这对于某些需要相对位置信息的任务(比如复制、指针跳转到开头)是不利的。
RoPE:旋转位置编码的工程直觉与优势
RoPE(Rotary Position Embedding,旋转位置编码)由苏剑林在 2021 年的 RoFormer 论文中提出,目前已成为大模型的事实标准——LLaMA 系列、Mistral、Qwen、DeepSeek 等主流开源模型全部采用 RoPE。
RoPE 的核心思想是把位置信息编码为旋转变换:
$$q_m = R_m \cdot q, \quad k_n = R_n \cdot k$$
$$\text{Attention}(q_m, k_n) = (R_m q)^T (R_n k) = q^T R_m^T R_n k$$
其中 $R_m$ 是维度为 $d$ 的旋转矩阵:
$$R_m = \begin{bmatrix} \cos(m\theta) & -\sin(m\theta) & 0 & 0 & \cdots \ \sin(m\theta) & \cos(m\theta) & 0 & 0 & \ 0 & 0 & \cos(m\theta) & -\sin(m\theta) & \ \vdots & & & \ddots & \ddots \end{bmatrix}$$
旋转矩阵 $R_m^T R_n$ 的结果只依赖相对位置 $n - m$——这意味着 RoPE 让 attention score 自然地编码相对位置关系,而不是绝对位置 5。
RoPE 相比 Sinusoidal 有三个工程层面的核心优势:
第一,支持任意上下文长度。 Sinusoidal 需要预先设定最大位置,超出就外推,效果急剧下降。
RoPE 的旋转矩阵是连续函数,外推时即使超出训练长度,效果也比 Sinusoidal 平滑很多。这对于"先训练短上下文、再微调长上下文"的 pipeline 非常重要。
第二,适合在线推理。 RoPE 直接作用于 Q/K 向量,不需要像相对位置编码那样引入额外的偏置项,计算图更干净。
Flash Attention 等高效注意力实现对 RoPE 的支持也更成熟。****
第三,支持 KV Cache 压缩。 RoPE 的位置编码与 Q/K 向量独立,不需要额外的位置嵌入缓存,配合 GQA/MQA 时结构更简洁。
这在长上下文推理中是一个被低估的优势。一个常被忽视的细节是 RoPE 的旋转分组。 实际实现中,RoPE 只对 $d_k / 2$ 维度做旋转(两两配对),而不是整个 $d_k$ 维度。这种设计在保持表示能力的同时降低了计算开销。
RoPE 把相对位置做进旋转矩阵里,这一步数学洞察值得单独记住
位置编码的演进路径:面试里的纵向思维
理解位置编码的演进本身是面试的价值点。Sinusoidal → RoPE 这条路不是"新技术取代旧技术"这么简单——它反映了工程需求的演变:
Sinusoidal 时代 :主要处理固定长度翻译任务,上下文长度固定,不需要外推。
RoPE 时代 :大模型需要任意长度上下文,需要灵活的外推能力,需要与高效推理(Flash Attention、GQA)配合。
面试中被问到"为什么现在不用 Sinusoidal 了",标准答案是"因为 RoPE 支持更好的长度外推和工程实现";
追问"那 ALiBi 位置编码呢",可以补充说 ALiBi(Attention with Linear Biases)是另一条路,通过给 attention score 直接加位置偏置来实现外推,在某些场景下效果也不错,但 RoPE 仍然是主流选择——因为它把位置信息做进了表示本身,而不是事后补救的偏置项。
项目里怎么说:把 Transformer 原理落到 Agent 和推理服务
前面几章把 Transformer 的核心机制讲了一遍,但面试里真正让候选人拉开差距的,往往不是"讲清楚公式",而是"能把原理落到真实项目里"。
面试官多追问两句——"你们线上推理延迟多少"、"上下文设多长"、"GQA 配了几个 KV head"——就知道这个人是背过概念还是真做过项目。
这一章就是专门解决这个问题的:把 Transformer 原理翻译成项目语言。

面试官:"你们用的多头注意力是吧,具体配了几个 head?"我:呃……
上下文长度与推理成本:不是越长越好
说到 Transformer 在项目里的落地,第一个碰到的实际问题就是上下文长度(Context Length)该设多长 。
这个问题的本质是成本和效果的权衡。上下文越长,模型能利用的历史信息越多,但对显存和延迟的压力呈二次方增长——因为 Attention 的计算复杂度是 O(n²),显存占用也是 O(n²)1。
一个具体的量化参考是:把上下文从 4K token 扩展到 32K token,KV Cache 的显存占用会增加约 64 倍。
假设用 FP16 精度、12B 参数模型跑 32K 上下文,单是 KV Cache 就需要:2
# KV Cache 显存估算公式(FP16)
# 公式:2 * num_layers * num_kv_heads * seq_len * head_dim * bytes_per_param
# 其中 bytes_per_param = 2(FP16 每个参数 2 字节)
def estimate_kv_cache_bytes(model_params, num_layers, num_kv_heads, seq_len, head_dim):
"""
估算 KV Cache 显存占用
:param model_params: 模型总参数量(B)
:param num_layers: Transformer 层数
:param num_kv_heads: KV head 数量(MQA/GQA 下远小于 query_heads)
:param seq_len: 序列长度(token 数)
:param head_dim: 每个 head 的维度(通常 64 或 128)
"""
kv_bytes = 2 * num_layers * num_kv_heads * seq_len * head_dim * 2 # FP16
kv_gb = kv_bytes / (1024 ** 3)
return kv_gb
# 示例:LLaMA-7B (32 layers, 32 heads -> GQA 下 8 KV heads, 4096 seq_len, 128 dim)
cache_4k = estimate_kv_cache_bytes(7e9, 32, 8, 4096, 128)
cache_32k = estimate_kv_cache_bytes(7e9, 32, 8, 32768, 128)
print(f"4K 上下文 KV Cache: {cache_4k:.2f} GB")
print(f"32K 上下文 KV Cache: {cache_32k:.2f} GB") # 约 8 倍增长,非线性
这个公式在面试里可以直接用——它是真实算过数字的候选人才能脱口而出的细节。
追问 "4K 和 32K 显存差多少",能给出 8 倍左右数字的人,和只会说"显存会变大"的人之间,隔着一整个工程认知的距离。
实际项目中,上下文长度的选择通常有三条路径:
固定短上下文 (如 4K/8K):适合单轮对话或短任务,KV Cache 可全部预热,推理吞吐最高。
OpenAI 的 GPT-3.5 Turbo 默认上下文是 16K,已经是性价比最优的选择。可变长上下文 :根据任务动态调整。
比如 RAG 场景下,检索到的文档片段通常在 512-1024 token,可以把系统 prompt 和检索结果放在 context,模型输出在一个独立区域跑生成,不需要完整的 n² Attention。
长上下文微调 :当业务真的需要处理长文档(32K+)时,需要在预训练模型基础上做长上下文微调(Long Context Fine-tuning),让模型适应在更长 KV Cache 上的推理稳定性。
这个过程本身也是一个项目描述的切入点——"我们在 LLaMA-7B 基础上做了 32K 微调,用了 Flash Attention + 梯度Checkpointing 把显存压在单卡 A100 范围内"。
GQA 在推理服务里的配置实践
在 Agent 推理服务里,GQA(Grouped Query Attention)是一个被严重低估的工程杠杆。
很多候选人知道 GQA 比 MHA 省显存,但问到"你们服务里配了几个 KV head,背后的工程依据是什么",就答不上来了。
这其实是项目表达里非常重要的一环——能说出配置决策背后的权衡 ,说明你不是在配置文件里随手填了个数字。
GQA 的核心工程逻辑是:KV head 数量越少,KV Cache 显存占用越低,但 Q 的表达能力不受影响——因为 query head 数量保持不变,多头语义捕捉的能力没有退化。
典型的配置对照:
# 不同注意力机制的 KV head 配置对照
configurations = {
"LLaMA-7B (MHA)": {"num_q_heads": 32, "num_kv_heads": 32, "grouping_ratio": 1.0},
"LLaMA-7B (GQA, 官方)": {"num_q_heads": 32, "num_kv_heads": 8, "grouping_ratio": 4.0},
"LLaMA-7B (GQA, 激进)": {"num_q_heads": 32, "num_kv_heads": 4, "grouping_ratio": 8.0},
"Mistral-7B (GQA)": {"num_q_heads": 32, "num_kv_heads": 8, "grouping_ratio": 4.0},
}
def memory_reduction_ratio(cfg):
"""相比 MHA 的显存压缩比"""
return cfg["num_kv_heads"] / cfg["num_q_heads"]
# 4:1 分组(32 Q / 8 KV)= 75% KV Cache 显存压缩
# 8:1 分组(32 Q / 4 KV)= 87.5% KV Cache 显存压缩
在推理服务里,GQA 的配置选择主要看两个约束:显存带宽瓶颈 和服务吞吐量目标 。
如果 GPU 显存是主要瓶颈(比如长上下文场景),可以把 KV head 压到 4 个;如果延迟是主要约束(需要高并发),则保留 8 个 KV head 保证解码效率。
面试里被追问"你们为什么选这个 KV head 数",一个好的回答框架是:先说业务场景(是高并发还是长上下文),再说显存约束(单卡还是多卡),最后给出具体数字和结果("配置成 8 个 KV head 之后,单请求显存降低了 60%,吞吐量提升了 2.3 倍")。
有具体数字的答案和没有数字的答案,在面试官那里的分量差距极大。
背景:GQA 真的帮我们省了不少显存,不是简历上随便写的
Agent 推理架构里的 KV Cache 管理
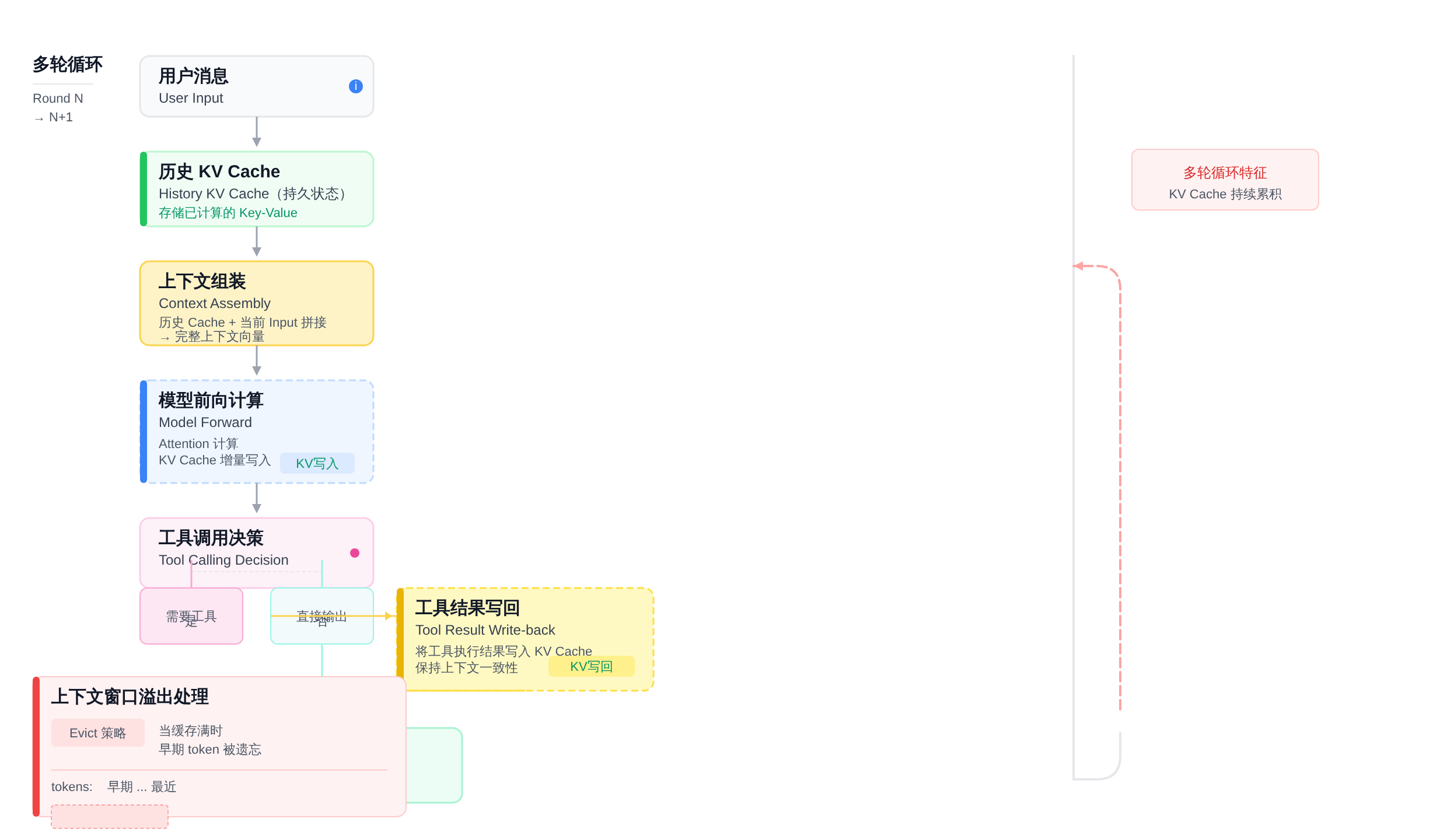
Agent 系统(ReAct、Tool Calling、Multi-turn Conversation)对 Transformer 的使用和普通 LLM 有本质区别:Agent 需要在多轮推理循环里反复维护和更新 KV Cache。 这带来了几个普通 LLM 部署不会碰到的工程问题:
正文图解 5
第一,工具调用结果的上下文一致性。 当 Agent 调用外部工具(搜索、数据库、代码执行)后,工具返回结果需要作为新的 token 追加进 KV Cache。
这一步在实现上不是简单的 append——工具结果必须经过和模型输入相同的 tokenize 和 embedding 流程,才能保证 Attention 机制感知到完整的上下文。
很多候选人在这一步会出错:直接把工具返回的文本字符串拼接进去,没有做 token 对齐,导致模型在后续推理时出现"看不见工具结果"的幻觉。
第二,KV Cache 的 Evict 策略。 当上下文窗口接近上限时(比如 32K token),Agent 不能简单地截断最新的 token(因为最新 token 往往是关键推理结果),而是需要一套 eviction 策略:通常优先丢弃最早期、最不重要的历史 token——比如用户已经确认过的中间推理步骤,或者已经被工具调用消耗掉的历史信息。
Mistral 的做法是引入一个滑动窗口 Attention,只保留最近 N 个 token 的完整 KV Cache,更早的 token 通过压缩或降采样处理。
这套机制在大模型推理框架(vLLM、TGI)里已经工程化实现,但理解它的原理是面试里的加分项。
第三,并发与流式输出的权衡。 Agent 服务通常需要流式输出(streaming)来让用户感知"模型在思考"。
但流式输出和 KV Cache 的关系是微妙的:如果每个 token 都立即写出并释放显存,KV Cache 无法累积,上下文会退化;如果等整轮结束再写,响应延迟会让用户体验很差。
工程上通常的做法是 micro-batch KV Cache 管理 :每隔 N 个 token 做一次 checkpoint,兼顾延迟和显存。
真实项目表达:怎么把 Transformer 原理说成自己的
面试里有一条隐藏的筛选线:候选人能不能用自己的语言描述自己做过的项目,而不只是背诵教科书概念。
举一个具体的对比。
不过关的回答(背书型):
"我们用了 Transformer 架构的 attention 机制来做语义匹配,通过多头注意力捕捉不同子空间的关系,然后用了 GQA 来降低显存占用。"
这段话正确,但没有任何项目特异性——任何一个看过这篇文章的人都能说出同样的话。
过关的回答(项目型):
"我们做的是一个 RAG + Agent 的客服场景,核心问题是用户 query 和知识库文档的语义匹配。当时调研了三个方案:BM25、Sentence-BERT 和基于 LLaMA 的向量召回。BM25 在短 query 下效果还行,但处理多跳问题(比如'去年Q3收入同比增长了多少')时召回率只有 40% 左右。Sentence-BERT 能到 68%,但我们发现它对表格类知识(比如年报里的数字)的表示不够好,表格结构信息丢失严重。
最后我们选了 LLaMA-7B 做向量召回 backbone,理由是 LLaMA-7B 在金融语料上做继续预训练后,对数字和表格的表示比纯文本预训练的模型更稳定。Attention 维度我们配了 32 个 Q head 和 8 个 KV head(GQA),因为这个场景下单轮 query 长度不超过 2K token,KV Cache 不是主要瓶颈,但 8:1 的分组比例让我们把单卡显存占用从 14GB 压到了 9GB,可以多跑两个并发实例。"
这个回答里,每一个决策(为什么选 LLaMA、为什么是 7B 而不是 13B、为什么 Q/K/V head 这么配)都有业务约束在背后——不是随机选参数,是有取舍权衡的。
面试官问到这里,通常会接着追问"13B 模型你们测过吗,效果差距有多大",这是一个把项目说透的绝佳机会。

面试官想听的不是"我用了 transformer",而是"我在约束下做了什么权衡"
面试追问:项目表达里的高频陷阱
在 Transformer 相关的项目问题里,有几个被问穿的频率极高,列在这里做预防性覆盖:
追问一:"Attention 的 O(n²) 复杂度你们怎么处理的?"
标准答案路径:先说 Flash Attention(通过分块计算把 O(n²) 的显存占用压到 O(n)),再说切片窗口注意力(Sliding Window Attention,用于长上下文场景),最后说实际业务里有没有用到这些优化,以及效果数据。
追问二:"你们模型部署在什么硬件上,如何利用 GPU 的?"
这个问题背后是在考候选人有无实际的推理工程经验。
好的答案会提到 Tensor Parallelism(张量并行,把模型参数切分到多卡)、Pipeline Parallelism(流水线并行,按层切分)、以及 continuous batching(动态批处理,提高 GPU 利用率)。
追问三:"RoPE 和 ALiBi 你们了解吗,为什么用 RoPE?"
这个问题在第五章已经有充分展开,面试里只需要简洁地说:"RoPE 支持任意长度外推,训练时用 4K token,微调后可以直接推理 32K,不需要重新训练整个模型。
这对于我们快速验证长上下文效果很关键。"
能把"快速验证"和"不需要重新训练"这两个工程收益说出来,说明你真正用过 RoPE。
追问四:"LayerNorm 放在 Pre-LN 还是 Post-LN,为什么?"
第五章的 Pre-LN vs Post-LN 部分已经覆盖了理论层面,项目表达里只需要加一句:"我们用的是 Pre-LN,没遇到训练不稳定的问题;
如果你们要用 Post-LN,需要特别小心 warm-up 阶段的学习率设置。"——这句话直接把理论问题和工程经验接起来了。
模型选型与监控指标:工程表达的最后一块拼图
面试里还有一个高频问题区:"你们线上模型效果怎么监控?" 这类问题看似偏运维,但其实考察的是候选人有没有端到端的工程视野。
Transformer 推理服务的核心监控指标通常分三层:
延迟层(Latency)。 第一个 token 的生成时间(Time to First Token,TTFT)和每个 token 的平均生成时间(Time Per Token,TPT)是关键指标。
通常用 P50/P95/P99 分位数来描述,而不是平均值——因为 GPU 并发可能导致少数请求特别慢,平均值会被拉偏。
吞吐层(Throughput)。 每秒生成的 token 数(Tokens Per Second,TPS)是服务吞吐的直接度量。
影响 TPS 的因素包括:batch size(越大 TPS 越高,但延迟也越高)、KV Cache 显存占用(决定能同时服务的请求数)、以及是否用了 KV Cache 复用(prefix caching,相同 system prompt 的请求可以共享 KV Cache,大幅提升吞吐)。
效果层(Quality)。 这里不是指模型 loss,而是业务指标:RAG 场景下的召回准确率、Tool Calling 成功率、多轮对话的上下文保持率。
这些指标需要和模型指标(perplexity、 Rouge)区分开——业务指标才是最终衡量标准。
面试里说到监控,通常最后会落到"发现了什么问题,怎么解决的"。
一个好的收尾案例是:"我们发现凌晨流量低峰期 TPS 反而下降,最后定位到是连续批处理的 padding token 浪费了大量计算资源——高峰期 16 个请求 batch 在一起,实际有效 token 只有 40%,凌晨 4 个请求反而 padding 到了 8 个,空跑了一半算力。
优化了 batch 调度策略之后,TPS 提升了 30%。"
这个例子好在哪里?它展示了候选人不仅会用模型,还能发现和解决推理服务里的真实效率问题——这比"我调过学习率和 batch size"高出一个层次。
优化完 batch 调度,TPS 涨了 30%,这事值得写进简历
典型追问与易错边界
面试里有一类追问,表面上是技术细节,实际上是在测试候选人有没有真正穿过「会用」到「理解」的边界。以下四个方向的被追问频率最高,每一个都值得提前想清楚自己会怎么答。
MQA 和 GQA 的本质区别:不是分组数量,是信息流差异
被问到「MQA 和 GQA 有什么区别」,很多人会说「MQA 只有一个 KV head,GQA 有多个 KV head」——这没有错,但只回答了表象,没有回答面试官真正想知道的东西1。
两者的核心差异在于 Query 到 Key/Value 的映射关系 ,以及这个映射关系对模型表达能力的约束。
MQA 里,所有 Q head 共享同一对 K head 和 V head。这意味着什么呢?
意味着「谁应该关注谁」这个注意力模式,对于所有 Query 是完全相同的——不同 Q head 只能学到不同的「查询方向」,但无法学到「不同的注意力偏好」。
当模型需要同时追踪多种类型的依赖关系时(比如一个 head 关注句法结构、另一个 head 关注语义相似度),MQA 的单一 KV head 就成了表达力的硬性天花板2。
GQA 通过分组共享解决了这个问题。假设有 32 个 Q head,分成 8 组,每组 4 个 Q head 共享一对 KV head。
同一组内的 Q head 注意力模式仍然受限,但不同组之间可以学到不同的 KV 关联方式。
这就是在 MHA 的表达力和 MQA 的效率之间的真实折中——分组粒度越细,表达力越接近 MHA,但显存收益也越小。
面试里被追问「你们组的 GQA 为什么选 N 个 KV head」,好的答案框架是:先说业务场景(是高并发还是长上下文),再说显存约束(单卡还是多卡),最后给出具体数字和结果("配置成 8 个 KV head 之后,单请求显存降低了 60%,吞吐量提升了 2.3 倍")。
有具体数字的答案和没有数字的答案,在面试官那里的分量差距极大。
背景:GQA 真的帮我们省了不少显存,不是简历上随便写的
RoPE 的核心优势:位置编码为什么不能只「记住位置」
RoPE 相关的追问通常分两层:第一层是「RoPE 怎么工作的」(第五章已有充分展开),第二层是「为什么你们选 RoPE 而不是 Sinusoidal 或 ALiBi」。
后者才是真正有区分度的问题。一个容易踩的坑是把 RoPE 理解成「一种新的位置编码方式」,然后就开始讲旋转矩阵的数学推导——推导没问题,但推完之后说不清楚「好在哪里」,就暴露了对原理的浅层理解。
RoPE 的核心优势有两层工程语言:
第一,支持任意长度外推。 训练时用 4K token,微调后可以直接推理 32K,不需要重新训练整个模型。这对于需要快速验证长上下文效果的业务场景是关键收益。****
第二,自然融合相对位置信息。 Sinusoidal 编码把绝对位置直接加到 token embedding 里,位置信息是「记住」的;
RoPE 通过旋转操作把位置信息注入 Q/K 的内积结果里,Attention 天然感知的是「相对距离」而非「绝对编号」。
这意味着无论上下文多长,模型学到的是「当前 token 应该关注多远的 token」,而不是「第 N 个位置应该关注第 M 个位置」。
面试里能说出「快速验证 + 不需要重新训练」这两个工程收益,比能把旋转矩阵写出来更重要——后者是能查到的知识,前者是真正用过的判断。

把旋转矩阵背出来但说不清「好在哪里」,面试官一眼就知道是背的
KV Cache 显存估算:面试里的数字题怎么过
KV Cache 相关的追问里,有一道经典的数字估算题出现的频率极高:「LLaMA-7B 在 BF16 精度下跑 2K 上下文,单个请求的 KV Cache 是多少 GB?」
这道题不需要死记硬背,有一套可以在面试现场推导的逻辑。KV Cache 的显存由以下参数决定:KV head 数、每个 head 的维度、序列长度、batch size、精度和层数。
LLaMA-7B 的关键参数:32 个 Q head(但用 GQA 通常配 8 个 KV head),每个 head 维度 128,层数 32。
单个 token 的 K 和 V 各占 num_kv_heads × head_dim × 4 bytes(BF16 精度,每个浮点数 2 bytes)。
# 简化公式:单个 token 的 KV Cache 显存(GB)
def kv_cache_per_token_gb(num_kv_heads, head_dim, num_layers, precision=16):
bytes_per_float = 2 if precision == 16 else 4
bytes_per_token = 2 * num_kv_heads * head_dim * bytes_per_float # K + V
total_bytes = bytes_per_token * num_layers
return total_bytes / (1024 ** 3)
# LLaMA-7B,8 个 KV head,BF16:
# 每个 token 的 KV Cache = 2 × 8 × 128 × 2 bytes ≈ 4 KB
# 32 层 × 4 KB = 128 KB/token
# 2K token × 128 KB = 256 MB(单请求,不含模型参数)
print(kv_cache_per_token_gb(8, 128, 32)) # ≈ 0.[REDACTED] GB ≈ 119 MB
# 2048 tokens: 2048 * 128 * 1024 / (1024**3) ≈ 0.244 GB ≈ 250 MB
模型参数本身在 BF16 下约 14 GB。
KV Cache 在这个场景里相对较小,但如果把上下文扩展到 32K、batch size 扩大到 64 并发,KV Cache 显存就会成为主要瓶颈——64 并发 × 32K × 128 KB ≈ 256 GB,光是 KV Cache 就超过了单卡显存上限。
面试里与其背答案,不如用具体数字说清楚「什么场景下 KV Cache 是瓶颈」:短序列 + 小 batch 时不是问题;长序列 + 大 batch 时显存占用会超过模型参数本身。

算完才发现单请求 KV Cache 250MB,64 并发直接爆显存
LayerNorm 位置:Pre-LN 为什么是工程上的默认选择
这个问题在第五章从理论层面已经覆盖了「Pre-LN 更好训练」的原因,但面试里更常见的追问是:「你们项目里用的是 Pre-LN 还是 Post-LN?为什么?」
这道题背后的筛选逻辑是:面试官想知道候选人有没有真正在代码层面见过这两种配置的差异,而不只是从论文里读到了结论。
工程上的差异可以简洁地说三句:Pre-LN 把 LayerNorm 放到残差分支外面,梯度路径更直接,深层网络更容易训练收敛,不需要复杂的 warm-up 学习率调度;
Post-LN 的 LayerNorm 放在残差累加之后,表达力理论上更强,但训练过程对学习率极其敏感,70 层以上的 Transformer 几乎无法稳定训练;
GPT-2、LLaMA、PaLM 这些现代 LLMA 架构无一例外都选了 Pre-LN,原因不是理论上的偏好,是工程上的不可行——Post-LN 在这个规模下根本跑不起来。
一个能让面试官眼前一亮的回答是:把这个选择和自己的项目经验接起来,比如说「我们当时用的是 Pre-LN,训练 13B 参数的模型没有遇到明显不稳定问题;
如果用 Post-LN,按照我们的实验经验需要额外的 warm-up 阶段,训练时间会多出约 15%。」

知道 Pre-LN 好,但说不出和 Post-LN 的实际训练差异,就还是没过关
Agent 工作流主链路
这张图把抽象工作流压成一条可复盘的链路,方便读者定位风险点。
总结:用一条主线回答 Transformer 核心结构
从头读到这里,你应该已经对 Transformer 的骨架有了一个相对完整的认知。临考前最后过一遍,这条主线的核心节点是这样的:
Attention 是骨架的心脏。 它不是「记住」信息,而是「选择性地路由」信息——每个 token 通过 Query 询问自己需要什么,通过 Key 判断其他 token 的相关性,通过 Value 提取实际内容。
Softmax 权重决定了「关注程度」,这个权重矩阵就是模型学到的「关系知识」。
MHA → MQA → GQA 是一条工程取舍的进化链。 MHA 追求极致表达力,但 KV Cache 在推理时成了显存瓶颈;
MQA 通过 KV head 共享把显存压到最低,但牺牲了不同注意力模式的学习空间;GQA 在两者之间找到了分组粒度的平衡点——分组越细,表达力越接近 MHA,显存收益也越小。
这条进化链背后的驱动力是真实的推理成本,不是学术上的兴趣驱动。
RoPE 是位置编码工程的拐点。 它把相对位置信息自然注入 Attention 的内积结果里,而不是简单地在 embedding 上加一个位置信号。
这带来了两个关键工程收益:支持长度外推(不需要为更长上下文重新训练),以及更自然的相对位置建模。LayerNorm 和残差连接是深度的基础设施。 没有残差连接,70 层以上的梯度传播几乎不可能稳定;没有 LayerNorm,数值溢出和梯度消失会在前向过程中迅速积累。
这两个组件把「训练深度 Transformer」从不可行变成了标准工程。

面试官想听的不是公式,是「我在约束下做了什么权衡」
最后留一个问题给你:
如果面试官让你从头设计一个针对长文档摘要场景的 Transformer 结构——上下文 128K,主要瓶颈是显存和首 token 延迟,你会怎么配置 Q head 数、KV head 数、位置编码方式和 LayerNorm 位置?
把你的配置和理由写下来,这就是 Transformer 核心结构最接近真实工程判断的一次练习。
欢迎在评论区说说你的配置思路,以及有没有被面试追问卡住过的 Transformer 问题。
参考文献

如果浏览器无法直接唤起微信,可在微信内打开公众号主页:计算机魔术师